aai530-group6/ddxplus
收藏Hugging Face2024-01-22 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/aai530-group6/ddxplus
下载链接
链接失效反馈官方服务:
资源简介:
---
language:
- en
license: cc-by-4.0
license_link: https://creativecommons.org/licenses/by/4.0/
tags:
- automatic-diagnosis
- automatic-symptom-detection
- differential-diagnosis
- synthetic-patients
- diseases
- health-care
pretty_name: DDXPlus
size_categories:
- 1K<n<10K
source_datasets:
- original
task_categories:
- tabular-classification
task_ids:
- multi-class-classification
paperswithcode_id: ddxplus
configs:
- config_name: default
data_files:
- split: train
path: "train.csv"
- split: test
path: "test.csv"
- split: validate
path: "validate.csv"
extra_gated_prompt: "By accessing this dataset, you agree to use it solely for research purposes and not for clinical decision-making."
extra_gated_fields:
Consent: checkbox
Purpose of use:
type: select
options:
- Research
- Educational
- label: Other
value: other
train-eval-index:
- config: default
task: medical-diagnosis
task_id: binary-classification
splits:
train_split: train
eval_split: validate
col_mapping:
AGE: AGE
SEX: SEX
PATHOLOGY: PATHOLOGY
EVIDENCES: EVIDENCES
INITIAL_EVIDENCE: INITIAL_EVIDENCE
DIFFERENTIAL_DIAGNOSIS: DIFFERENTIAL_DIAGNOSIS
metrics:
- type: accuracy
name: Accuracy
- type: f1
name: F1 Score
---
# Dataset Description
We are releasing under the CC-BY licence a new large-scale dataset for Automatic Symptom Detection (ASD) and Automatic Diagnosis (AD) systems in the medical domain. The dataset contains patients synthesized using a proprietary medical knowledge base and a commercial rule-based AD system. Patients in the dataset are characterized by their socio-demographic data, a pathology they are suffering from, a set of symptoms and antecedents related to this pathology, and a differential diagnosis. The symptoms and antecedents can be binary, categorical and multi-choice, with the potential of leading to more efficient and natural interactions between ASD/AD systems and patients. To the best of our knowledge, this is the first large-scale dataset that includes the differential diagnosis, and non-binary symptoms and antecedents.
**Note**: We use evidence as a general term to refer to a symptom or an antecedent.
This directory contains the following files:
- **release_evidences.json**: a JSON file describing all possible evidences considered in the dataset.
- **release_conditions.json**: a JSON file describing all pathologies considered in the dataset.
- **release_train_patients.zip**: a CSV file containing the patients of the training set.
- **release_validate_patients.zip**: a CSV file containing the patients of the validation set.
- **release_test_patients.zip**: a CSV file containing the patients of the test set.
## Evidence Description
Each evidence in the `release_evidences.json` file is described using the following entries:
- **name**: name of the evidence.
- **code_question**: a code allowing to identify which evidences are related. Evidences having the same `code_question` form a group of related symptoms. The value of the `code_question` refers to the evidence that need to be simulated/activated for the other members of the group to be eventually simulated.
- **question_fr**: the query, in French, associated to the evidence.
- **question_en**: the query, in English, associated to the evidence.
- **is_antecedent**: a flag indicating whether the evidence is an antecedent or a symptom.
- **data_type**: the type of evidence. We use `B` for binary, `C` for categorical, and `M` for multi-choice evidences.
- **default_value**: the default value of the evidence. If this value is used to characterize the evidence, then it is as if the evidence was not synthesized.
- **possible-values**: the possible values for the evidences. Only valid for categorical and multi-choice evidences.
- **value_meaning**: The meaning, in French and English, of each code that is part of the `possible-values` field. Only valid for categorical and multi-choice evidences.
## Pathology Description
The file `release_conditions.json` contains information about the pathologies that patients in the datasets may suffer from. Each pathology has the following attributes:
- **condition_name**: name of the pathology.
- **cond-name-fr**: name of the pathology in French.
- **cond-name-eng**: name of the pathology in English.
- **icd10-id**: ICD-10 code of the pathology.
- **severity**: the severity associated with the pathology. The lower the more severe.
- **symptoms**: data structure describing the set of symptoms characterizing the pathology. Each symptom is represented by its corresponding `name` entry in the `release_evidences.json` file.
- **antecedents**: data structure describing the set of antecedents characterizing the pathology. Each antecedent is represented by its corresponding `name` entry in the `release_evidences.json` file.
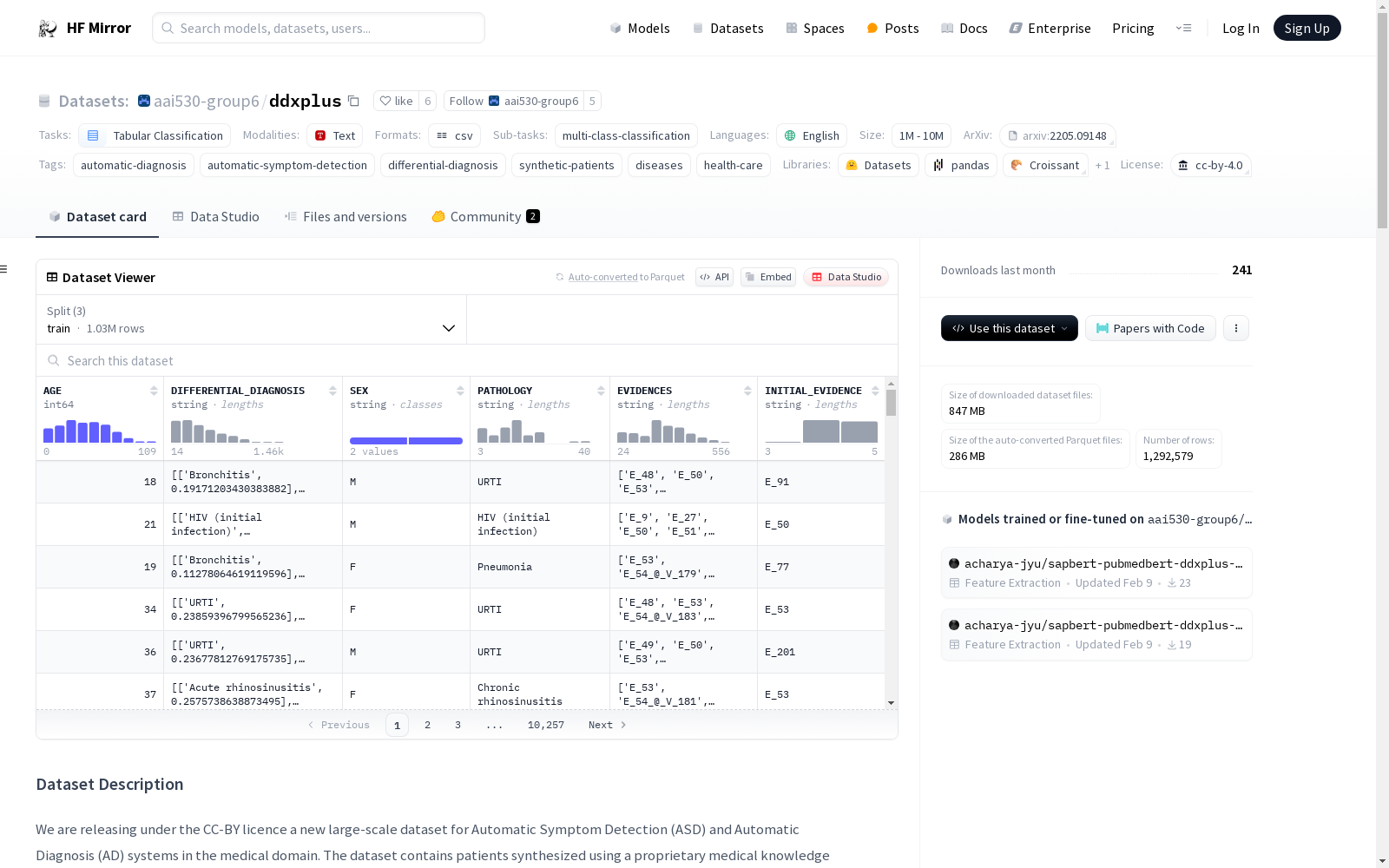
## Patient Description
Each patient in each of the 3 sets has the following attributes:
- **AGE**: the age of the synthesized patient.
- **SEX**: the sex of the synthesized patient.
- **PATHOLOGY**: name of the ground truth pathology (`condition_name` property in the `release_conditions.json` file) that the synthesized patient is suffering from.
- **EVIDENCES**: list of evidences experienced by the patient. An evidence can either be binary, categorical or multi-choice. A categorical or multi-choice evidence is represented in the format `[evidence-name]_@_[evidence-value]` where [`evidence-name`] is the name of the evidence (`name` entry in the `release_evidences.json` file) and [`evidence-value`] is a value from the `possible-values` entry. Note that for a multi-choice evidence, it is possible to have several `[evidence-name]_@_[evidence-value]` items in the evidence list, with each item being associated with a different evidence value. A binary evidence is represented as `[evidence-name]`.
- **INITIAL_EVIDENCE**: the evidence provided by the patient to kick-start an interaction with an ASD/AD system. This is useful during model evaluation for a fair comparison of ASD/AD systems as they will all begin an interaction with a given patient from the same starting point. The initial evidence is randomly selected from the binary evidences found in the evidence list mentioned above (i.e., `EVIDENCES`) and it is part of this list.
- **DIFFERENTIAL_DIAGNOSIS**: The ground truth differential diagnosis for the patient. It is represented as a list of pairs of the form `[[patho_1, proba_1], [patho_2, proba_2], ...]` where `patho_i` is the pathology name (`condition_name` entry in the `release_conditions.json` file) and `proba_i` is its related probability.
## Note:
We hope this dataset will encourage future works for ASD and AD systems that consider the differential diagnosis and the severity of pathologies. It is important to keep in mind that this dataset is formed of synthetic patients and is meant for research purposes. Given the assumptions made during the generation process of this dataset, we would like to emphasize that the dataset should not be used to train and deploy a model prior to performing rigorous evaluations of the model performance and verifying that the system has proper coverage and representation of the population that it will interact with.
It is important to understand that the level of specificity, sensitivity and confidence that a physician will seek when evaluating a patient will be influenced by the clinical setting. The dataset was built for acute care and biased toward high mortality and morbidity pathologies. Physicians will tend to consider negative evidences as equally important in such a clinical context in order to evaluate high acuity diseases.
In the creation of the DDXPlus dataset, a small subset of the diseases was chosen to establish a baseline. Medical professionals have to consider this very important point when reviewing the results of models trained with this dataset, as the differential is considerably smaller. A smaller differential means less potential evidences to collect. It is thus essential to understand this point when we look at the differential produced and the evidence collected by a model based on this dataset.
For more information, please check our [paper](https://arxiv.org/abs/2205.09148).
### 数据集元信息
语言:英语
许可协议:知识共享署名4.0(CC BY 4.0)
许可链接:https://creativecommons.org/licenses/by/4.0/
标签:自动诊断、自动症状检测、鉴别诊断、合成患者、疾病、医疗保健
展示名称:DDXPlus
规模类别:1000 < n < 10000
源数据集:原创数据集
任务类别:表格分类
任务子类型:多分类
PapersWithCode ID:ddxplus
配置项:
- 配置名称:default
数据文件:
- 拆分:训练集,路径:train.csv
- 拆分:测试集,路径:test.csv
- 拆分:验证集,路径:validate.csv
额外访问提示:"访问本数据集即表示同意仅将其用于研究目的,不得用于临床决策。"
额外访问字段:
同意:复选框
使用目的:
类型:下拉选择
选项:
- 研究
- 教育
- 其他(值:other)
训练评估索引:
- 配置:default
任务:医疗诊断
任务子类型:二分类
拆分:
训练拆分:train
评估拆分:validate
列映射:
AGE: AGE
SEX: SEX
PATHOLOGY: PATHOLOGY
EVIDENCES: EVIDENCES
INITIAL_EVIDENCE: INITIAL_EVIDENCE
DIFFERENTIAL_DIAGNOSIS: DIFFERENTIAL_DIAGNOSIS
评估指标:
- 类型:准确率,名称:Accuracy
- 类型:F1值,名称:F1 Score
---
# 数据集说明
我们基于CC-BY许可发布了一款面向医疗领域自动症状检测(Automatic Symptom Detection, ASD)与自动诊断(Automatic Diagnosis, AD)系统的新型大规模数据集。本数据集采用专有医学知识库与商用基于规则的AD系统合成生成患者数据。数据集中的患者以社会人口统计学特征、所患疾病、与该疾病相关的症状及既往病史集合,以及鉴别诊断结果为核心特征。症状与既往病史可分为二分类、分类与多选三类,有望实现ASD/AD系统与患者之间更高效自然的交互。据我们所知,这是首个包含鉴别诊断、非二分类症状与既往病史的大规模数据集。
**注**:本数据集统一使用“证据(evidence)”一词指代症状或既往病史。
本目录包含以下文件:
- **release_evidences.json**:描述数据集中所有可用证据的JSON文件。
- **release_conditions.json**:描述数据集中所有疾病的JSON文件。
- **release_train_patients.zip**:包含训练集患者数据的CSV文件。
- **release_validate_patients.zip**:包含验证集患者数据的CSV文件。
- **release_test_patients.zip**:包含测试集患者数据的CSV文件。
## 证据说明
`release_evidences.json`文件中的每条证据包含以下字段:
- **name**:证据名称。
- **code_question**:用于标识关联证据的编码。拥有相同`code_question`的证据构成一组相关症状。`code_question`的值指向需优先模拟/激活的证据,以触发组内其他证据的模拟。
- **question_fr**:该证据对应的法语查询语句。
- **question_en**:该证据对应的英语查询语句。
- **is_antecedent**:标识该证据是否为既往病史的布尔标记。
- **data_type**:证据类型。其中`B`代表二分类证据,`C`代表分类证据,`M`代表多选证据。
- **default_value**:证据的默认值。若使用该值表征证据,则等同于未合成该证据。
- **possible-values**:证据的可选取值范围,仅适用于分类与多选证据。
- **value_meaning**:`possible-values`字段中各编码的法、英语义项,仅适用于分类与多选证据。
## 疾病说明
`release_conditions.json`文件包含数据集中患者可能罹患的疾病信息。每种疾病包含以下属性:
- **condition_name**:疾病名称。
- **cond-name-fr**:疾病的法语名称。
- **cond-name-eng**:疾病的英语名称。
- **icd10-id**:该疾病的ICD-10编码。
- **severity**:疾病的严重程度评分,分值越低代表病情越严重。
- **symptoms**:描述该疾病特征性症状的数据结构。每条症状以其在`release_evidences.json`文件中的`name`字段值表示。
- **antecedents**:描述该疾病特征性既往病史的数据结构。每条既往病史以其在`release_evidences.json`文件中的`name`字段值表示。
## 患者说明
三个数据集中的每位患者均包含以下属性:
- **AGE**:合成患者的年龄。
- **SEX**:合成患者的性别。
- **PATHOLOGY**:合成患者所患真实疾病的名称(对应`release_conditions.json`文件中的`condition_name`属性)。
- **EVIDENCES**:患者出现的证据列表。证据可分为二分类、分类与多选类型。分类或多选证据采用`[证据名称]_@_[证据取值]`的格式表示,其中`[证据名称]`为该证据在`release_evidences.json`文件中的`name`字段值,`[证据取值]`为`possible-values`字段中的可选值。需注意,对于多选证据,证据列表中可包含多个`[证据名称]_@_[证据取值]`项,每项对应不同的证据取值。二分类证据直接以`[证据名称]`表示。
- **INITIAL_EVIDENCE**:患者提供的用于启动与ASD/AD系统交互的初始证据。该字段可用于模型评估阶段,确保所有ASD/AD系统均从同一初始起点与患者交互,实现公平对比。初始证据从上述`EVIDENCES`列表中的二分类证据中随机选取,且必为该列表中的成员。
- **DIFFERENTIAL_DIAGNOSIS**:患者的真实鉴别诊断结果。采用`[[疾病1, 概率1], [疾病2, 概率2], ...]`的列表对形式表示,其中`patho_i`为疾病名称(对应`release_conditions.json`文件中的`condition_name`字段),`proba_i`为对应的概率值。
## 补充说明
我们期望本数据集能够推动针对兼顾鉴别诊断与疾病严重程度的ASD与AD系统的后续研究。需牢记的是,本数据集由合成患者构成,仅用于研究目的。鉴于数据集生成过程中所做的各项假设,我们强调:在对模型性能进行严格评估、并验证系统覆盖并充分表征其将交互的人群特征之前,不得使用本数据集训练并部署模型。
需理解的是,医师在评估患者时所需的特异性、敏感性与置信度水平会受临床场景影响。本数据集面向急诊医疗场景构建,偏向高死亡率与高发病率的疾病。在这类临床场景中,医师通常会将阴性证据与阳性证据同等看待,以评估高优先级疾病。
在DDXPlus数据集的构建过程中,仅选取了一小部分疾病作为基准。使用本数据集训练的模型在评估结果时,医疗专业人员必须考虑这一关键要点:由于基准疾病子集的鉴别诊断范围较小,可收集的潜在证据数量也相应更少。因此,在分析模型生成的鉴别诊断结果与收集到的证据时,理解这一点至关重要。
如需了解更多信息,请查阅我们的[论文](https://arxiv.org/abs/2205.09148)。
提供机构:
aai530-group6
原始信息汇总
数据集概述
基本信息
- 语言: 英语
- 许可证: CC-BY 4.0
- 标签: 自动诊断, 自动症状检测, 鉴别诊断, 合成患者, 疾病, 医疗保健
- 数据集名称: DDXPlus
- 数据集大小: 1K<n<10K
- 数据来源: 原始数据
- 任务类别: 表格分类
- 任务ID: 多类分类
配置信息
- 配置名称: default
- 数据文件:
- 训练集: train.csv
- 测试集: test.csv
- 验证集: validate.csv
额外要求
- 访问条件: 仅用于研究目的,不用于临床决策。
- 字段:
- 同意: 勾选框
- 使用目的: 选择框 (研究, 教育, 其他)
训练与评估
- 配置: default
- 任务: 医疗诊断
- 任务ID: 二元分类
- 分割:
- 训练集: train
- 验证集: validate
- 列映射:
- AGE: 年龄
- SEX: 性别
- PATHOLOGY: 病理
- EVIDENCES: 证据
- INITIAL_EVIDENCE: 初始证据
- DIFFERENTIAL_DIAGNOSIS: 鉴别诊断
- 评估指标:
- 准确率: Accuracy
- F1分数: F1 Score
数据集描述
- 内容: 包含使用专有医学知识库和商业规则基础的自动诊断系统合成的患者数据。患者特征包括社会人口统计数据、病理、相关症状和先兆以及鉴别诊断。
- 证据: 症状或先兆的通用术语。
文件描述
- release_evidences.json: 描述数据集中所有可能的证据。
- release_conditions.json: 描述数据集中所有病理。
- release_train_patients.zip: 包含训练集患者的CSV文件。
- release_validate_patients.zip: 包含验证集患者的CSV文件。
- release_test_patients.zip: 包含测试集患者的CSV文件。
证据描述
- 字段:
- name: 证据名称
- code_question: 相关证据的代码
- question_fr: 法语查询
- question_en: 英语查询
- is_antecedent: 是否为先兆
- data_type: 证据类型 (B: 二元, C: 分类, M: 多选)
- default_value: 默认值
- possible-values: 可能值
- value_meaning: 值的含义
病理描述
- 字段:
- condition_name: 病理名称
- cond-name-fr: 法语病理名称
- cond-name-eng: 英语病理名称
- icd10-id: ICD-10代码
- severity: 严重程度
- symptoms: 症状
- antecedents: 先兆
患者描述
- 字段:
- AGE: 年龄
- SEX: 性别
- PATHOLOGY: 病理
- EVIDENCES: 证据
- INITIAL_EVIDENCE: 初始证据
- DIFFERENTIAL_DIAGNOSIS: 鉴别诊断
注意事项
- 数据集包含合成患者,仅用于研究目的。
- 在使用数据集训练和部署模型之前,需要进行严格的模型性能评估和验证。
- 数据集偏向于高死亡率和发病率的病理。
搜集汇总
数据集介绍
构建方式
DDXPlus数据集的构建基于专有的医疗知识库和商业规则为基础的诊断系统,通过合成患者信息的方式生成。该数据集整合了患者的社会人口学数据、患病病理学、与病理学相关的症状和病史,以及鉴别诊断信息。这一构建过程旨在模拟真实医疗环境中的患者情况,为自动症状检测和自动诊断系统提供训练和评估的基础。
使用方法
使用DDXPlus数据集时,研究人员需遵守Creative Commons BY 4.0许可协议。数据集提供了训练集、验证集和测试集,分别以CSV格式存储在压缩文件中。用户需解压文件后,根据数据集中的证据描述、病理学描述和患者描述等文档进行数据读取和分析。数据集适用于自动症状检测和自动诊断系统的研发和评估,但需注意,该数据集为合成数据,仅供研究使用,不应直接用于临床决策。
背景与挑战
背景概述
DDXPlus数据集是在医学领域自动症状检测与自动诊断系统的研究背景下诞生的。该数据集由合成患者构成,这些患者是基于专有医学知识库和商业规则基础诊断系统生成的。每个患者具有人口统计信息、所患疾病、与疾病相关的症状和前兆,以及鉴别诊断。该数据集是首个包含鉴别诊断和非二元症状与前兆的大规模数据集,其发布旨在推动自动症状检测与自动诊断系统的研究进展,并已获得Creative Commons BY 4.0许可证的授权。DDXPlus数据集的创建,为医学诊断领域提供了一个全新的研究资源,对于提升相关系统的交互效率和自然性具有重大意义。
当前挑战
DDXPlus数据集在构建过程中面临的挑战包括:确保合成患者的真实性和代表性,同时涵盖广泛的症状和前兆;在数据集中平衡疾病严重性和死亡率;以及处理鉴别诊断中疾病范围的限制问题。此外,数据集在应用研究中面临的挑战包括:如何有效利用鉴别诊断信息进行多类别分类任务,以及如何在模型训练和评估中考虑到临床环境中的特异性、敏感性和置信度要求。这些挑战对于研究人员来说既是机遇也是考验,需要他们在研究和应用中不断探索和优化。
常用场景
经典使用场景
在医学领域中,DDXPlus数据集的典型应用场景在于构建自动症状检测(ASD)和自动诊断(AD)系统。该数据集通过模拟患者的社会人口数据、患病情况、相关症状和病史以及鉴别诊断,为研究者提供了丰富的信息资源,以训练模型从而实现从患者数据中自动识别症状并做出初步诊断。
解决学术问题
DDXPlus数据集解决了传统诊断系统中缺乏全面鉴别诊断信息的问题,它提供了包含非二元症状和病史的数据,这对于提升诊断系统的准确性和效率至关重要。此外,该数据集为研究提供了包含不同严重程度疾病的数据,有助于学术研究中对疾病严重性和症状之间关系的探索。
实际应用
在实际应用中,DDXPlus数据集可用于开发和评估面向急性护理场景的诊断系统,特别是在处理高死亡率和高发病率疾病时。该数据集有助于提高医疗系统对急性疾病的响应速度和准确性,从而改善患者的治疗效果和生存率。
数据集最近研究
最新研究方向
DDXPlus数据集为医学领域内的自动症状检测与自动诊断系统提供了大规模的训练资源,其特色在于包含了差异诊断及非二元症状与先兆。近期研究聚焦于利用该数据集提升诊断模型的准确性与特异性,特别是在处理急性病痛与高死亡率病症时。该数据集促使研究者们探索更深入的模型架构,以及更精确的症状与差异诊断之间的关系,以期提高模型的临床适用性,为未来的医疗决策提供有力支持。
以上内容由遇见数据集搜集并总结生成


