Grounded-RAG-RU-v2
收藏Hugging Face2024-08-06 更新2024-12-12 收录
下载链接:
https://huggingface.co/datasets/Vikhrmodels/Grounded-RAG-RU-v2
下载链接
链接失效反馈官方服务:
资源简介:
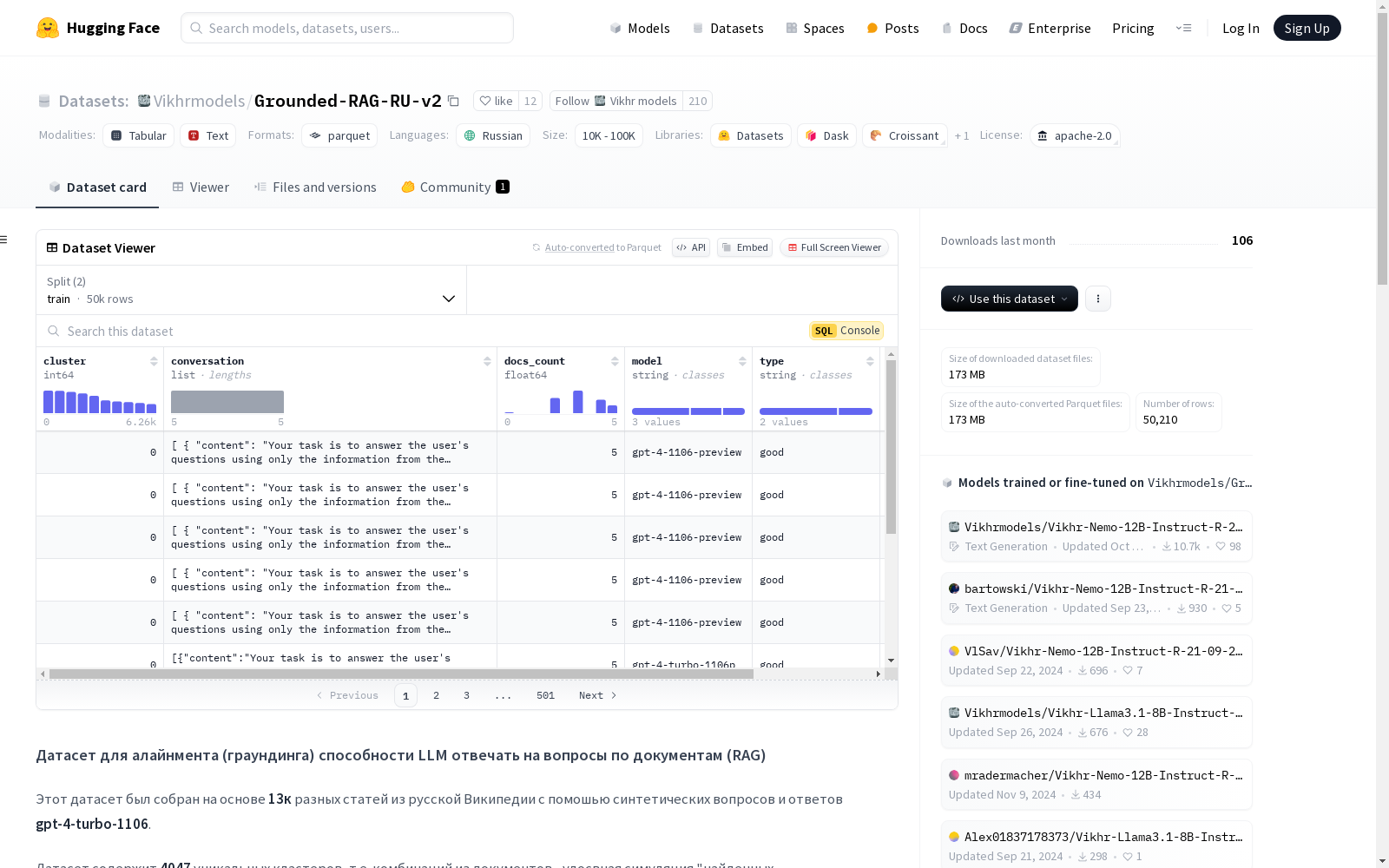
数据集是为训练大型语言模型(LLM)的接地(grounding)能力而设计的,特别是针对基于文档的问答系统(RAG)。数据集包含了从俄语维基百科的13,000篇文章中提取的内容,通过合成的问题和答案生成。数据集包含4047个独特的集群,每个集群代表一组文档的组合,模拟检索系统中的“找到的结果”。数据集总共有50,210个独特的对话。对话以HuggingFace格式呈现,包含角色:documents, user, assistant。对话的总长度意味着模型主要处理10k+上下文。数据集的目标是教模型回答关于多个文档(1到5个)的复杂和简单问题,并学习拒绝任何在找到的文档中没有答案的问题。此外,模型在每个回答之前会生成一个包含选择文档的单独语句,以更好地控制和监督模型(接地)。文档内容以三种随机格式呈现:Markdown、HTML和纯文本。数据集的构建过程包括解析维基百科文章、过滤和聚类、生成合成问题和答案、过滤答案、后处理和增强原始用户问题、以及将对话分为训练和测试部分。
This dataset is designed for training the grounding capabilities of Large Language Models (LLMs), particularly for Retrieval-Augmented Generation (RAG) based question answering systems. It consists of content extracted from 13,000 articles in the Russian Wikipedia, generated via synthetic questions and answers. The dataset contains 4,047 unique clusters, each representing a combination of documents that simulates the "retrieved results" from a retrieval system. The dataset has a total of 50,210 unique dialogues, which are formatted in the HuggingFace style, with three roles: documents, user, and assistant. The total length of the dialogues implies that the model primarily handles contexts exceeding 10,000 tokens. The core goal of this dataset is to train the model to answer both simple and complex questions about 1 to 5 documents, as well as learn to refuse questions whose answers are not present in the retrieved documents. In addition, the model is required to generate a separate statement that identifies the selected documents prior to each answer, enabling better control and supervision of the model's grounding behavior. The document content is presented in three random formats: Markdown, HTML, and plain text. The construction process of the dataset includes parsing Wikipedia articles, filtering and clustering, generating synthetic questions and answers, filtering the generated answers, post-processing and augmenting the original user questions, as well as splitting the dialogues into training and test subsets.
创建时间:
2024-08-06
原始信息汇总
数据集概述
语言和许可
- 语言:俄语
- 许可:Apache 2.0
数据集信息
- 特征:
cluster:整数类型conversation:列表类型,包含content(字符串类型)和role(字符串类型)docs_count:浮点数类型model:字符串类型type:字符串类型id:字符串类型
- 拆分:
train:878093681字节,50010个样本test:3692039字节,200个样本
- 大小:
- 下载大小:177677029字节
- 数据集大小:881785720字节
配置
default配置:train:数据文件路径为data/train-*test:数据文件路径为data/test-*
数据集详情
- 来源:基于13,000篇不同的俄语维基百科文章,使用合成问题和答案(gpt-4-turbo-1106)生成。
- 内容:包含4047个独特的集群,每个集群是文档的组合,模拟检索系统中的“找到的结果”。
- 总对话数:50210个独特对话。
- 对话格式:在
conversation列中,对话以Huggingface格式呈现,包含documents、user和assistant角色。对话长度主要适用于10k+上下文的模型。 - 重要说明:根据RAG的接地逻辑,
assistant角色在对话末尾重复两次。第一个回答是包含文档ID的JSON字典,第二个是用户问题的完整回答。模型不会在文档文本和用户问题上进行训练,只会在助手的回答上进行训练。
目标
- 训练模型回答关于多个文档(1到5个)的简单和复杂问题,文档格式包括Markdown、HTML和纯文本。
- 模型学会拒绝在找到的文档中没有答案的任何问题。
- 模型在每个回答前生成包含相关信息文档选择的单独回复,以更好地控制和监督模型(接地)。
文档格式
documents角色是一个包含文档内容的字典列表,使用json.dumps(array)表示。- 文档内容以Markdown、HTML和纯文本三种格式之一随机呈现,每个文档内容是从文章中随机选择的4k字符块。
数据集构建步骤
- 解析约30,000篇俄语维基百科文章,以三种不同格式提取随机4k字符块。
- 使用AgglomerativeClustering和e5-large-multilingual进行过滤和聚类,生成约4,000个独特集群,每个集群包含2到5个文档。
- 使用gpt-4-turbo-1106为每个集群生成合成问题,包括10个有答案的“好”问题和4个无答案的“ood”问题。
- 随机丢弃部分集群和标题字段(设置为null)。
- 使用gpt-4-turbo-1106为每个集群和问题生成合成答案,指定在哪些文档中查找答案。
- 过滤错误答案,进行后处理和用户问题增强。
- 将对话组合并拆分为训练和测试部分,按问题类型进行分层。训练部分不包含测试部分的集群。
作者
- Sergey Bratchikov, NLP Wanderer
搜集汇总
数据集介绍
构建方式
Grounded-RAG-RU-v2数据集的构建过程基于13,000篇俄语维基百科文章,通过GPT-4-turbo-1106模型生成合成问答对。数据集包含4,047个独特的文档组合,模拟检索系统中的搜索结果。每个文档组合包含2至5个文档,每个文档以Markdown、HTML或纯文本格式呈现,内容为随机选取的4,000字符以内的文本片段。数据集的构建步骤包括文档解析、聚类、问题生成、答案生成及数据过滤,最终形成50,210个独特的对话。
特点
该数据集的特点在于其对话格式,每个对话包含文档、用户和助手三个角色,且助手的回答分为两部分:首先提供相关文档的ID列表,随后给出基于这些文档的详细回答。数据集特别设计了包含和不包含答案的问题,以训练模型识别和处理无法回答的问题。此外,文档内容以三种随机格式呈现,增加了数据集的多样性和实用性。
使用方法
Grounded-RAG-RU-v2数据集主要用于训练和评估大型语言模型在基于文档的问答任务中的表现。用户可以通过加载数据集并访问对话内容来训练模型,使其能够理解和回答基于多个文档的复杂问题。数据集的结构允许模型学习如何从多个文档中提取信息,并生成准确的回答,同时拒绝回答无法从文档中找到答案的问题。此外,数据集还可用于研究模型在处理不同格式文档时的表现。
背景与挑战
背景概述
Grounded-RAG-RU-v2数据集由Sergey Bratchikov及其团队创建,旨在提升大型语言模型(LLM)在基于文档的问答任务中的表现。该数据集基于13,000篇俄语维基百科文章,通过GPT-4-turbo-1106生成合成问答对,构建了4047个独特的文档簇。每个簇包含2至5个文档,涵盖了Markdown、HTML和纯文本三种格式。数据集的构建过程包括文档解析、聚类、问题生成和答案合成等多个步骤,最终生成了50,210个独特的对话。该数据集的目标是训练模型在复杂和简单的多文档问答任务中表现出色,同时学会拒绝无法从文档中找到答案的问题。
当前挑战
Grounded-RAG-RU-v2数据集面临的主要挑战包括:1) 多文档问答的复杂性,模型需要从多个文档中提取相关信息并生成连贯的答案;2) 数据格式的多样性,文档以Markdown、HTML和纯文本三种格式呈现,增加了模型处理的难度;3) 数据生成过程中的质量控制,确保合成问答对的准确性和多样性;4) 模型训练中的过拟合风险,特别是在处理OOD(Out-of-Distribution)问题时,模型需要学会拒绝无关问题。此外,数据集的构建过程中还涉及文档聚类、问题生成和答案合成的复杂性,这些步骤需要高度的精确性和自动化处理能力。
常用场景
经典使用场景
Grounded-RAG-RU-v2数据集主要用于训练和评估大型语言模型(LLM)在基于文档的问答任务中的表现。该数据集通过模拟检索增强生成(RAG)系统中的对话场景,帮助模型学习如何从多个文档中提取信息并生成准确的回答。数据集中的对话格式包含用户提问、文档内容和助手的回答,特别强调模型在回答前需先选择相关文档,从而实现信息的精准定位。
衍生相关工作
基于Grounded-RAG-RU-v2数据集的研究工作主要集中在改进RAG系统的性能和多文档问答任务的优化。例如,一些研究通过引入更复杂的文档聚类算法和问题生成策略,进一步提升模型的文档理解能力。此外,该数据集还启发了对多语言RAG系统的研究,推动了跨语言信息检索和问答技术的发展。相关研究还探索了如何利用该数据集训练模型处理更复杂的对话场景,如多轮对话和上下文相关的问答任务。
数据集最近研究
最新研究方向
在自然语言处理领域,Grounded-RAG-RU-v2数据集的最新研究方向聚焦于提升大型语言模型(LLM)在检索增强生成(RAG)任务中的表现。该数据集通过结合俄语维基百科的多样化文档和GPT-4生成的合成问答对,旨在训练模型在复杂文档环境中进行精准问答。前沿研究不仅关注模型对多文档信息的整合能力,还强调其在面对无关问题时的拒绝能力,从而提升模型的实用性和可靠性。此外,数据集的设计还引入了文档格式的多样性(如Markdown、HTML和纯文本),以增强模型在不同文本格式下的适应性和泛化能力。这一研究方向对推动多语言、多格式的智能问答系统发展具有重要意义。
以上内容由遇见数据集搜集并总结生成


