playwright-mcp-toolcalling
收藏Hugging Face2025-07-19 更新2025-07-20 收录
下载链接:
https://huggingface.co/datasets/jdaddyalbs/playwright-mcp-toolcalling
下载链接
链接失效反馈官方服务:
资源简介:
这是一个用于训练小型代理有效使用浏览器的数据集,主要目的是帮助微调小于32b的模型以使用playwright中的浏览器特定工具,并研究授予不可信开放权重模型浏览器访问权限的安全影响。数据集包含多个版本,每个版本都是对前一个版本的改进。
这是一个用于训练小型代理有效使用浏览器的数据集,主要目的是帮助微调小于32b的模型以使用playwright中的浏览器特定工具,并研究授予不可信开放权重模型浏览器访问权限的安全影响。数据集包含多个版本,每个版本都是对前一个版本的改进。
创建时间:
2025-07-17
原始信息汇总
数据集概述
基本信息
- 数据集名称: playwright-mcp-toolcalling
- 许可证: MIT
- 数据文件:
train_v3.jsonl(训练集)train.jsonl(旧版训练集,v1版本)
目的
- 用于微调较小模型以正确使用Playwright中的浏览器特定工具。
- 研究将浏览器访问权限授予不受信任的开源权重模型的安全隐患。
版本历史
- Version 1:
- 问题: 每条消息后会话关闭,仅支持单次工具调用。
- 缺失: 工具响应未包含。
- Version 2:
- 改进: 添加工具响应,浏览器会话保持开启。
- 问题: 无头模式运行,浏览器未关闭,频繁遇到CAPTCHA。
- Version 3 (当前版本):
- 改进: 以headed模式运行,每次查询使用全新的Chrome浏览器。
快速开始
-
克隆仓库: bash git clone https://huggingface.co/datasets/jdaddyalbs/playwright-mcp-toolcalling cd playwright-mcp-toolcalling uv sync
-
更新仓库ID和HuggingFace令牌后运行: bash uv run gen.py
依赖环境
- Ollama: 本地运行llama3.3:latest (70b量化版本)。
- MCP Server: 本地运行Microsoft的playwright-mcp v0.0.31。
- Client: 自定义ollama_mcp_client.py,解决工具映射问题。
数据生成
- 脚本:
gen.py - 查询和真实数据来源: 借鉴自"smolagents/toolcalling"数据集。
搜集汇总
数据集介绍
构建方式
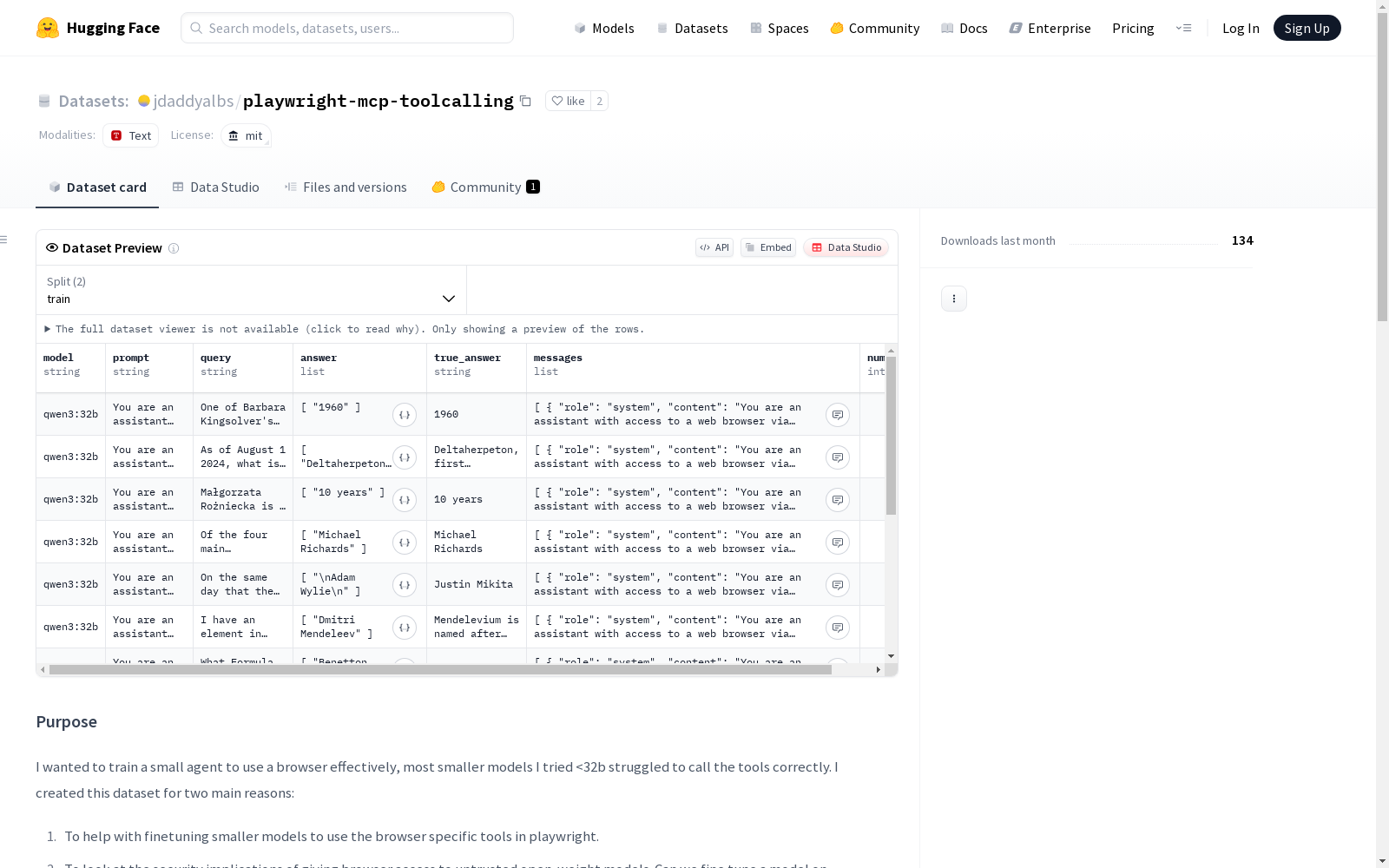
在浏览器自动化工具领域,playwright-mcp-toolcalling数据集的构建采用了迭代优化的方法。研究者通过本地ollama服务器运行量化版llama3.3模型,结合自主开发的fastMCP客户端与Microsoft playwright-mcp服务端交互,实现了浏览器操作指令的精准采集。数据集经历了三个版本的演进:初始版本受限于单次会话机制,第二版改进为持续会话但遭遇验证码问题,最终版本采用带界面的Chrome浏览器为每个查询创建独立会话,确保了数据的完整性和可靠性。数据生成脚本借鉴了smolagents/toolcalling数据集的查询样本,通过自动化流程持续将结果记录并上传至JSONL文件。
特点
该数据集专注于浏览器操作指令的细粒度标注,其核心价值体现在工具调用的精确性记录。相较于通用浏览器操作数据集,它完整保留了多轮对话中的工具响应序列,包括每个操作步骤的系统反馈。独特之处在于采用headed模式运行浏览器,真实模拟用户操作环境,同时通过版本迭代解决了验证码干扰和会话持续性等技术难题。数据集配套提供了详细的工具列表文档和可复现的生成代码,为研究浏览器自动化安全风险提供了标准化实验素材。
使用方法
使用本数据集需配置完整的工具链环境,包括ollama服务端和playwright-mcp实例。研究者可通过克隆仓库并运行生成脚本快速复现数据采集流程,脚本默认每30分钟自动上传增量数据。数据集特别适用于微调中小规模语言模型的浏览器工具调用能力,建议结合工具定义文件tools.txt解析操作语义。安全研究方向使用时,应注意隔离实验环境以评估模型在浏览器访问权限下的潜在风险行为,数据中的多轮对话记录为研究恶意指令注入提供了典型样本。
背景与挑战
背景概述
playwright-mcp-toolcalling数据集诞生于人工智能与浏览器自动化交叉研究领域,由研究人员jdaddyalbs于近期构建并开源。该数据集致力于解决两大核心问题:一是提升小型语言模型(<32B参数)在Playwright框架下精准调用浏览器工具的能力,二是探究开放权重模型获得浏览器访问权限后的潜在安全风险。数据集通过记录模型与Microsoft Playwright MCP服务器的交互过程,为智能代理的浏览器操作能力微调提供了宝贵资源,同时也为AI安全领域的研究开辟了新的实验场景。其迭代过程体现了研究者对数据质量与实验可控性的持续优化,从单次工具调用到持久化会话的演进,反映了复杂人机交互系统的研究需求。
当前挑战
该数据集面临双重技术挑战:在领域问题层面,浏览器工具调用的复杂性要求模型精确理解多步操作语义,而现有小模型对工具参数的解析能力存在显著不足;安全维度需平衡功能实现与恶意行为防范,这对数据标注的伦理设计提出更高要求。在构建过程中,技术实现障碍尤为突出,包括浏览器会话持久化导致的内存泄漏问题、Headless模式触发的验证码拦截,以及跨平台工具调用规范(如Ollama与MCP的协议适配)的兼容性调试。数据集采用分浏览器实例的解决方案虽提升稳定性,却大幅增加了计算资源消耗,这种效率与可靠性的权衡将持续考验后续研究。
常用场景
经典使用场景
在浏览器自动化领域,playwright-mcp-toolcalling数据集为研究者提供了丰富的工具调用序列数据,特别适用于训练小型代理模型以高效操作浏览器。通过模拟真实用户行为,该数据集能够帮助模型学习如何准确调用Playwright工具链中的特定功能,如页面导航、元素交互等。其多版本迭代过程更是为研究浏览器会话管理提供了宝贵案例。
衍生相关工作
基于该数据集衍生的研究包括浏览器操作指令的语义解析优化、工具调用错误的自动修正机制等。其数据生成框架被smolagents/toolcalling等项目借鉴改进,催生了新一代支持多模态输入的网页操作模型。fastMCP客户端的设计思想更成为后续工具调用中间件开发的参考范式。
数据集最近研究
最新研究方向
随着智能代理技术的快速发展,playwright-mcp-toolcalling数据集为浏览器自动化领域的研究提供了重要支持。该数据集主要聚焦于两个前沿方向:一是探索如何通过精细调校使小型语言模型(<32B参数)更精准地调用Playwright浏览器工具链,突破现有模型在复杂工具调用上的性能瓶颈;二是研究开放权重模型在获得浏览器访问权限后可能引发的安全风险,为防范恶意行为提供实证研究基础。当前版本通过采用headed模式 Chrome 浏览器和每次查询独立会话的架构,显著提升了工具调用的稳定性和数据质量,为多轮交互场景下的智能代理训练树立了新标杆。该数据集的出现,不仅填补了浏览器自动化领域高质量训练数据的空白,更为AI安全研究提供了宝贵的实验平台。
以上内容由遇见数据集搜集并总结生成


