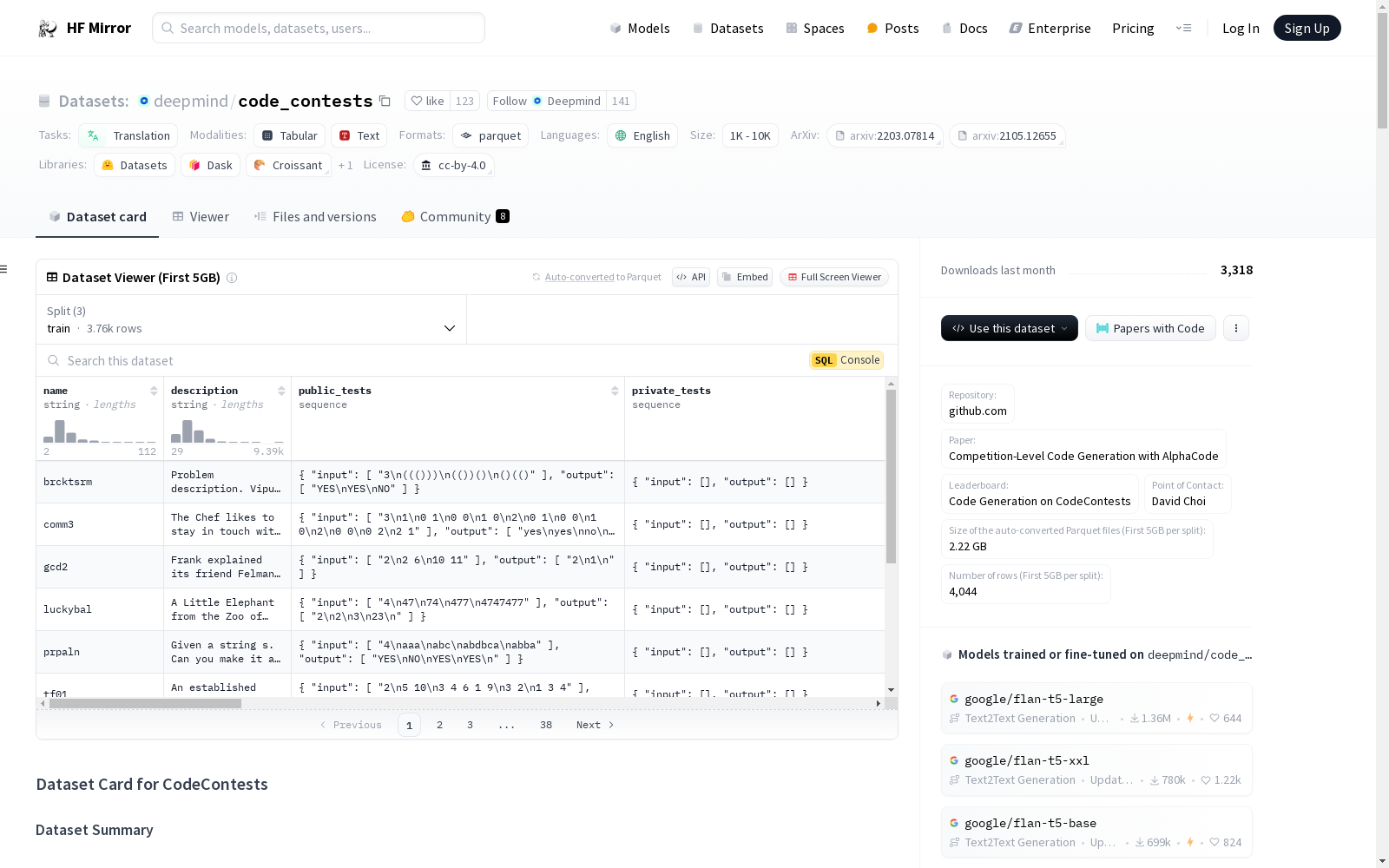
deepmind/code_contests
收藏Hugging Face2023-06-11 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/deepmind/code_contests
下载链接
链接失效反馈官方服务:
资源简介:
---
annotations_creators:
- found
language_creators:
- found
language:
- en
license:
- cc-by-4.0
multilinguality:
- monolingual
size_categories:
- 10K<n<100K
source_datasets:
- original
task_categories:
- translation
task_ids: []
paperswithcode_id: codecontests
pretty_name: CodeContests
---
# Dataset Card for CodeContests
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Repository:** https://github.com/deepmind/code_contests/
- **Paper:** [Competition-Level Code Generation with AlphaCode](https://arxiv.org/abs/2203.07814v1)
- **Leaderboard:** [Code Generation on CodeContests](https://paperswithcode.com/sota/code-generation-on-codecontests)
- **Point of Contact:** [David Choi](mailto:david.hu.choi@gmail.com)
### Dataset Summary
CodeContests is a competitive programming dataset for machine-learning. This
dataset was used when training [AlphaCode](https://deepmind.com/blog/article/Competitive-programming-with-AlphaCode).
It consists of programming problems, from a variety of sources:
Site | URL | Source
----------- | --------------------------- | ------
Aizu | https://judge.u-aizu.ac.jp | [CodeNet](https://github.com/IBM/Project_CodeNet)
AtCoder | https://atcoder.jp | [CodeNet](https://github.com/IBM/Project_CodeNet)
CodeChef | https://www.codechef.com | [description2code](https://github.com/ethancaballero/description2code)
Codeforces | https://codeforces.com | [description2code](https://github.com/ethancaballero/description2code) and Codeforces
HackerEarth | https://www.hackerearth.com | [description2code](https://github.com/ethancaballero/description2code)
Problems include test cases in the form of paired inputs and outputs, as well as both correct and incorrect human solutions in a variety of languages.
### Supported Tasks and Leaderboards
- `translation` - the competitive programming code generation problem can be viewed as a sequence-to-sequence translation task: given a problem description 𝑋 in natural language, produce a corresponding solution 𝑌 in a programming language. The metric used for evaluation is "percentage of problems solved using 𝑛 submissions from 𝑘 samples per problem", denoted as 𝑛@𝑘. More information on the evaluation of AlphaCode can be found in Section 2.2. and Appendix A.3. of the paper. The leaderboard for this task is available [here](https://paperswithcode.com/sota/code-generation-on-codecontests).
### Languages
English.
## Dataset Structure
### Data Instances
A data point corresponds to a singular contest problem:
```
{
'name': '76_B. Mice',
'description': 'Modern researches has shown that a flock of hungry mice '
'searching for a piece of...',
'public_tests': {'input': ['3 2 0 2\n0 1 3\n2 5\n'], 'output': ['1\n']},
'private_tests': {'input': ['20 18 1 2\n'
'-9999944 -9999861 -9999850 -9999763 -9999656 '
'-9999517 -9999375 -999927...',
...,
'7 11 10 20\n'
'6 18 32 63 66 68 87\n'
'6 8 15 23 25 41 53 59 60 75 90\n'],
'output': ['2\n', ..., '1\n']},
'generated_tests': {'input': ['7 11 10 5\n'
'6 18 32 63 66 68 87\n'
'6 8 15 23 25 41 53 59 60 75 90\n',
...,
'7 11 10 4\n'
'6 18 46 63 85 84 87\n'
'6 8 15 18 25 41 53 59 60 75 90\n'],
'output': ['1\n', ..., '2\n']},
'source': 2,
'difficulty': 8,
'solutions': {'language': [2, ..., 2],
'solution': ['#include <bits/stdc++.h>\n'
'using namespace std;\n'
'int n, m;\n'
'int data[2][100010], t[1...',
...,
'#include <bits/stdc++.h>\n'
'using namespace std;\n'
'int n, m, pos[100100], food[100100...']},
'incorrect_solutions': {'language': [2, ..., 2],
'solution': ['#include <bits/stdc++.h>\n'
'using namespace std;\n'
'vector<pair<int, int> > v[100010];...',
...,
'#include <bits/stdc++.h>\n'
'using namespace std;\n'
'vector<pair<int, int> > v[100010];...']},
'cf_contest_id': 76,
'cf_index': 'B',
'cf_points': 0.0,
'cf_rating': 2100,
'cf_tags': ['greedy', 'two pointers'],
'is_description_translated': False,
'untranslated_description': '',
'time_limit': {'seconds': 0, 'nanos': 500000000},
'memory_limit_bytes': 256000000,
'input_file': '',
'output_file': ''
}
```
### Data Fields
- `name`: The name of the contest. Note that names could agree between different sources.
- `description`: A natural language description of a programming problem.
- `public_tests`: Public tests are those that are available before submitting a solution, typically as part of the description itself. Represented as a paired `input` and `output` that can be used to test potential solutions. They are therefore acceptable inputs to a model.
- `private_tests`: Private tests are not visible before submitting a solution, so should not be made available as inputs to a model.
- `generated_tests`: Generated tests are automatically generated by modifying inputs from public and private tests and validating using known correct solutions.
- `source`: The original source of the problem, with possible values including `UNKNOWN_SOURCE` (0),`CODECHEF` (1), `CODEFORCES` (2), `HACKEREARTH` (3), `CODEJAM` (4), `ATCODER` (5) and `AIZU` (6).
- `difficulty`: A representation of the difficulty of the problem with possible values including `UNKNOWN_DIFFICULTY` (0), `EASY` (1), `MEDIUM` (2), `HARD` (3), `HARDER` (4), `HARDEST` (5), `EXTERNAL` (6), `A` (7), `B` (8), `C` (9), `D` (10), `E` (11), `F` (12), `G` (13), `H` (14), `I` (15), `J` (16), `K` (17), `L` (18), `M` (19), `N` (20), `O` (21), `P` (22), `Q` (23), `R` (24), `S` (25), `T` (26), `U` (27) and `V` (28). Note that different sources use different, non-comparable gradings. For Codeforces problems, `cf_rating` is a more reliable measure of difficulty when available.
- `solutions`: Correct solutions to the problem. Contrast with `incorrect_solutions` below.
- `incorrect_solutions`: Incorrect solutions.
- `cf_contest_id`: The Contest ID. Note that Contest ID is not monotonic with respect to time.
- `cf_index`: Problem index, e.g. `"A"` or `"B"` or `"C"`.
- `cf_points`: Points for the problem, e.g. `1000.0`
- `cf_rating`: Problem rating (difficulty), e.g. `1100`
- `cf_tags`: Problem tags, e.g. `['greedy', 'math']`
- `is_description_translated`: Whether the problem was translated to English.
- `untranslated_description`: The untranslated description is only available for translated problems.
- `time_limit`: The time limit constraint to use when executing solutions. Represented as a dictionary with two keys, `seconds` and `nanos`. This field is None if not defined.
- `memory_limit_bytes`: The memory limit constraint to use when executing solutions.
- `input_file`: Most problems use stdin for IO. Some problems expect specific files to be used instead.
- `output_file`: Most problems use stdout for IO. Some problems expect specific files to be used instead.
All tests are represented as a paired `input` and `output` that can be used to test potential solutions and all solutions comprise a `language`, with possible values including `UNKNOWN_LANGUAGE` (0), `PYTHON` (1) (solutions written in PYTHON2), `CPP` (2), `PYTHON3` (3) and `JAVA` (4), and a `solution` string written in that `language`. The fields preceded with `cf_` denote extra meta-data for Codeforces problems.
### Data Splits
The data is split into training, validation and test set. The training set contains 13328 samples, the validation set 117 samples and the test set 165 samples.
## Dataset Creation
### Curation Rationale
This dataset was created for fine-tuning AlphaCode models:
> Models pre-trained on GitHub can generate good code and solve simple programming problems, but
as shown in Appendix B.3 they can solve very few competitive programming problems. Fine-tuning
the model on a dedicated competitive programming dataset is critical for performance.
### Source Data
#### Initial Data Collection and Normalization
The information on the data collection and normalization procedures can found in Section 3.2. and Appendinx B.2. of the paper.
#### Who are the source language producers?
The problems are scraped from the following platforms: [Aizu](https://judge.u-aizu.ac.jp), [AtCoder](https://atcoder.jp ), [CodeChef](https://www.codechef.com), [Codeforces](https://codeforces.com) and [HackerEarch](https://www.hackerearth.com). Additionally, some data from the existing public competitive programming dataset Description2Code ([Caballero et al., 2016](https://github.com/ethancaballero/description2code)) and CodeNet ([(Puri et al., 2021](https://arxiv.org/pdf/2105.12655.pdf)) is mixed into the training set.
### Annotations
#### Annotation process
The solutions are scapred alongside the problem descriptions.
#### Who are the annotators?
Same as the source data creators.
### Personal and Sensitive Information
[More Information Needed]
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed]
### Discussion of Biases
[More Information Needed]
### Other Known Limitations
[More Information Needed]
## Additional Information
### Dataset Curators
Yujia Li, David Choi, Junyoung Chung, Nate Kushman, Julian Schrittwieser, Rémi Leblond, Tom Eccles, James Keeling, Felix Gimeno, Agustin Dal Lago, Thomas Hubert, Peter Choy, Cyprien de Masson d'Autume, Igor Babuschkin, Xinyun Chen, Po-Sen Huang, Johannes Welbl, Sven Gowal, Alexey Cherepanov, James Molloy, Daniel J. Mankowitz, Esme Sutherland Robson, Pushmeet Kohli, Nando de Freitas, Koray Kavukcuoglu and Oriol Vinyals.
### Licensing Information
This dataset is made available under the terms of the CC BY
4.0 license ([Creative Commons Attribution 4.0 International license](https://creativecommons.org/licenses/by/4.0/legalcode)).
Additional acknowledged contributions:
* Codeforces materials are sourced from http://codeforces.com.
* Description2Code materials are sourced from:
[Description2Code Dataset](https://github.com/ethancaballero/description2code),
licensed under the
[MIT open source license](https://opensource.org/licenses/MIT), copyright
not specified.
* CodeNet materials are sourced from:
[Project_CodeNet](https://github.com/IBM/Project_CodeNet), licensed under
[Apache 2.0](https://www.apache.org/licenses/LICENSE-2.0), copyright not
specified.
### Citation Information
```bibtex
@article{li2022competition,
title={Competition-Level Code Generation with AlphaCode},
author={Li, Yujia and Choi, David and Chung, Junyoung and Kushman, Nate and
Schrittwieser, Julian and Leblond, R{\'e}mi and Eccles, Tom and
Keeling, James and Gimeno, Felix and Dal Lago, Agustin and
Hubert, Thomas and Choy, Peter and de Masson d'Autume, Cyprien and
Babuschkin, Igor and Chen, Xinyun and Huang, Po-Sen and Welbl, Johannes and
Gowal, Sven and Cherepanov, Alexey and Molloy, James and
Mankowitz, Daniel and Sutherland Robson, Esme and Kohli, Pushmeet and
de Freitas, Nando and Kavukcuoglu, Koray and Vinyals, Oriol},
journal={arXiv preprint arXiv:2203.07814},
year={2022}
}
```
### Contributions
Thanks to [@mariosasko](https://github.com/mariosasko) for adding this dataset.
提供机构:
deepmind
原始信息汇总
数据集概述
数据集基本信息
- 名称: CodeContests
- 语言: 英语
- 许可证: CC BY 4.0
- 多语言性: 单语
- 大小: 10K<n<100K
- 源数据集: 原始数据
- 任务类别: 翻译
数据集结构
数据实例
每个数据点对应一个竞赛问题,包含名称、描述、测试用例、解决方案等信息。
数据字段
- name: 竞赛名称
- description: 问题描述
- public_tests: 公开测试用例
- private_tests: 私有测试用例
- generated_tests: 生成测试用例
- source: 问题来源
- difficulty: 难度等级
- solutions: 正确解决方案
- incorrect_solutions: 错误解决方案
- cf_contest_id: 竞赛ID
- cf_index: 问题索引
- cf_points: 问题分数
- cf_rating: 问题难度评级
- cf_tags: 问题标签
- is_description_translated: 描述是否已翻译
- time_limit: 时间限制
- memory_limit_bytes: 内存限制
数据分割
- 训练集: 13328样本
- 验证集: 117样本
- 测试集: 165样本
数据集创建
数据收集与标准化
问题从Aizu、AtCoder、CodeChef、Codeforces和HackerEarth等平台收集,并混合了Description2Code和CodeNet的数据。
注释过程
解决方案与问题描述一同收集。
注释者
与数据源创建者相同。
使用数据注意事项
- 社会影响: 待补充
- 偏见讨论: 待补充
- 其他已知限制: 待补充
附加信息
- 数据集管理者: Yujia Li, David Choi等
- 许可证信息: CC BY 4.0
- 引用信息: 见提供的bibtex引用格式
- 贡献者: @mariosasko
搜集汇总
数据集介绍
构建方式
CodeContests数据集的构建基于多个知名编程竞赛平台的编程问题,包括Aizu、AtCoder、CodeChef、Codeforces和HackerEarth。数据集的构建过程中,不仅收集了问题描述,还包含了公开测试用例、私有测试用例以及自动生成的测试用例。此外,数据集还收录了正确和错误的解决方案,涵盖多种编程语言。这些数据经过规范化处理,以确保其适用于机器学习模型的训练和评估。
特点
CodeContests数据集的主要特点在于其多样性和复杂性。数据集包含了来自多个竞赛平台的编程问题,涵盖了不同难度级别和编程语言。每个问题都附带了详细的描述、测试用例以及多种解决方案,这使得数据集非常适合用于代码生成和编程问题解决的机器学习任务。此外,数据集还提供了私有测试用例和自动生成的测试用例,增加了数据集的挑战性和实用性。
使用方法
CodeContests数据集适用于代码生成和编程问题解决的机器学习任务。用户可以通过提供的自然语言问题描述,训练模型生成相应的代码解决方案。数据集的结构设计使得用户可以轻松访问问题描述、测试用例以及解决方案,从而进行模型的训练、验证和测试。用户可以根据数据集中的不同难度级别和编程语言,选择合适的子集进行实验,并通过公开和私有测试用例评估模型的性能。
背景与挑战
背景概述
CodeContests数据集由DeepMind于2022年创建,旨在支持机器学习在竞争性编程领域的应用。该数据集的核心研究问题是如何通过机器学习生成高质量的代码解决方案,以应对复杂的编程挑战。CodeContests数据集的构建基于多个知名编程竞赛平台,如Aizu、AtCoder、CodeChef、Codeforces和HackerEarth,并结合了CodeNet和Description2Code等现有数据集。该数据集的创建不仅为AlphaCode模型的训练提供了关键资源,还推动了代码生成技术在竞争性编程中的应用,对相关领域的研究具有重要影响。
当前挑战
CodeContests数据集面临的挑战主要集中在两个方面。首先,竞争性编程问题的复杂性和多样性使得数据集的构建和标注过程极为复杂,需要从多个来源收集和整合数据,并确保数据的准确性和一致性。其次,代码生成任务本身具有高度挑战性,要求模型能够理解自然语言描述并生成符合要求的代码,同时还需要处理多种编程语言和不同难度级别的编程问题。此外,数据集中包含的测试用例和解决方案的多样性也为模型的评估和验证带来了额外的复杂性。
常用场景
经典使用场景
CodeContests数据集在机器学习领域中被广泛用于竞争性编程问题的生成与解决。其经典使用场景包括将自然语言描述的编程问题转化为相应的代码解决方案,这一过程可视为序列到序列的翻译任务。通过提供丰富的编程问题及其对应的测试用例,该数据集为模型训练提供了高质量的输入输出对,从而提升了代码生成模型的性能。
实际应用
CodeContests数据集在实际应用中具有广泛的前景,特别是在自动化编程和智能编程助手领域。通过训练模型生成高质量的代码解决方案,该数据集可用于构建能够自动解决复杂编程问题的系统,从而提高开发效率。此外,它还可应用于编程教育,帮助学生通过自动生成的解决方案学习编程技巧。
衍生相关工作
CodeContests数据集的发布催生了一系列相关研究工作,特别是在代码生成和竞争性编程领域。例如,基于该数据集的AlphaCode模型展示了在竞争性编程中的卓越表现,推动了代码生成技术的进一步发展。此外,该数据集还激发了对编程问题描述与代码生成之间关系的深入研究,促进了自然语言处理与编程语言理解的交叉学科发展。
以上内容由遇见数据集搜集并总结生成


