DataComp-12M
收藏数据集卡片 for DataComp-12M
概述
该数据集包含 DataComp-1B-BestPool 的 12M 子集。我们以标准的 Creative Common CC-BY-4.0 许可证分发图像 URL-文本样本和元数据。个别图像受其自身版权保护。
在 DataComp-12M 上训练的图像-文本模型明显优于在 CC-12M/YFCC-15M 以及 DataComp-Small/Medium 上训练的模型。
DataComp-12M 在 MobileCLIP 论文 中引入,并与增强数据集 DataCompDR-12M 一起发布。mlfoundations/DataComp-12M 和 apple/DataCompDR-12M 之间的 UID 分片匹配。
数据集信息
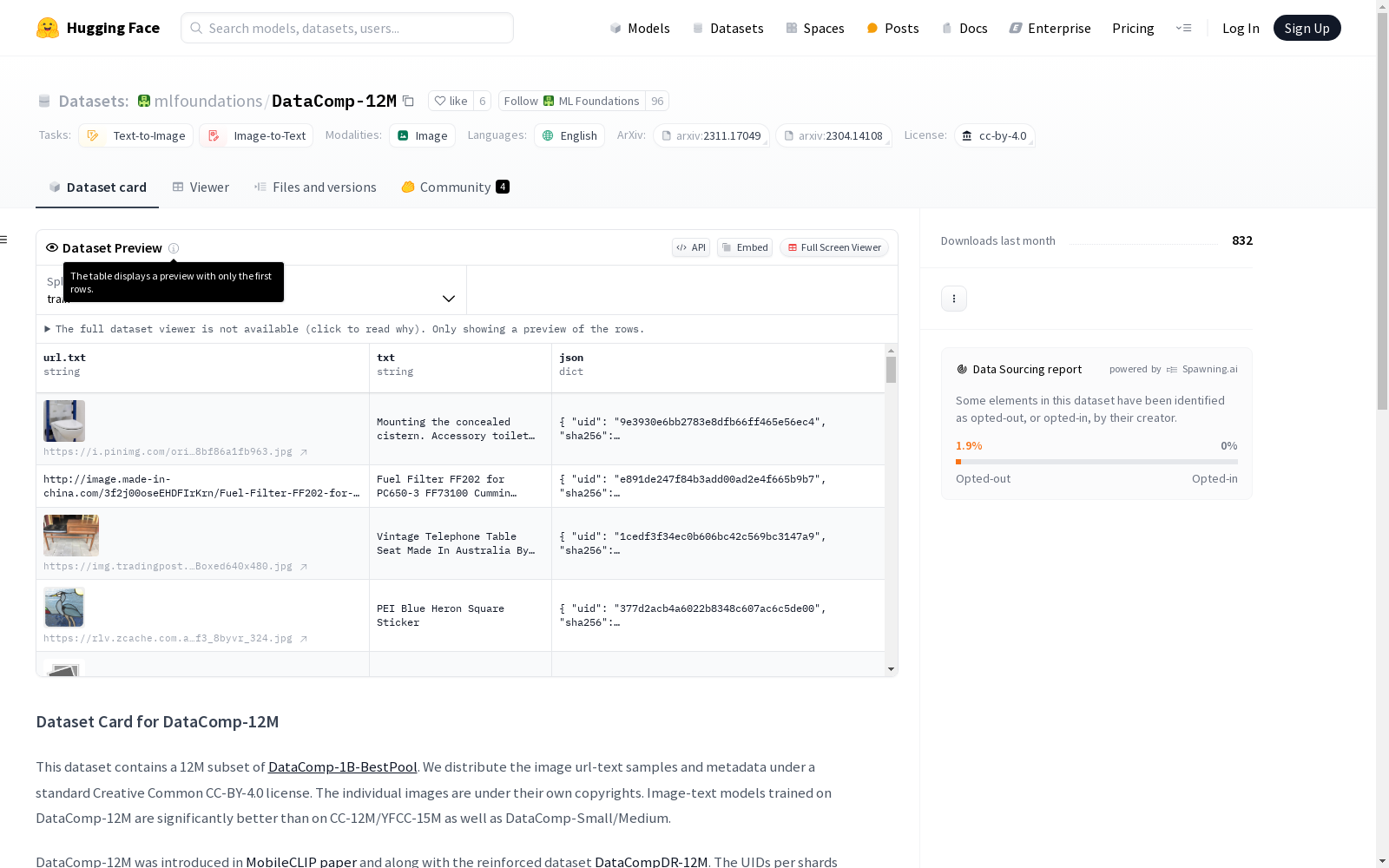
特征
- url.txt: 数据类型为字符串。
- txt: 数据类型为字符串。
- json: 结构化数据,包含以下字段:
- uid: 数据类型为字符串。
- sha256: 数据类型为字符串。
- original_height: 数据类型为 int32。
- original_width: 数据类型为 int32。
许可证
该数据集的许可证为 CC-BY-4.0。
引用
DataComp
bibtex @article{gadre2024datacomp, title={Datacomp: In search of the next generation of multimodal datasets}, author={Gadre, Samir Yitzhak and Ilharco, Gabriel and Fang, Alex and Hayase, Jonathan and Smyrnis, Georgios and Nguyen, Thao and Marten, Ryan and Wortsman, Mitchell and Ghosh, Dhruba and Zhang, Jieyu and others}, journal={Advances in Neural Information Processing Systems}, volume={36}, year={2024} }
MobileCLIP
bibtex @InProceedings{mobileclip2024, author = {Pavan Kumar Anasosalu Vasu, Hadi Pouransari, Fartash Faghri, Raviteja Vemulapalli, Oncel Tuzel}, title = {MobileCLIP: Fast Image-Text Models through Multi-Modal Reinforced Training}, booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)}, month = {June}, year = {2024}, }