nepali-asr-community-data
收藏Hugging Face2025-05-16 更新2025-05-17 收录
下载链接:
https://huggingface.co/datasets/darvilab/nepali-asr-community-data
下载链接
链接失效反馈官方服务:
资源简介:
尼泊尔语自动语音识别开源数据集,包含社区贡献的尼泊尔语语音录音,用于推动尼泊尔语ASR技术的发展。数据包括不同说话人的自然对话和代码转换例子。
创建时间:
2025-05-16
搜集汇总
数据集介绍
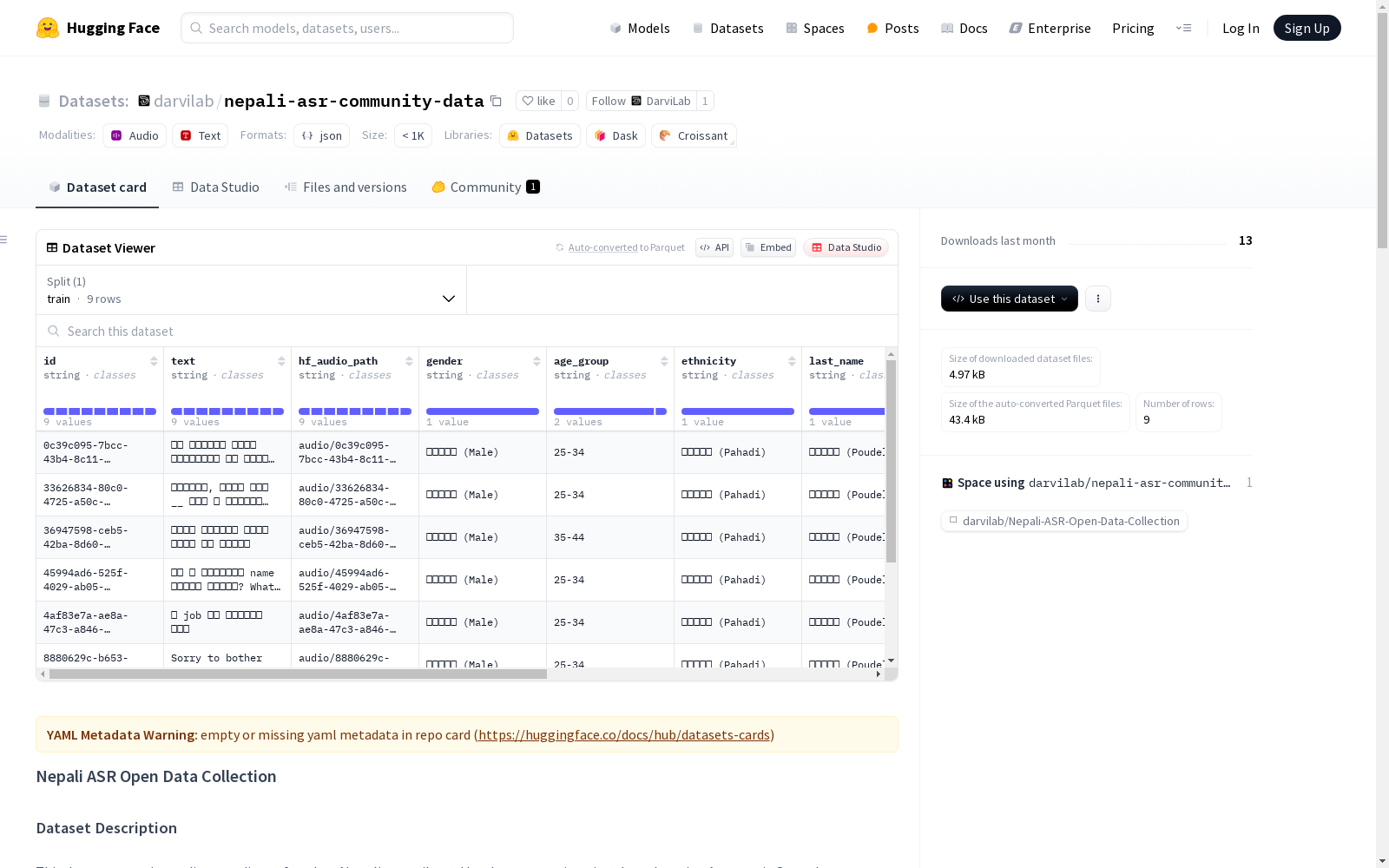
构建方式
该数据集通过公开的Gradio应用程序收集尼泊尔语语音样本,采用社区众包模式构建。数据采集过程鼓励多样化的参与者贡献语音,涵盖不同年龄、性别、民族和地理区域的发音特征,并包含自然对话和尼泊尔语-英语语码转换实例。每个样本均附带详尽的元数据标注,通过结构化目录存储音频文件与对应元数据,确保数据可追溯性。
使用方法
用户可通过HuggingFace datasets库加载数据集,需注意音频文件与元数据的映射关系。数据集采用分目录存储结构,音频文件存放于audio/目录,元数据以JSON格式保存在metadata_entries/目录。加载时需自定义处理脚本将音频路径映射到对应特征列,建议使用Audio特征列指定采样率(如16000Hz)确保正确解码。社区评分的元数据可通过ratings_entries/目录单独访问。
背景与挑战
背景概述
Nepali ASR Open Data Collection数据集由社区贡献的尼泊尔语语音录音组成,旨在推动尼泊尔语自动语音识别(ASR)技术的发展。该数据集由darvilab团队主导创建,通过公开的Gradio应用收集多样化的语音样本,涵盖不同说话者、提示文本和自然对话语音,包括尼泊尔语与英语的语码转换现象。作为开源资源,该数据集为低资源语言的语音技术研究提供了重要支持,填补了尼泊尔语在ASR领域的数据空白,对促进语言技术公平性具有积极意义。
当前挑战
该数据集面临的核心挑战体现在两个方面:在领域问题层面,尼泊尔语作为低资源语言,存在方言变异大、语码转换频繁等特性,导致语音识别模型在口音适应性和语义理解上存在困难;在构建过程层面,需平衡数据多样性(如年龄、地域、民族分布)与隐私保护的关系,同时社区众包模式面临音频质量参差、标注一致性维护等难题,需通过动态投票机制和元数据标准化来解决。
常用场景
经典使用场景
在语音识别技术的研究中,nepali-asr-community-data数据集为尼泊尔语自动语音识别(ASR)系统的开发提供了丰富的语音样本。该数据集通过社区贡献的方式收集了多样化的语音数据,包括不同年龄、性别、地域背景的说话者,以及自然对话和固定提示文本的录音。这些数据为构建和优化尼泊尔语ASR模型提供了重要的训练和测试资源。
解决学术问题
该数据集解决了尼泊尔语语音识别研究中数据稀缺的问题,特别是在多方言和代码转换(尼泊尔语-英语)场景下的语音数据。通过提供多样化的语音样本,研究者可以更全面地评估和改进ASR模型在不同语音环境下的表现,从而推动尼泊尔语语音技术的学术研究进展。
实际应用
在实际应用中,nepali-asr-community-data数据集可以用于开发尼泊尔语的语音助手、语音转文字工具以及语音驱动的应用程序。这些应用在尼泊尔的教育、医疗、客户服务等领域具有广泛的应用潜力,特别是在多语言混合的环境中,能够显著提升语音技术的实用性和普及度。
数据集最近研究
最新研究方向
在低资源语言自动语音识别领域,尼泊尔语ASR社区数据集正推动跨学科研究的发展。该数据集独特的社区共建模式为方言多样性、情感语音识别以及代码转换现象研究提供了珍贵素材。研究者们正探索如何利用其多维度元数据优化端到端语音模型,特别是在说话人自适应和口音鲁棒性方面取得突破。近期相关研究聚焦于基于Transformer的混合语言建模,以解决尼泊尔语-英语代码转换场景下的音素对齐难题。该数据集的开放特性还促进了南亚语言技术联盟的形成,成为联合国语言平等倡议的重要实践案例。
以上内容由遇见数据集搜集并总结生成


