imodels/multitask-tabular-datasets
收藏Hugging Face2024-03-11 更新2024-06-11 收录
下载链接:
https://hf-mirror.com/datasets/imodels/multitask-tabular-datasets
下载链接
链接失效反馈官方服务:
资源简介:
---
license: mit
---
This is a port of the Multi-Label Classification Dataset Repository ([link](https://www.uco.es/kdis/mllresources/#EnronDesc)).
- We convert the datasets from there to simple csvs, resulting in 32 csvs (many of their mulan files fail to parse into python for us)
- The targets in each csv are labeled with the suffix __target
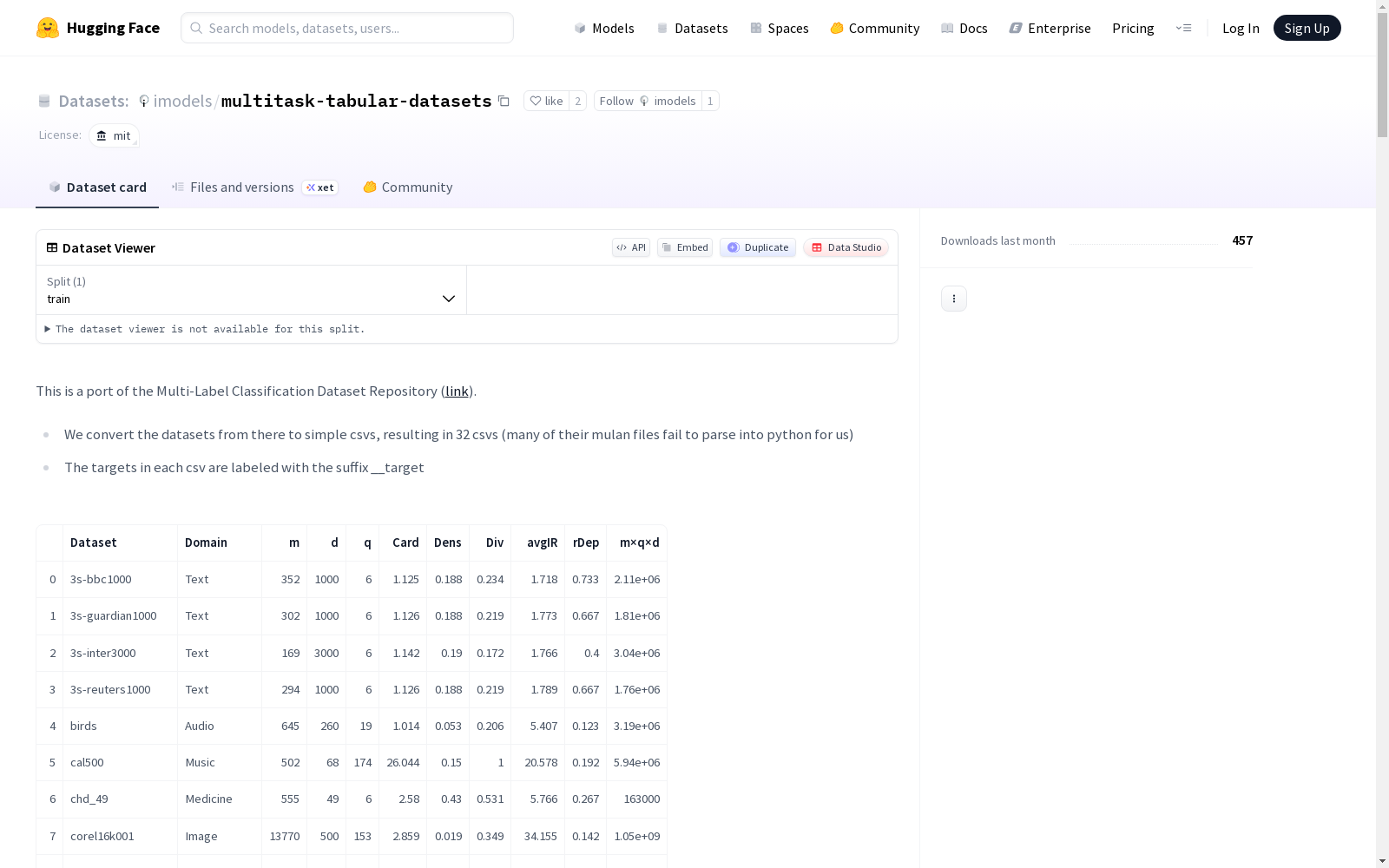
| | Dataset | Domain | m | d | q | Card | Dens | Div | avgIR | rDep | m×q×d |
|---:|:------------------|:-----------|------:|-----:|----:|-------:|-------:|------:|--------:|-------:|--------------:|
| 0 | 3s-bbc1000 | Text | 352 | 1000 | 6 | 1.125 | 0.188 | 0.234 | 1.718 | 0.733 | 2.11e+06 |
| 1 | 3s-guardian1000 | Text | 302 | 1000 | 6 | 1.126 | 0.188 | 0.219 | 1.773 | 0.667 | 1.81e+06 |
| 2 | 3s-inter3000 | Text | 169 | 3000 | 6 | 1.142 | 0.19 | 0.172 | 1.766 | 0.4 | 3.04e+06 |
| 3 | 3s-reuters1000 | Text | 294 | 1000 | 6 | 1.126 | 0.188 | 0.219 | 1.789 | 0.667 | 1.76e+06 |
| 4 | birds | Audio | 645 | 260 | 19 | 1.014 | 0.053 | 0.206 | 5.407 | 0.123 | 3.19e+06 |
| 5 | cal500 | Music | 502 | 68 | 174 | 26.044 | 0.15 | 1 | 20.578 | 0.192 | 5.94e+06 |
| 6 | chd_49 | Medicine | 555 | 49 | 6 | 2.58 | 0.43 | 0.531 | 5.766 | 0.267 | 163000 |
| 7 | corel16k001 | Image | 13770 | 500 | 153 | 2.859 | 0.019 | 0.349 | 34.155 | 0.142 | 1.05e+09 |
| 8 | corel16k002 | Image | 13760 | 500 | 164 | 2.882 | 0.018 | 0.354 | 37.678 | 0.128 | 1.13e+09 |
| 9 | corel16k003 | Image | 13760 | 500 | 154 | 2.829 | 0.018 | 0.35 | 37.058 | 0.137 | 1.06e+09 |
| 10 | corel16k004 | Image | 13840 | 500 | 162 | 2.842 | 0.018 | 0.351 | 35.899 | 0.126 | 1.12e+09 |
| 11 | corel16k005 | Image | 13850 | 500 | 160 | 2.858 | 0.018 | 0.364 | 34.936 | 0.133 | 1.11e+09 |
| 12 | corel16k006 | Image | 13860 | 500 | 162 | 2.885 | 0.018 | 0.361 | 33.398 | 0.128 | 1.12e+09 |
| 13 | corel16k007 | Image | 13920 | 500 | 174 | 2.886 | 0.017 | 0.371 | 37.715 | 0.12 | 1.21e+09 |
| 14 | corel16k008 | Image | 13860 | 500 | 168 | 2.883 | 0.017 | 0.357 | 36.2 | 0.121 | 1.16e+09 |
| 15 | corel16k009 | Image | 13880 | 500 | 173 | 2.93 | 0.017 | 0.373 | 36.446 | 0.119 | 1.2e+09 |
| 16 | corel16k010 | Image | 13620 | 500 | 144 | 2.815 | 0.02 | 0.345 | 32.998 | 0.147 | 9.81e+08 |
| 17 | corel5k | Image | 5000 | 499 | 374 | 3.522 | 0.009 | 0.635 | 189.568 | 0.03 | 9.33e+08 |
| 18 | emotions | Music | 593 | 72 | 6 | 1.868 | 0.311 | 0.422 | 1.478 | 0.933 | 256000 |
| 19 | flags | Image | 194 | 19 | 7 | 3.392 | 0.485 | 0.422 | 2.255 | 0.381 | 25800 |
| 20 | foodtruck | Recommend. | 407 | 21 | 12 | 2.29 | 0.191 | 0.285 | 7.095 | 0.409 | 103000 |
| 21 | genbase | Biology | 662 | 1186 | 27 | 1.252 | 0.046 | 0.048 | 37.315 | 0.157 | 2.12e+07 |
| 22 | image | Image | 2000 | 294 | 5 | 1.236 | 0.247 | 0.625 | 1.193 | 0.9 | 2.94e+06 |
| 23 | mediamill | Video | 43910 | 120 | 101 | 4.376 | 0.043 | 0.149 | 256.405 | 0.342 | 5.32e+08 |
| 24 | scene | Image | 2407 | 294 | 6 | 1.074 | 0.179 | 0.234 | 1.254 | 0.933 | 4.25e+06 |
| 25 | stackex_chemistry | Text | 6961 | 540 | 175 | 2.109 | 0.012 | 0.436 | 56.878 | 0.056 | 6.58e+08 |
| 26 | stackex_chess | Text | 1675 | 585 | 227 | 2.411 | 0.011 | 0.644 | 85.79 | 0.03 | 2.22e+08 |
| 27 | stackex_cooking | Text | 10490 | 577 | 400 | 2.225 | 0.006 | 0.609 | 37.858 | 0.034 | 2.42e+09 |
| 28 | stackex_cs | Text | 9270 | 635 | 274 | 2.556 | 0.009 | 0.512 | 85.002 | 0.049 | 1.61e+09 |
| 29 | water-quality | Chemistry | 1060 | 16 | 14 | 5.073 | 0.362 | 0.778 | 1.767 | 0.473 | 237000 |
| 30 | yeast | Biology | 2417 | 103 | 14 | 4.237 | 0.303 | 0.082 | 7.197 | 0.67 | 3.49e+06 |
| 31 | yelp | Text | 10810 | 671 | 5 | 1.638 | 0.328 | 1 | 2.876 | 0.7 | 3.63e+07 |
Explanation of the datasets is given below, copied from the Multi-Label Classification Dataset Repository ([link](https://www.uco.es/kdis/mllresources/#EnronDesc)).
For each dataset we provide a short description as well as some characterization metrics. It includes the number of instances (m), number of attributes (d), number of labels (q), cardinality (Card), density (Dens), diversity (Div), average Imbalance Ratio per label (avgIR), ratio of unconditionally dependent label pairs by chi-square test (rDep) and complexity, defined as m × q × d as in [Read 2010]. Cardinality measures the average number of labels associated with each instance, and density is defined as cardinality divided by the number of labels. Diversity represents the percentage of labelsets present in the dataset divided by the number of possible labelsets. The avgIR measures the average degree of imbalance of all labels, the greater avgIR, the greater the imbalance of the dataset. Finally, rDep measures the proportion of pairs of labels that are dependent at 99% confidence. A broader description of all the characterization metrics and the used partition methods are described in the MLDA documentation. We also used MLDA for the characterization and partitioning of the datasets.
Description of the datasets
20NG [Lang 2008]: is a compilation of around 20000 post to 20Newsgroups. Around 1000 posts are available for each group.
3sources [Greene et al. 2009]: These datasets includes 948 news articles covering 416 distinct news stories from the period February–April 2009. They have been collected from 3 sources: BBC, Reuters and The Guardian. Of these stories, 169 were reported in all three sources, 194 in two sources, and 53 appeared in a single news source. Each story was manually annotated with one or more of the six topical labels: business, entertainment, health, politics, sport, technology. In this way, three datasets with the news from BBC, Reuters and The Guardian respectively are created. A feature selection method has been performed in order to reduce the feature space and achieve a better performance. Each dataset has been selected 1000 features. Also, a dataset with the intersection (3sources-inter3000) of these three datasets (news which are in all three sources) has been created with the union of the 1000 features of each one of the datasets. The 3soures-inter3000 dataset can be also considered as a Multi-View Multi-Label (MVML) dataset, since it includes features from 3 distinct sources. The original data has been downloaded from http://mlg.ucd.ie/datasets/3sources.html
Bibtex [Katakis et al. 2008]: This dataset is based on the data of the ECML/PKDD 2008 discovery challenge. It contains 7395 bibtex entries from the BibSonomy social bookmark and publication sharing system, annotated with a subset of the tags assigned by BibSonomy users.
Birds [Briggs et al. 2013]: It is a dataset to predict the set of birds species that are present, given a ten-second audio clip.
Bookmarks [Katakis et al. 2008]: Is based on the data of the ECML/PKDD 2008 discovery challenge and contains bookmark entries from the Bibsonomy system.
CHD_49 [Shao et al. 2013]: This dataset has information of coronary heart disease (CHD) in traditional Chinese medicine (TCM). This dataset has been filtered by specialist removing irrelevant features, keeping only 49 features.
CAL500 [Turnbull et al. 2008]: It is a music dataset, composed by 502 songs. Each one was manually annotated by at least three human annotators, who employ a vocabulary of 174 tags concerning to semantic concepts. These tags span 6 semantic categories: instrumentation, vocal characteristics, genres, emotions, acoustic quality of the song, and usage terms.
Corel5k [Duygulu et al. 2002]: Corel5k is a popular benchmark for image classification and annotation methods. It is based in 5000 Corel images.
Corel16k [Barnard et al. 2003] is derived from the popular benchmark dataset ECCV 2002 by eliminating less frequently appeared labels.
Delicious [Tsoumakas et al. 2008]: This dataset contains textual data of web pages along with their tags.
Emotions [Tsoumakas et al. 2008]: Also called Music in [Read 2010]. Is a small dataset to classify music into emotions that it evokes according to the Tellegen-Watson-Clark model of mood: amazed-suprised, happy-pleased, relaxing-calm, quiet-still, sad-lonely and angry-aggresive. It consists of 593 songs with 6 classes.
Enron [Read et al. 2008]: The Enron dataset is a subset of Enron email Corpus, labelled with a set of categories. It is based in a collection of email messages that were categorized into 53 topic categories, such as company strategy, humour and legal advice.
Eukaryote [Xu et al. 2016]: This dataset is used to predict the sub-cellular locations of proteins according to their sequences. It contains 7766 sequences for Eukaryote species. Both the GO (Gene ontology) features and PseAAC (including 20 amino acid, 20 pseudo-amino acid and 400 diptide components) are provided. There are 22 subcellular locations (acrosome, cell membrane, cell wall, centrosome, chloroplast, cyanelle, cytoplasm, cytoeskeleton, endoplasmatic reticulum, endosome, extracell, golgi apparatus, hydrogenosome, lysosome, melanosome, microsome, mitochondrion, nucleus, peroxisome, spindle pole body, synapse and vacuole).
EUR-Lex [Loza and Fürnkranz 2008]: The EUR-Lex text collection is a collection of 19348 documents about European Union law. It contains many different types of documents, as treaties, legislation, case-law and legislative proposals, which are indexed according to several orthogonal categorization schemes to allow for multiple search facilities. The most important categorization is provided by the EUROVOC descriptors, which form a topic hierarchy with almost 4000 categories regarding different aspects of European law.
Flags [Gonçalves et al. 2013]: This dataset contains details of some countries and their flags, and the goal is to predict some of the features. The dataset was used the first time for Multi-label Classification in [Gonçalves et al. 2013], and the original dataset can be found at the UCI repository.
Foodtruck [Rivolli et al. 2017]: The food truck dataset was created from the answers provided by the 407 survey participants. They either were approached in fast food festivals and popular events or anonymously received a request to fill out a questionnaire, in Portuguese, describing their personal information and preferences when it comes to their selection from food trucks.
Genbase [Diplaris et al. 2005]: It is a dataset for protein function classification. Each instance is a protein and each label is a protein class. This dataset is small comparatively with the large number of labels.
Gnegative [Xu et al. 2016]: This dataset is used to predict the sub-cellular locations of proteins according to their sequences. It contains 1392 sequences for Gram negative bacterial (Gnegative) species. Both the GO (Gene ontology) features and PseAAC (including 20 amino acid, 20 pseudo-amino acid and 400 diptide components) are provided. There are 8 subcellular locations (cell inner membrane, cell outer membrane, cytoplasm, extracellular, fimbrium, flagellum, nucleoid and periplasm).
Gpositive [Xu et al. 2016]: This dataset is used to predict the sub-cellular locations of proteins according to their sequences. It contains 519 sequences for Gram positive species. Both the GO (Gene ontology) features and PseAAC (including 20 amino acid, 20 pseudo-amino acid and 400 diptide components) are provided. There are 4 subcellular locations (cell membrane, cell wall, cytoplasm and extracell).
Human [Xu et al. 2016]: This dataset is used to predict the sub-cellular locations of proteins according to their sequences. It contains 3106 sequences for Human species. Both the GO (Gene ontology) features and PseAAC (including 20 amino acid, 20 pseudo-amino acid and 400 diptide components) are provided. There are 14 subcellular locations (centriole, cytoplasm, cytoskeleton, endoplasm reticulum, endosome, extracell, golgi apparatus, lysosome, microsome, mitochondrion, nucleus, peroxisome, plasma membrace, and synapse).
Image [Zhang and Zhou 2007]: This dataset is composed by 2,000 images. Concretely, each color image is firstly converted to the CIE Luv space, which is a more perceptually uniform color space such that perceived color differences correspond closely to Euclidean distances in this color space. After that, the image is divided into 49 blocks using a 7×7 grid, where in each block the first and second moments (mean and variance) of each band are computed, corresponding to a low-resolution image and to computationally inexpensive texture features respectively. Finally, each image is transformed into a 49×3×2 = 294-dimensional feature vector.
IMDB [Read 2010]: It contains 120919 movie plot tex summaries from the Internet Movie Database (www.imdb.com), labelled with one or more genres.
LangLog [Read 2010]: It was compiled from the Language Log Forum, which discussed various topics relating to language, and 75 topics represents the label space.
Mediamill [Snoek et al. 2006]: It is a multimedia dataset for generic video indexing, which was extracted tom the TRECVID 2005/2006 benchmark. This dataset contains 85 hours of international broadcast news data categorized into 100 labels and each video instance is represented as a 120-dimensional feature vector of numeric features.
Medical [Pestian et al. 2007]: The dataset is based on the data made available during the Computational Medicine Centers 2007 Medical Natural Language Processing Challenge 10 . It consists of 978 clinical free text reports labelled with one or more out of 45 disease codes.
Nus-Wide [Chua et al. 2009]: We provide two versions of the full NUS-WIDE dataset. In the first version, images are represented using 500-D bag of visual words features provided by the creators of the dataset [Chua et al. 2009]. In the second version, images are represented using 128-D cVLAD+ features described in [Spyromitros et al. 2014]. In both cases, the 1st attribute is the image id.
Ohsumed [Joachims 1998]: This collection includes medical abstracts from the MeSH categories of the year 1991. The specific task was to categorize the 23 cardiovascular diseases categories.
Plant [Xu et al. 2016]: This dataset is used to predict the sub-cellular locations of proteins according to their sequences. It contains 978 sequences for Plant species. Both the GO (Gene ontology) features and PseAAC (including 20 amino acid, 20 pseudo-amino acid and 400 diptide components) are provided. There are 12 subcellular locations (cell membrace, cell wall, chloroplast, cytoplasm, endoplasmic reticulum, extracellular, golgi apparatus, mitochondrion, nucleus, peroxisome, plastid, and vacuole).
Reuters-RCV1 [Lewis et al. 2004]: This dataset is a well-known benchmark for text classification methods. It has 5 subsets, each one with 6000 articles assigned into one or more of 101 topics. The Reuters-K500 dataset was obtained by selecting 500 features by applying the method proposed in [Tsoumakas et al. 2007].
Scene [Boutell et al. 2004]: It is a image dataset, that contains 2407 images, annotated in up to 6 classes: beach, sunset, fall foliage, field, mountain and urban. Each image is described with 294 visual numeric features corresponding to spatial colour moments in the LUV space.
Slashdot [Read 2010]: It consists of article blurbs with subject categories representing the label space, mined from http://slashdot.org.
Stackex [Charte et al. 2015]: It is a collection of six datasets generated from the text collected in a selection of Stack Exchange forums. It includes stackex_chess, stackex_chemistry, stackex_coffee, stackex_cooking, stackex_cs and stackex_philosophy.
TMC2007 [Srivastava et al. 2005]: It is a subset of the Aviation Safety Reporting System dataset. It contains 28596 aviation safety free text reports that the fligth crew submit after each flight about events that took place during the flight. The goal is to label the documents with respect to what types of problem they describe. The dataset has 49060 discrete attributes corresponding to terms in the collection. The safety reports are provided with 22 labels, each of them representing a problem type that appears during a flight. Also the dataset TMC2007-500, which was obtained doing a features selection of the top-500, is included.
Virus [Xu et al. 2016]: This dataset is used to predict the sub-cellular locations of proteins according to their sequences. It contains 207 sequences for Virus species. Both the GO (Gene ontology) features and PseAAC (including 20 amino acid, 20 pseudo-amino acid and 400 diptide components) are provided. There are 6 subcellular locations (viral capsid, host cell membrane, host endoplasm reticulum, host cytoplasm, host nucleus and secreted).
Water quality [Blockeel et al. 1999]: This dataset is used to predict the quality of water of Slovenian rivers, knowing 16 characteristics such as the temperature, ph, hardness, NO2 or C02.
Yahoo [Ueda and Saito 2002]: It is a dataset to categorize web pages and consists of 14 top-level categories, each one is classified into a number of second-level categories. By focusing in second-level categories, there were used 11 out of the 14 independent text categorization problems.
Yeast [Elisseeff and Weston 2001]: This dataset contains micro-array expressions and phylogenetic profiles for 2417 yeast genes. Each gen is annotated with a subset of 14 functional categories (e.g. Metabolism, energy, etc.) of the top level of the functional catalogue.
Yelp [Sajnani et al. 2013]: This dataset has been obtained from the user’s reviews and ratings about business and services on Yelp. It is used in order to categorize if the food, service, ambiance, deals and price of one of these business are good or not. It contains more than 10000 reviews of users. This dataset has been downloaded from http://www.ics.uci.edu/~vpsaini/.
提供机构:
imodels
原始信息汇总
数据集概述
本数据集是对原Multi-Label Classification Dataset Repository的端口,包含32个CSV文件,每个文件的目标列名后缀为__target。数据集涵盖多个领域,包括文本、音频、音乐、医学、图像等,每个数据集都有详细的描述和特征指标。
数据集列表及特征
| 索引 | 数据集名称 | 领域 | 实例数(m) | 属性数(d) | 标签数(q) | 基数(Card) | 密度(Dens) | 多样性(Div) | 平均不平衡比(avgIR) | 依赖比(rDep) | 复杂度(m×q×d) |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 3s-bbc1000 | 文本 | 352 | 1000 | 6 | 1.125 | 0.188 | 0.234 | 1.718 | 0.733 | 2.11e+06 |
| 1 | 3s-guardian1000 | 文本 | 302 | 1000 | 6 | 1.126 | 0.188 | 0.219 | 1.773 | 0.667 | 1.81e+06 |
| 2 | 3s-inter3000 | 文本 | 169 | 3000 | 6 | 1.142 | 0.19 | 0.172 | 1.766 | 0.4 | 3.04e+06 |
| 3 | 3s-reuters1000 | 文本 | 294 | 1000 | 6 | 1.126 | 0.188 | 0.219 | 1.789 | 0.667 | 1.76e+06 |
| 4 | birds | 音频 | 645 | 260 | 19 | 1.014 | 0.053 | 0.206 | 5.407 | 0.123 | 3.19e+06 |
| 5 | cal500 | 音乐 | 502 | 68 | 174 | 26.044 | 0.15 | 1 | 20.578 | 0.192 | 5.94e+06 |
| 6 | chd_49 | 医学 | 555 | 49 | 6 | 2.58 | 0.43 | 0.531 | 5.766 | 0.267 | 163000 |
| 7 | corel16k001 | 图像 | 13770 | 500 | 153 | 2.859 | 0.019 | 0.349 | 34.155 | 0.142 | 1.05e+09 |
| 8 | corel16k002 | 图像 | 13760 | 500 | 164 | 2.882 | 0.018 | 0.354 | 37.678 | 0.128 | 1.13e+09 |
| 9 | corel16k003 | 图像 | 13760 | 500 | 154 | 2.829 | 0.018 | 0.35 | 37.058 | 0.137 | 1.06e+09 |
| 10 | corel16k004 | 图像 | 13840 | 500 | 162 | 2.842 | 0.018 | 0.351 | 35.899 | 0.126 | 1.12e+09 |
| 11 | corel16k005 | 图像 | 13850 | 500 | 160 | 2.858 | 0.018 | 0.364 | 34.936 | 0.133 | 1.11e+09 |
| 12 | corel16k006 | 图像 | 13860 | 500 | 162 | 2.885 | 0.018 | 0.361 | 33.398 | 0.128 | 1.12e+09 |
| 13 | corel16k007 | 图像 | 13920 | 500 | 174 | 2.886 | 0.017 | 0.371 | 37.715 | 0.12 | 1.21e+09 |
| 14 | corel16k008 | 图像 | 13860 | 500 | 168 | 2.883 | 0.017 | 0.357 | 36.2 | 0.121 | 1.16e+09 |
| 15 | corel16k009 | 图像 | 13880 | 500 | 173 | 2.93 | 0.017 | 0.373 | 36.446 | 0.119 | 1.2e+09 |
| 16 | corel16k010 | 图像 | 13620 | 500 | 144 | 2.815 | 0.02 | 0.345 | 32.998 | 0.147 | 9.81e+08 |
| 17 | corel5k | 图像 | 5000 | 499 | 374 | 3.522 | 0.009 | 0.635 | 189.568 | 0.03 | 9.33e+08 |
| 18 | emotions | 音乐 | 593 | 72 | 6 | 1.868 | 0.311 | 0.422 | 1.478 | 0.933 | 256000 |
| 19 | flags | 图像 | 194 | 19 | 7 | 3.392 | 0.485 | 0.422 | 2.255 | 0.381 | 25800 |
| 20 | foodtruck | 推荐系统 | 407 | 21 | 12 | 2.29 | 0.191 | 0.285 | 7.095 | 0.409 | 103000 |
| 21 | genbase | 生物学 | 662 | 1186 | 27 | 1.252 | 0.046 | 0.048 | 37.315 | 0.157 | 2.12e+07 |
| 22 | image | 图像 | 2000 | 294 | 5 | 1.236 | 0.247 | 0.625 | 1.193 | 0.9 | 2.94e+06 |
| 23 | mediamill | 视频 | 43910 | 120 | 101 | 4.376 | 0.043 | 0.149 | 256.405 | 0.342 | 5.32e+08 |
| 24 | scene | 图像 | 2407 | 294 | 6 | 1.074 | 0.179 | 0.234 | 1.254 | 0.933 | 4.25e+06 |
| 25 | stackex_chemistry | 文本 | 6961 | 540 | 175 | 2.109 | 0.012 | 0.436 | 56.878 | 0.056 | 6.58e+08 |
| 26 | stackex_chess | 文本 | 1675 | 585 | 227 | 2.411 | 0.011 | 0.644 | 85.79 | 0.03 | 2.22e+08 |
| 27 | stackex_cooking | 文本 | 10490 | 577 | 400 | 2.225 | 0.006 | 0.609 | 37.858 | 0.034 | 2.42e+09 |
| 28 | stackex_cs | 文本 | 9270 | 635 | 274 | 2.556 | 0.009 | 0.512 | 85.002 | 0.049 | 1.61e+09 |
| 29 | water-quality | 化学 | 1060 | 16 | 14 | 5.073 | 0.362 | 0.778 | 1.767 | 0.473 | 237000 |
| 30 | yeast | 生物学 | 2417 | 103 | 14 | 4.237 | 0.303 | 0.082 | 7.197 | 0.67 | 3.49e+06 |
| 31 | yelp | 文本 | 10810 | 671 | 5 | 1.638 | 0.328 | 1 | 2.876 | 0.7 | 3.63e+07 |
数据集描述
- 3sources: 包含948篇新闻文章,来自BBC、Reuters和The Guardian,涉及416个新闻故事,每个故事手动标注了六个主题标签之一。
- birds: 用于预测给定10秒音频片段中的鸟类物种。
- cal500: 包含502首歌曲,每首歌曲由至少三个人工标注者使用174个标签进行标注。
- corel5k: 基于5000张Corel图像,是一个流行的图像分类和标注基准。
- corel16k: 从ECCV 2002基准中派生,去除了出现频率较低的标签。
- emotions: 一个小型数据集,用于将音乐分类为引发的情绪。
- enron: 基于Enron电子邮件语料库的子集,标记有一组类别。
- foodtruck: 由407名调查参与者创建,描述了他们对食品卡车的个人偏好。
- genbase: 用于蛋白质功能分类的数据集,每个实例是一个蛋白质,每个标签是一个蛋白质类。
- image: 包含2000张图像,每张图像转换为294维特征向量。
- mediamill: 一个多媒体数据集,用于通用视频索引,包含85小时国际广播新闻数据。
- scene: 包含2407张图像,标注为最多6个类别。
- stackex: 从Stack Exchange论坛收集的六个数据集,包括化学、象棋、咖啡、烹饪、计算机科学和哲学。
- water-quality: 用于预测斯洛文尼亚河流的水质,基于16个特征。
- yeast: 包含2417个酵母基因的微阵列表达和系统发育概况,每个基因标注有14个功能类别之一。
- yelp: 从Yelp获取的用户评论和评分数据集,用于分类食品、服务、氛围、交易和价格。
特征指标解释
- 实例数(m): 数据集中的样本数量。
- 属性数(d): 每个样本的特征数量。
- 标签数(q): 数据集中的类别数量。
- 基数(Card): 每个实例平均关联的标签数。
- 密度(Dens): 基数除以标签数。
- 多样性(Div): 数据集中存在的标签集百分比除以可能的标签集数。
- 平均不平衡比(avgIR): 所有标签的平均不平衡程度,avgIR越大,数据集的不平衡程度越高。
- 依赖比(rDep): 通过卡方检验,99%置信度下标签对之间的依赖比例。
- 复杂度(m×q×d): 数据集的复杂度,定义为实例数、标签数和属性数的乘积。
搜集汇总
数据集介绍
构建方式
该数据集是对Multi-Label Classification Dataset Repository的移植,主要涵盖了多标签分类任务。数据集从原始资源中转换成了简单的csv格式,总计32个csv文件,以便于Python环境中的解析和使用。每个csv文件中的目标标签均以__target后缀标识,方便模型的训练和评估。
使用方法
用户可以根据自己的研究任务选择合适的数据集进行下载和使用。数据集以csv格式存储,可以直接导入Python环境进行数据处理和模型训练。对于每个数据集,用户可以参考其描述性统计信息,了解其基本特征和适用场景。此外,数据集还提供了相应的特征选择方法和分区方法,用户可以根据需要进行调整和优化。
背景与挑战
背景概述
多任务表格数据集(imodels/multitask-tabular-datasets)是一个综合性的数据集,它汇聚了来自多个领域的多标签分类数据。这些数据集涵盖了文本、音频、音乐、医学、图像、推荐系统、生物学、化学等多个领域,为多任务学习提供了丰富的资源。该数据集的创建基于多标签分类数据集仓库的移植,其原始数据集来自多个不同的来源,包括新闻、社交网络、医学文献等。数据集的创建旨在解决多标签分类问题,即一个实例可能属于多个类别。这对于机器学习和数据挖掘领域的研究具有重要意义,因为它可以帮助我们更好地理解和预测复杂的现象。此外,该数据集还为研究人员提供了一个平台,用于开发新的算法和技术,以解决多标签分类问题。
当前挑战
尽管多任务表格数据集提供了丰富的资源,但它也面临着一些挑战。首先,由于数据集来自多个不同的领域,因此它们可能具有不同的特性,这给数据预处理和模型训练带来了困难。其次,多标签分类问题本身就是一个复杂的任务,需要考虑到标签之间的依赖关系和实例之间的相似性。此外,随着数据量的增加,模型的训练时间和复杂度也会增加,这给计算资源带来了压力。因此,如何有效地处理这些挑战,并开发出高性能的多标签分类算法,是该领域的研究重点。
常用场景
经典使用场景
在多标签分类领域,imodels/multitask-tabular-datasets 数据集被广泛应用于模型训练和评估。该数据集涵盖了多个领域的多标签数据,包括文本、音频、音乐、医学、生物学、化学、图像等,为研究人员提供了丰富的多标签分类任务场景。通过在这些数据集上进行模型训练,研究者可以评估和比较不同多标签分类算法的性能,从而推动该领域的发展。
解决学术问题
imodels/multitask-tabular-datasets 数据集解决了多标签分类任务中数据稀缺的问题。在多标签分类任务中,数据集通常需要包含多个标签,而现实世界中的数据往往难以获取。该数据集提供了大量的多标签数据,使得研究人员可以更方便地进行模型训练和评估,从而推动了多标签分类领域的研究。
实际应用
imodels/multitask-tabular-datasets 数据集在实际应用中具有广泛的应用场景。例如,在文本分类任务中,可以使用该数据集训练模型,对新闻文章、社交媒体帖子等进行分类,从而帮助用户快速找到他们感兴趣的内容。在图像分类任务中,可以使用该数据集训练模型,对照片、视频等进行分类,从而实现智能相册、视频推荐等功能。此外,该数据集还可以应用于推荐系统、情感分析等领域。
数据集最近研究
最新研究方向
在当前的多任务表格数据集研究中,一个前沿方向是探索如何有效地整合来自不同领域的多源数据,以实现更准确和全面的预测模型。例如,将文本、音频、图像和视频等多种类型的数据集进行融合,可以构建更加复杂和精细的模型,从而更好地理解和预测现实世界中的各种现象。此外,针对不同领域的数据特点,如何设计和优化算法以适应不同类型的数据集,也是当前研究的热点。例如,在医疗领域中,如何利用多任务学习来预测疾病的诊断和治疗方案,在推荐系统中,如何利用多源数据来提高推荐的准确性和个性化程度。这些研究方向不仅有助于推动多任务学习在各个领域的应用,也为未来的研究提供了新的思路和方向。
以上内容由遇见数据集搜集并总结生成


