grpo-style-training
收藏Hugging Face2026-02-03 更新2026-02-05 收录
下载链接:
https://huggingface.co/datasets/VibrantVista/grpo-style-training
下载链接
链接失效反馈官方服务:
资源简介:
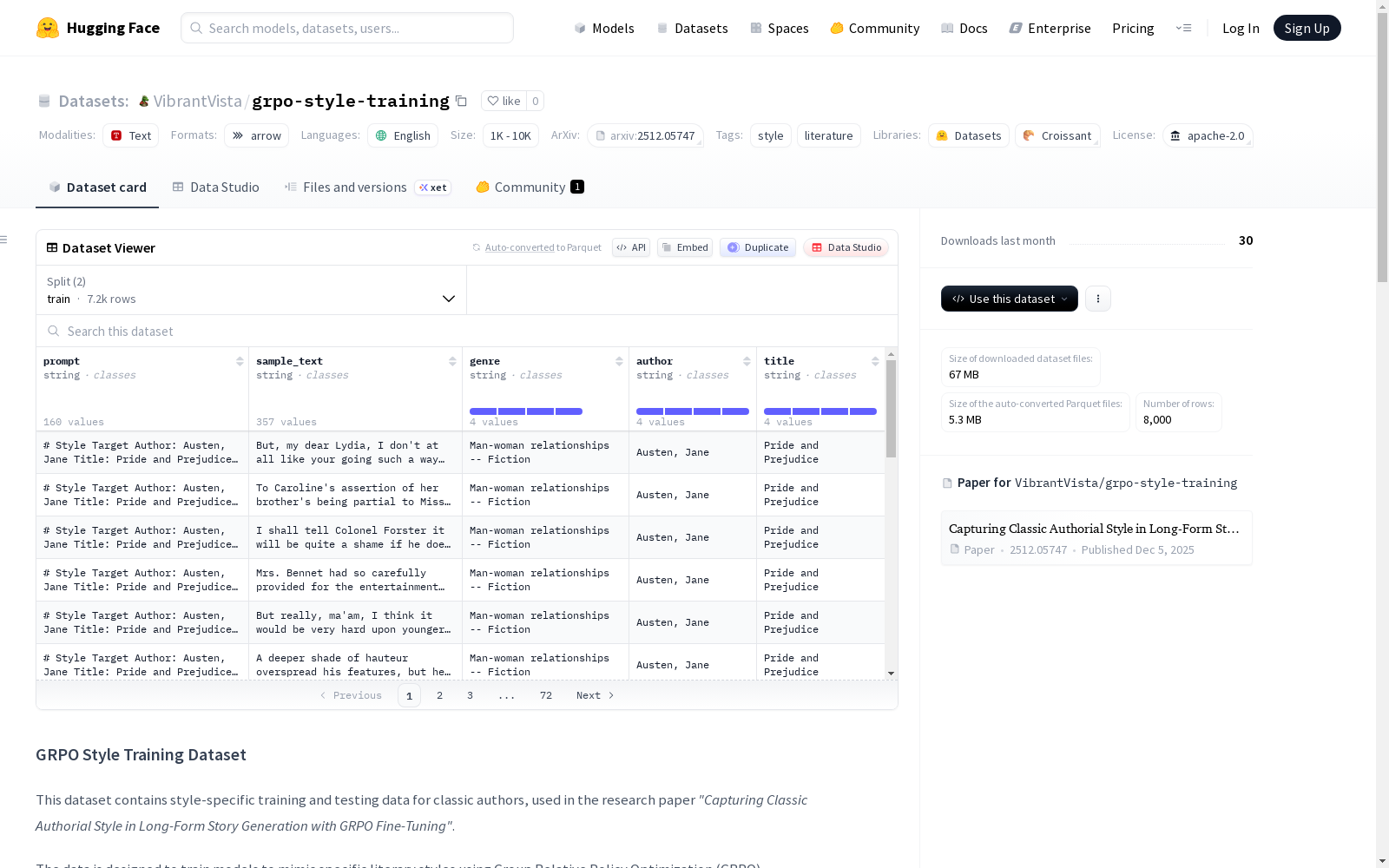
GRPO风格训练数据集包含用于经典作家的风格特定训练和测试数据,旨在通过组相对策略优化(GRPO)训练模型以模仿特定的文学风格。数据集按作者文件夹组织,每个作者文件夹内包含独立的`train`和`test`子目录,存储为`.arrow`文件。可用的作者包括简·奥斯汀、查尔斯·狄更斯、马克·吐温和托马斯·哈代。数据集适用于文学风格模仿和长篇小说生成等任务,规模在1K到10K样本之间,语言为英语。
The GRPO-style training dataset contains style-specific training and test data for classic literary authors, which is designed to train models to mimic specific literary styles via Group Relative Policy Optimization (GRPO). The dataset is organized into author-specific folders, each of which contains separate `train` and `test` subdirectories storing data in the .arrow file format. The available authors include Jane Austen, Charles Dickens, Mark Twain, and Thomas Hardy. This dataset is suitable for tasks such as literary style imitation and long-form novel generation, with a size ranging from 1K to 10K samples, and all data is in English.
创建时间:
2026-02-02
搜集汇总
数据集介绍
构建方式
在文学风格建模领域,GRPO风格训练数据集为经典作家风格模仿提供了专门资源。该数据集依据四位经典作家——简·奥斯汀、查尔斯·狄更斯、马克·吐温和托马斯·哈代——的文学作品构建而成,通过精心划分训练与测试子集,并以Arrow文件格式分作者目录存储。其构建过程旨在支持基于群体相对策略优化的风格微调研究,为长篇小说生成中的作者风格捕捉任务奠定数据基础。
特点
该数据集的核心特点在于其针对性强且结构清晰。它专注于四位具有鲜明文学风格的经典作家,为每种风格提供了独立的训练与测试数据分区,便于进行精准的风格建模与评估。数据以高效的Arrow格式存储,不仅提升了读写性能,也确保了大规模文本处理时的流畅性。这种按作者组织的配置方式,使得研究者能够灵活地针对单一风格进行深入分析,或进行跨风格的对比研究。
使用方法
使用该数据集时,需通过Hugging Face的`datasets`库并指定Arrow构建器进行加载。推荐的方法是针对特定作者,通过设置`data_dir`参数指向对应的作者数据目录,从而自动获取该作者的训练集和测试集。若需加载全部四位作者的数据,则需遍历作者列表并分别加载每个配置。这种设计确保了数据访问的模块化与清晰性,方便用户将其直接集成到基于GRPO或其他风格微调方法的模型训练流程中。
背景与挑战
背景概述
在自然语言生成领域,模仿特定作者的文学风格一直是极具吸引力的研究方向,它不仅关乎文本的表面特征,更涉及对叙事结构、词汇偏好和修辞手法的深层捕捉。GRPO Style Training数据集应运而生,专为支持2025年发表的论文《Capturing Classic Authorial Style in Long-Form Story Generation with GRPO Fine-Tuning》而构建。该数据集由Jinlong Liu、Mohammed Bahja、Venelin Kovatchev和Mark Lee等研究人员创建,旨在通过群组相对策略优化技术,训练模型精准复现简·奥斯汀、查尔斯·狄更斯、马克·吐温和托马斯·哈代这四位经典文学巨匠的独特文风。其核心研究问题聚焦于长篇幅故事生成中作者风格的连贯性与保真度,为计算文体学和创意写作辅助工具的发展提供了关键数据支撑。
当前挑战
该数据集致力于解决文学风格建模这一复杂任务,其首要挑战在于如何从有限且非结构化的原始文本中,系统性地提取并量化作者风格的细微差异,例如句法模式、情感基调和时代特定用语。构建过程中的挑战则体现在数据预处理阶段,需要将不同作者的著作进行高质量的分割与对齐,确保训练和测试集既能代表各自的风格特征,又避免内容重叠导致的评估偏差。此外,将异构的文学材料转换为统一的Arrow格式并分作者组织,也要求精心的工程设计与一致性维护,以支持高效的模型训练与验证流程。
常用场景
经典使用场景
在自然语言生成领域,模仿特定作家的文学风格一直是文本生成研究的重要方向。GRPO风格训练数据集专为这一目标设计,其经典使用场景在于训练语言模型学习并复现经典作家的独特文风,例如简·奥斯汀的细腻心理描写或马克·吐温的幽默讽刺笔触。研究者通过加载特定作者的训练数据,利用分组相对策略优化算法对模型进行微调,使生成的叙事文本在词汇选择、句式结构和叙事节奏上贴近目标作家的风格特征,为长文本故事生成提供了风格可控的基准数据。
衍生相关工作
围绕该数据集及其对应论文,已衍生出一系列聚焦于作者风格建模的经典研究工作。这些工作主要沿两个方向拓展:一是方法论的改进,例如探索更高效的风格表示学习架构、将GRPO与其他元学习或对比学习框架结合以提升风格捕获的精度与泛化能力;二是应用场景的延伸,包括将风格控制技术迁移至其他类型作家或现代文本风格、研究多风格混合生成、以及评估生成文本在风格维度上的可解释性与人文价值,共同丰富了计算风格学的研究图谱。
数据集最近研究
最新研究方向
在自然语言生成领域,模仿经典作家的独特文学风格已成为一项前沿挑战。该数据集围绕简·奥斯汀、查尔斯·狄更斯等四位文学巨匠的文本构建,旨在通过群体相对策略优化方法,推动模型在长篇故事生成中精准捕捉并复现作者特有的叙事语调、句式结构与情感色彩。当前研究热点集中于利用此类风格化数据,探索大语言模型在创意写作、个性化内容生成及数字人文领域的应用潜力,其进展不仅深化了对文本风格可计算性的理解,也为人工智能辅助文学创作与风格分析提供了重要实验基础。
以上内容由遇见数据集搜集并总结生成


