Dharma-AI/DharmaOCR-Benchmark
收藏Hugging Face2026-05-05 更新2026-05-10 收录
下载链接:
https://hf-mirror.com/datasets/Dharma-AI/DharmaOCR-Benchmark
下载链接
链接失效反馈官方服务:
资源简介:
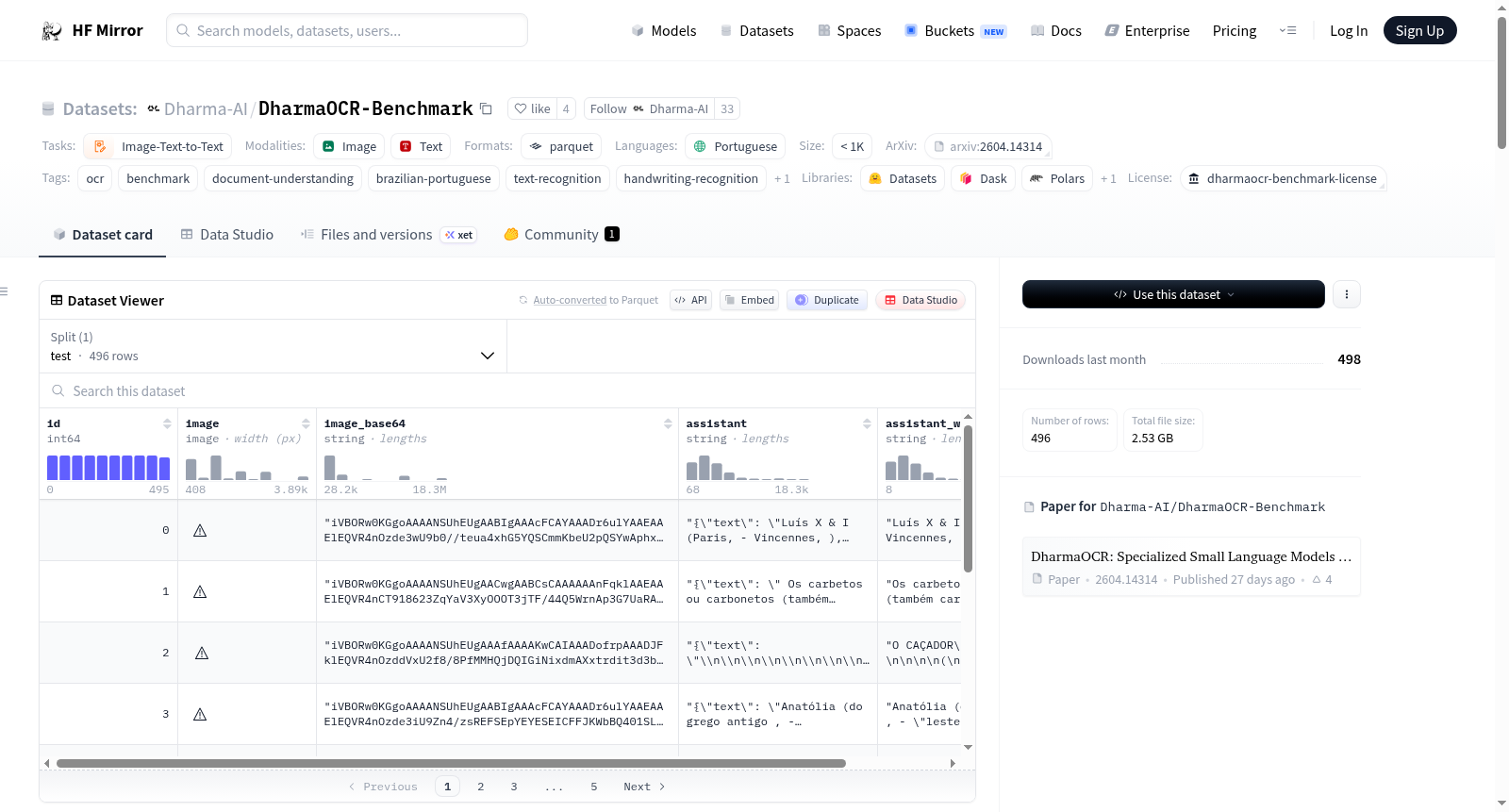
DharmaOCR-Benchmark是一个包含496个实例的评估套件,专注于巴西葡萄牙语文档的OCR模型。它涵盖了印刷文本、手写文本和法律/行政文档,这些领域在现有基准测试(如OCRBench和olmOCR-Bench)中代表性不足。该基准测试不仅评估转录质量,还将文本退化率和单位推理成本作为首要指标。数据集分为三个子集:ESTER-Pt(363个样本,巴西葡萄牙语印刷文本识别)、Legal(83个样本,法律和行政文档)和BRESSAY(50个样本,巴西葡萄牙语手写文本识别)。评估协议包括基于LevenshteinRatio和BLEU的复合分数,以及文本退化率和每页单位成本等附加指标。
DharmaOCR-Benchmark is a 496-instance evaluation suite for OCR models focused on Brazilian Portuguese documents. It covers printed text, handwritten text, and legal/administrative documents — domains underrepresented in existing benchmarks like OCRBench and olmOCR-Bench. This benchmark evaluates not only transcription quality, but also text degeneration rate and unit inference cost as first-class metrics. The dataset is composed of three subsets: ESTER-Pt (363 samples, printed text recognition in Brazilian Portuguese), Legal (83 samples, legal and administrative documents), and BRESSAY (50 samples, handwritten text recognition in Brazilian Portuguese). The evaluation protocol includes a composite score based on LevenshteinRatio and BLEU, along with additional metrics like text degeneration rate and unit cost per page.
提供机构:
Dharma-AI
搜集汇总
数据集介绍
构建方式
DharmaOCR-Benchmark 是一个针对巴西葡萄牙语文档的OCR模型评估套件,专为填补现有基准在语言特异性、领域词汇和文档格式上的空白而构建。该数据集整合了496个测试样本,细分为三个子集:ESTER-Pt包含363个印刷文本识别样本,Legal涵盖83个经过人工审核的法律与行政文档,BRESSAY则贡献了50个手写文本识别样本。所有样本均来自公开来源并经人工仔细校验,确保了标注的高质量与评估的可靠性。数据集以JSON格式存储,包含图像、图像Base64编码、助手响应及去除JSON格式的助手响应等字段,便于灵活调用。
特点
该基准的独特之处在于不仅评估转录质量,还将文本退化率和单位推理成本作为一等指标进行度量。其综合得分通过LevenshteinRatio与BLEU的均值计算,前者反映字符级保真度,后者衡量n-gram序列的保留程度。文本退化率统计了达到输出令牌上限且出现重复文本片段的请求比例,是一项关键的运营指标。此外,基准提供了每页单位成本数据,支持自托管模型与商业API间的公平比对。评测配置统一采用NVIDIA L40S GPU、vLLM推理引擎及零温度设置,确保了结果的可复现性。
使用方法
该数据集在使用上极为便捷,用户可通过HuggingFace的datasets库直接加载。只需执行一行Python代码`from datasets import load_dataset; dataset = load_dataset('dharma-ai/DharmaOCR-Benchmark')`,即可获取预划分好的测试集。每个实例包含图像及其对应的文本转录,用户可通过比较模型输出与助理响应来计算LevenshteinRatio和BLEU分数,进而求得综合得分。建议在评估时遵循基准的推理参数设置,包括8192的最大输出令牌数和0的温度,以保持结果的一致性。该基准已附带详细的评估协议与参考结果,便于研究者复现与对比。
背景与挑战
背景概述
DharmaOCR-Benchmark是2026年由Dharma-AI团队开发的巴西葡萄牙语文档OCR评测基准。该团队由Gabriel Pimenta de Freitas Cardoso等人组成,旨在填补当前OCR评测在低资源语言领域的空白。现有OCRBench等基准主要针对英语文档,未能有效反映葡语特有的正字法、领域词汇及文档格式带来的性能偏移。该基准专注于三类文档场景:打印文本(ESTER-Pt子集363例)、手写文本(BRESSAY子集50例)及法律行政文档(Legal子集83例),总计496个精心标注的测试样本。作为与DharmaOCR模型系列配套发布的评测工具,它首次将文本退化率和单位推理成本纳入核心评估指标,为OCR模型在特定语言领域的实际部署提供了更全面的性能标尺。
当前挑战
该基准主要应对两大核心挑战。领域层面,巴西葡萄牙语文档的OCR识别面临独特难题:语言特有的重音符号、连字和缩写词等正字法特征极易被通用OCR模型误识别或遗漏,法律文档中复杂的段落结构、表格和印章进一步加剧了转录难度,而手写文本则因字体多样性、书写风格差异及背景噪声导致识别率大幅下降。构建过程中,团队须确保所有文档样本经过严格的人工审核以避免标注噪声,同时设计出一种既能捕捉字符级误差(通过Levenshtein比率)又能反映序列保真度(通过BLEU分数)的综合评分机制。此外,定义并量化文本退化率——即模型因输出长度限制而产生重复文本片段的现象——成为评估推理稳定性和成本效率的技术难点。
常用场景
经典使用场景
在光学字符识别(OCR)领域,DharmaOCR-Benchmark是一个专为巴西葡萄牙语文档设计的评估基准,涵盖印刷文本、手写文本以及法律行政文档三大子集,共计496个实例。它被广泛用于衡量OCR模型在低资源语言场景下的转录质量、文本退化率与推理成本。该基准的出现弥补了现有评估工具如OCRBench和olmOCR-Bench在非英语、非通用文档布局上的不足,为研究者提供了一个聚焦于葡萄牙语正字法、领域词汇与格式特性的标准化评测协议。
衍生相关工作
基于DharmaOCR-Benchmark的评估框架,研究团队同步发布了DharmaOCR模型系列(包括Full 7B与Lite 3B版本),并在该基准上取得了最优成绩。相关论文《DharmaOCR: Specialized Small Language Models for Structured OCR that Outperform Open-Source and Commercial Baselines》系统阐述了专门化小语言模型在结构化OCR中的优势。该基准还激发了后续针对低资源语言与退化文本检测模型的比较研究工作,成为葡萄牙语OCR社区的重要参考标准。
数据集最近研究
最新研究方向
当前,光学字符识别领域正从通用场景识别转向低资源语言与垂直领域文档的精细化评估。DharmaOCR-Benchmark的推出,精准填补了巴西葡萄牙语印刷体、手写体及法律行政文档在标准化评测中的空白。该基准不仅引入文本退化率与单位推理成本作为关键指标,更揭示了语言特异性正字法与领域词汇对模型误差分布的深刻影响。其评测结果表明,轻量级专用小模型可在特定语种文档理解任务中超越通用大模型与商业API,为OCR技术向高精度、低成本、可复现的行业落地提供了全新范式和实证基础。
以上内容由遇见数据集搜集并总结生成


