GreatSplicing
收藏arXiv2023-10-23 更新2024-07-24 收录
下载链接:
http://www.greatsplicing.net
下载链接
链接失效反馈官方服务:
资源简介:
GreatSplicing是由重庆邮电大学创建的一个高质量手动合成数据集,包含5000张拼接图像,覆盖335个不同的语义类别。该数据集通过Adobe Photoshop手动创建,确保了拼接痕迹的真实性和高分辨率。GreatSplicing旨在帮助神经网络更好地学习拼接痕迹,提高跨数据集检测能力,适用于图像认证领域,解决现有数据集在语义多样性不足和检测模型过拟合问题。
GreatSplicing is a high-quality manually synthesized dataset developed by Chongqing University of Posts and Telecommunications. It contains 5,000 spliced images covering 335 distinct semantic categories. Manually created via Adobe Photoshop, the dataset ensures the authenticity of splicing traces and high-resolution quality. The dataset aims to help neural networks better learn splicing traces and improve cross-dataset detection capabilities, which is applicable to the field of image authentication and solves the problems of insufficient semantic diversity and detection model overfitting in existing datasets.
提供机构:
重庆邮电大学
创建时间:
2023-10-16
搜集汇总
数据集介绍
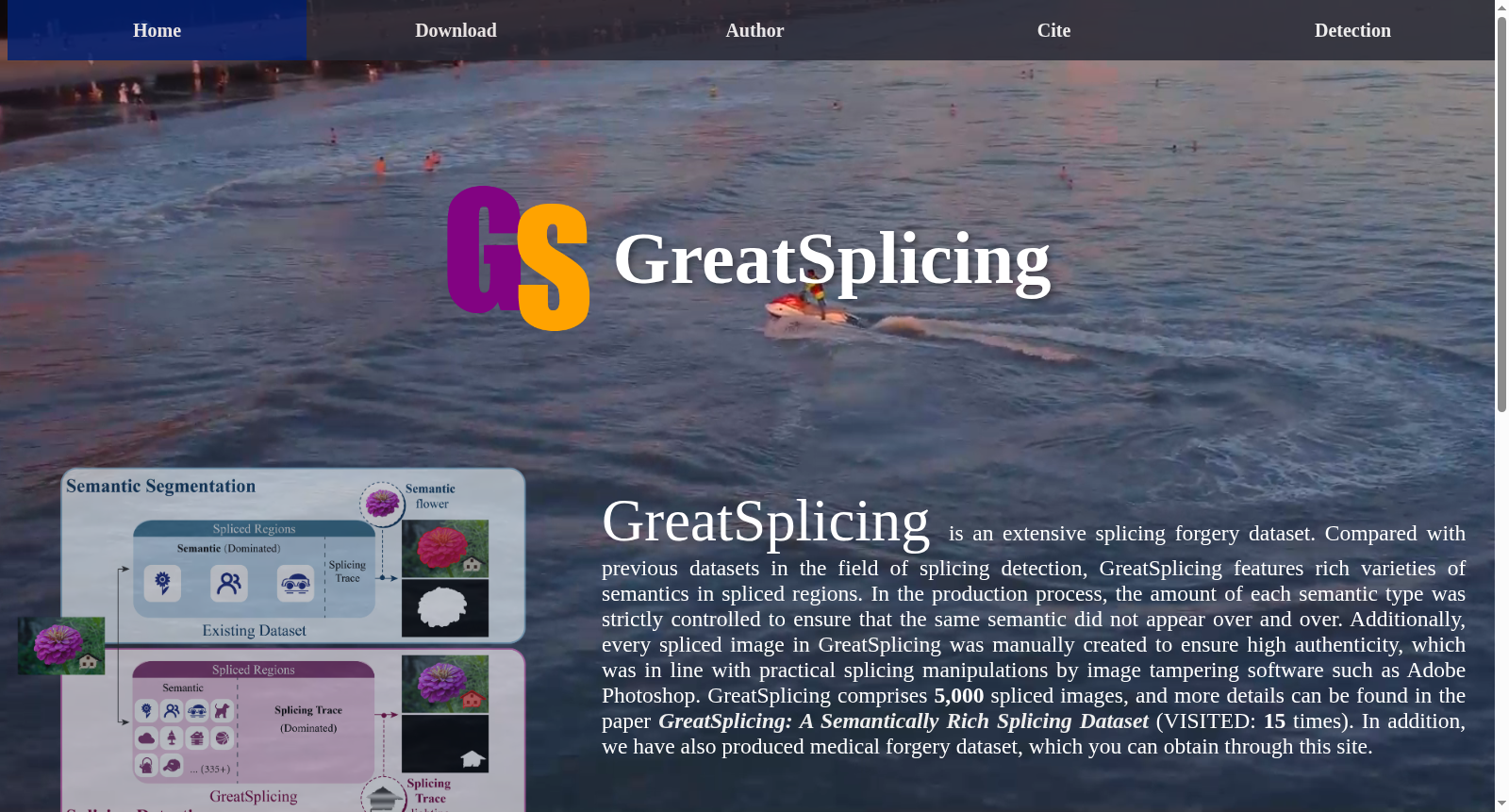
构建方式
GreatSplicing数据集基于BossBase原始图像库构建,采用Adobe Photoshop进行人工拼接操作,全程避免自动化机制以保留真实拼接痕迹。制作流程包括:从BossBase中选取两张未使用过的图像分别作为前景与背景来源;对二者依次应用缩放、旋转、扭曲、色彩调整等图像处理操作;利用选框、套索、魔棒、钢笔及快速选择工具提取前景区域并粘贴至背景,保存为PNG格式;通过混合选项中的颜色叠加生成二值掩膜作为真值。最终产出5000张拼接图像,其中包含2887张语义对象感知型与2113张形状随机型样本,并记录每张图像的源图像索引、拼接区域语义类别、图像处理操作及连通区域数量等元信息。
使用方法
为促进公平比较,数据集提供了五种推荐实验设置:自足模式将数据集划分为训练集与测试集,不引入任何额外技巧;跨数据集验证模式使用全部GreatSplicing作为训练集,其他数据集作为测试集;合成微调模式允许在合成数据集上预训练后,在GreatSplicing上进行微调;大样本模式通过对训练集进行数据增强生成大量样本;真实图像引入模式将BossBase中的真实图像加入训练集。所有图像需统一缩放至448×608分辨率并保存为PNG格式,可直接用于端到端的拼接检测网络训练与评估,数据集可从www.greatsplicing.net免费获取用于研究目的。
背景与挑战
背景概述
在图像取证领域,拼接伪造作为一种篡改图像局部语义信息而保留整体真实感的传统手段,始终是恶意用户频繁利用的技术。然而,现有拼接数据集普遍存在拼接区域语义类别匮乏的缺陷,导致基于神经网络的检测模型容易过拟合语义特征而非拼接痕迹,严重制约了模型在跨数据集场景下的泛化能力。为应对这一困局,重庆邮电大学的Bi Xiuli与Liang Jiaming于2023年提出了GreatSplicing数据集。该数据集以BossBase为基底,经由Adobe Photoshop手工精心制作5,000张拼接图像,涵盖335种截然不同的语义类别,充分弥补了现有数据集语义多样性不足的短板。GreatSplicing的提出不仅推动了拼接痕迹学习的研究进程,亦为领域内实验设置的公平性奠定了坚实基础。
当前挑战
GreatSplicing所面临的挑战主要源自两方面。其一,在领域问题层面,现有拼接数据集(如CASIA、DEFACTO、NIST16等)中拼接区域的语义类别极为有限,导致网络训练时容易提取天空、人物等特定语义作为判别依据,而非真正的拼接痕迹;这一缺陷使得模型在检测真实场景或跨数据集时出现严重的误识别与检测性能下降。其二,在构建过程中,为确保拼接图像的高度真实感与标准化,GreatSplicing完全依赖人工操作,摒弃自动化生成机制,这要求制作者在图像选取、剪切工具使用、色彩调整与拼接融合等环节中保持严谨一致,极大增加了数据集的制作难度与时间成本。同时,如何平衡目标感知拼接图像与形状随机拼接图像的分布比例,亦是对数据集构建质量的严峻考验。
常用场景
经典使用场景
在图像取证领域,拼接伪造检测一直是研究的热点与难点。GreatSplicing数据集以其丰富的语义类别和高度逼真的拼接图像,成为训练和评估深度学习模型在拼接痕迹学习上的经典基准。其最经典的使用场景是作为训练集,用于端到端的拼接区域定位任务。研究者利用该数据集中的对象感知与形状随机两类拼接图像,结合U-Net、RRU-Net等分割网络,训练模型精准区分拼接区域与背景。该场景下,数据集的335种语义类别有效避免了模型对特定语义的过拟合,促使其专注于学习普适性的拼接痕迹,从而显著提升检测的泛化能力。
解决学术问题
现有拼接数据集普遍存在拼接区域语义类别匮乏的问题,导致训练出的检测模型过度依赖语义特征而非真实的拼接痕迹,在跨数据集测试中表现欠佳,且对真实图像存在严重的误检。GreatSplicing通过引入335种语义类别,从根本上解决了这一学术困境。它使得神经网络能够摒弃语义干扰,专注于学习拼接操作留下的细微痕迹,如边缘伪影、色彩不一致等。实验证明,基于GreatSplicing训练的模型在误检率上趋近于零,同时在跨数据集检测任务中,其F1分数与IoU指标均显著优于基于其他数据集训练的模型。这一突破推动了拼接检测领域评估标准的统一与公平,为后续研究奠定了坚实的实验基础。
实际应用
在数字媒体取证的实际应用中,GreatSplicing展现出巨大的实用价值。它可被用于开发高效的自动化图像真伪鉴别系统,服务于新闻机构、司法鉴定、社交媒体平台等场景。例如,在新闻图片审核中,基于该数据集训练的模型能够快速识别图像中是否存在恶意拼接篡改,防止虚假信息传播。在司法取证中,它可辅助鉴定人员定位图像中的拼接区域,为案件提供关键证据。此外,该数据集的高分辨率与真实感使其适用于移动端或云端部署的轻量化检测工具,满足实时性与准确性的双重要求,从而在维护数字内容可信度方面发挥不可替代的作用。
数据集最近研究
最新研究方向
当前图像拼接伪造检测领域的前沿研究正聚焦于解决现有数据集语义多样性匮乏这一核心瓶颈。GreatSplicing数据集应运而生,其核心突破在于手动构建了涵盖335种语义类别的拼接区域,远超以往数据集,有效避免了检测模型对特定语义特征的过拟合。该数据集基于高分辨率、真实场景的BossBase图像库,通过标准化流程生成,确保了拼接痕迹的真实性与完整性。围绕GreatSplicing,研究界正探索多种标准化实验范式,如自足模式与跨数据集验证,旨在建立公平、可复现的评测基准。这一工作不仅显著降低了模型对真实图像的误检率,更提升了跨数据集的泛化能力,为应对日益复杂的图像篡改挑战提供了坚实的数据基石与评估框架,推动了取证技术从实验室环境向现实应用的实质性跨越。
相关研究论文
- 1GreatSplicing: A Semantically Rich Splicing Dataset重庆邮电大学 · 2023年
以上内容由遇见数据集搜集并总结生成


