jiacheng-ye/logiqa-zh
收藏Hugging Face2023-04-21 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/jiacheng-ye/logiqa-zh
下载链接
链接失效反馈官方服务:
资源简介:
---
task_categories:
- question-answering
language:
- zh
pretty_name: LogiQA-zh
size_categories:
- 1K<n<10K
paperswithcode_id: logiqa
dataset_info:
features:
- name: context
dtype: string
- name: query
dtype: string
- name: options
sequence:
dtype: string
- name: correct_option
dtype: string
splits:
- name: train
num_examples: 7376
- name: validation
num_examples: 651
- name: test
num_examples: 651
---
# Dataset Card for LogiQA
## Dataset Description
- **Homepage:**
- **Repository:**
- **Paper:**
- **Leaderboard:**
- **Point of Contact:**
### Dataset Summary
LogiQA is constructed from the logical comprehension problems from publically available questions of the National Civil Servants Examination of China, which are designed to test the civil servant candidates’ critical thinking and problem solving. This dataset includes the Chinese versions only.
## Dataset Structure
### Data Instances
An example from `train` looks as follows:
```
{'context': '有些广东人不爱吃辣椒.因此,有些南方人不爱吃辣椒.',
'query': '以下哪项能保证上述论证的成立?',
'options': ['有些广东人爱吃辣椒',
'爱吃辣椒的有些是南方人',
'所有的广东人都是南方人',
'有些广东人不爱吃辣椒也不爱吃甜食'],
'correct_option': 2}
```
### Data Fields
- `context`: a `string` feature.
- `query`: a `string` feature.
- `answers`: a `list` feature containing `string` features.
- `correct_option`: a `string` feature.
### Data Splits
|train|validation|test|
|----:|---------:|---:|
| 7376| 651| 651|
## Additional Information
### Dataset Curators
The original LogiQA was produced by Jian Liu, Leyang Cui , Hanmeng Liu, Dandan Huang, Yile Wang, and Yue Zhang.
### Licensing Information
[More Information Needed]
### Citation Information
```
@article{liu2020logiqa,
title={Logiqa: A challenge dataset for machine reading comprehension with logical reasoning},
author={Liu, Jian and Cui, Leyang and Liu, Hanmeng and Huang, Dandan and Wang, Yile and Zhang, Yue},
journal={arXiv preprint arXiv:2007.08124},
year={2020}
}
```
### Contributions
[@jiacheng-ye](https://github.com/jiacheng-ye) added this Chinese dataset.
[@lucasmccabe](https://github.com/lucasmccabe) added the English dataset.
task_categories:
- 问答(question-answering)
language:
- 中文(zh)
pretty_name: LogiQA-zh
size_categories:
- 样本量介于1000至10000之间(1K<n<10K)
paperswithcode_id: logiqa
dataset_info:
features:
- name: 上下文(context)
dtype: 字符串(string)
- name: 查询(query)
dtype: 字符串(string)
- name: 选项(options)
sequence:
dtype: 字符串(string)
- name: 正确选项(correct_option)
dtype: 字符串(string)
splits:
- name: 训练集(train)
num_examples: 7376
- name: 验证集(validation)
num_examples: 651
- name: 测试集(test)
num_examples: 651
---
# LogiQA 数据集卡片
## 数据集说明
- **主页:** 无
- **代码仓库:** 无
- **相关论文:** 无
- **排行榜:** 无
- **联系人:** 无
### 数据集概述
LogiQA 源自中国国家公务员考试公开的逻辑理解类试题,此类试题旨在考查公务员招录考生的批判性思维与问题解决能力。本数据集仅包含中文版本。
## 数据集结构
### 数据样例
训练集的一条样例如下:
{'context': '有些广东人不爱吃辣椒。因此,有些南方人不爱吃辣椒。',
'query': '以下哪项能保证上述论证的成立?',
'options': ['有些广东人爱吃辣椒',
'爱吃辣椒的有些是南方人',
'所有的广东人都是南方人',
'有些广东人不爱吃辣椒也不爱吃甜食'],
'correct_option': 2}
### 数据字段
- `context`: 字符串型特征。
- `query`: 字符串型特征。
- `answers`: 包含字符串元素的列表型特征。
- `correct_option`: 字符串型特征。
### 数据划分
| 训练集(train) | 验证集(validation) | 测试集(test) |
|----------------:|-------------------:|--------------:|
| 7376 | 651 | 651 |
## 附加信息
### 数据集主创人员
原版 LogiQA 数据集由 Jian Liu、Leyang Cui、Hanmeng Liu、Dandan Huang、Yile Wang、Yue Zhang 共同构建。
### 许可信息
[需补充更多信息]
### 引用信息
@article{liu2020logiqa,
title={LogiQA: A challenge dataset for machine reading comprehension with logical reasoning},
author={Liu, Jian and Cui, Leyang and Liu, Hanmeng and Huang, Dandan and Wang, Yile and Zhang, Yue},
journal={arXiv preprint arXiv:2007.08124},
year={2020}
}
### 贡献信息
[@jiacheng-ye](https://github.com/jiacheng-ye) 贡献了本中文数据集。
[@lucasmccabe](https://github.com/lucasmccabe) 贡献了英文数据集。
提供机构:
jiacheng-ye
原始信息汇总
数据集概述
- 名称: LogiQA-zh
- 任务类别: 问答(question-answering)
- 语言: 中文(zh)
- 大小: 1K<n<10K
- 论文代码ID: logiqa
数据集结构
数据实例
- 字段:
context: 字符串类型query: 字符串类型options: 字符串序列correct_option: 字符串类型
数据分割
| 分割 | 示例数量 |
|---|---|
| train | 7376 |
| validation | 651 |
| test | 651 |
数据集来源
- 来源: 中国国家公务员考试公开题目
- 目的: 测试公务员候选人的批判性思维和问题解决能力
贡献者
- 中文数据集添加者: @jiacheng-ye
- 英文数据集添加者: @lucasmccabe
搜集汇总
数据集介绍
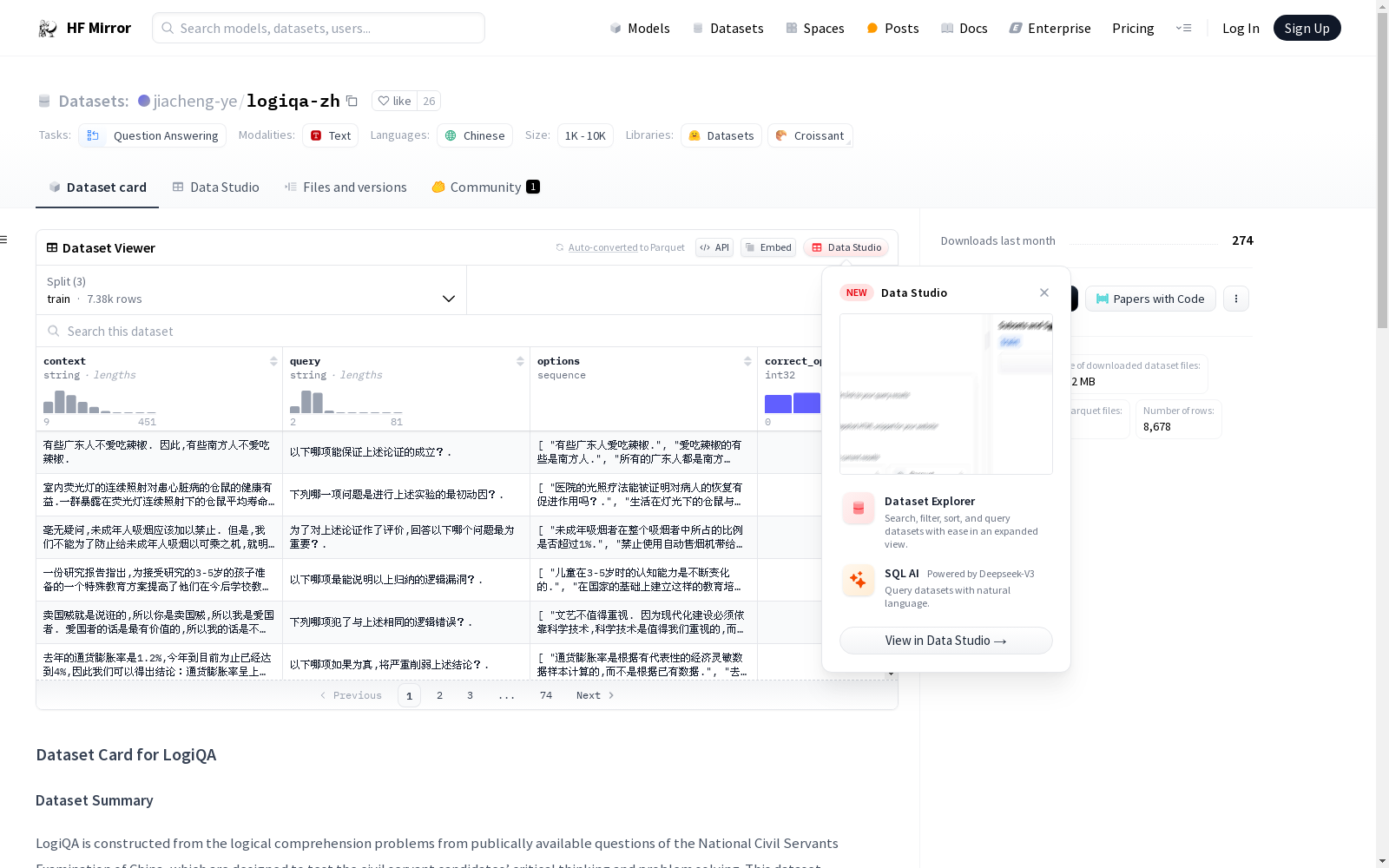
构建方式
LogiQA-zh数据集的构建,旨在从中国公务员考试的逻辑推理问题中,提炼出符合逻辑理解测试的题目。该数据集的构建,精选自公开的考试题目,并经过严格的数据清洗与格式化处理,形成了包含上下文、问题、选项及正确答案的结构化数据实例。
特点
LogiQA-zh数据集的特点在于,其内容均源于具有实际应用背景的公务员考试逻辑题,具备较高的实用性和挑战性。数据集涵盖了训练集、验证集和测试集,每个数据实例都包括一个上下文、一个问题、一组选项以及一个正确选项,适合用于评估机器在逻辑推理方面的理解和处理能力。
使用方法
使用LogiQA-zh数据集,用户可以根据数据集提供的 splits 进行模型的训练、验证和测试。数据集以JSON格式存储,其中每个实例均为一个包含上下文、问题、选项及正确答案的字典结构,便于直接加载和应用至机器阅读理解与逻辑推理相关的任务中。
背景与挑战
背景概述
LogiQA-zh数据集,源于我国公务员考试的逻辑推理题目,由刘建等研究人员于2020年构建,旨在评估候选人的批判性思维与问题解决能力。该数据集专注于中文逻辑理解问题,为自然语言处理领域中的机器阅读理解任务提供了重要的研究资源,对提升模型的逻辑推理能力具有显著影响力。
当前挑战
该数据集的挑战主要体现在两个方面:一是逻辑推理问题的多样性和复杂性,对模型的推理能力提出了高要求;二是构建过程中,确保问题和答案的准确性以及数据集的平衡性是一大难题。此外,跨领域知识的缺乏也使得模型在处理非标准化问题时面临挑战。
常用场景
经典使用场景
在自然语言处理领域,LogiQA-zh数据集的经典使用场景在于评估机器在处理逻辑推理型问题时的理解能力。该数据集模拟了公务员考试中的逻辑推理题目,通过提供一段描述性文字(context)、一个问题(query)以及多个选项(options),要求模型判断哪个选项是正确的(correct_option)。
实际应用
在实际应用中,LogiQA-zh数据集的应用场景广泛,例如在智能客服系统中,模型可以利用该数据集训练出的逻辑推理能力来更准确地理解和回应客户的咨询;在在线教育平台中,可以帮助设计智能辅导系统,评估学生对逻辑推理问题的掌握程度。
衍生相关工作
基于LogiQA-zh数据集,学术界衍生出了许多相关的工作,包括但不限于对逻辑推理模型的改进、跨语言逻辑推理任务的研究以及结合知识图谱的推理方法探索,这些研究进一步扩展了LogiQA-zh数据集的应用范围,并推动了相关领域的学术进展。
以上内容由遇见数据集搜集并总结生成


