syzym/xbmu_amdo31
收藏Hugging Face2022-11-28 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/syzym/xbmu_amdo31
下载链接
链接失效反馈官方服务:
资源简介:
---
pretty_name: XBMU-AMDO31
annotations_creators:
- expert-generated
language_creatosr:
- expert-generated
language:
- tib
license:
- cc-by-sa-4.0
multilinguality:
- monolingual
size_categories:
- 10K<n<100K
task_categories:
- automatic-speech-recognition
---
# Dataset Card for [XBMU-AMDO31]
## Table of Contents
- [Table of Contents](#table-of-contents)
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:**https://github.com/sendream/xbmu_amdo31
- **Repository:**https://github.com/sendream/xbmu_amdo31
- **Paper:**
- **Leaderboard:**https://github.com/sendream/xbmu_amdo31#leaderboard
- **Point of Contact:**[xxlgy@xbmu.edu.cn](mailto:xxlgy@xbmu.edu.cn)
### Dataset Summary
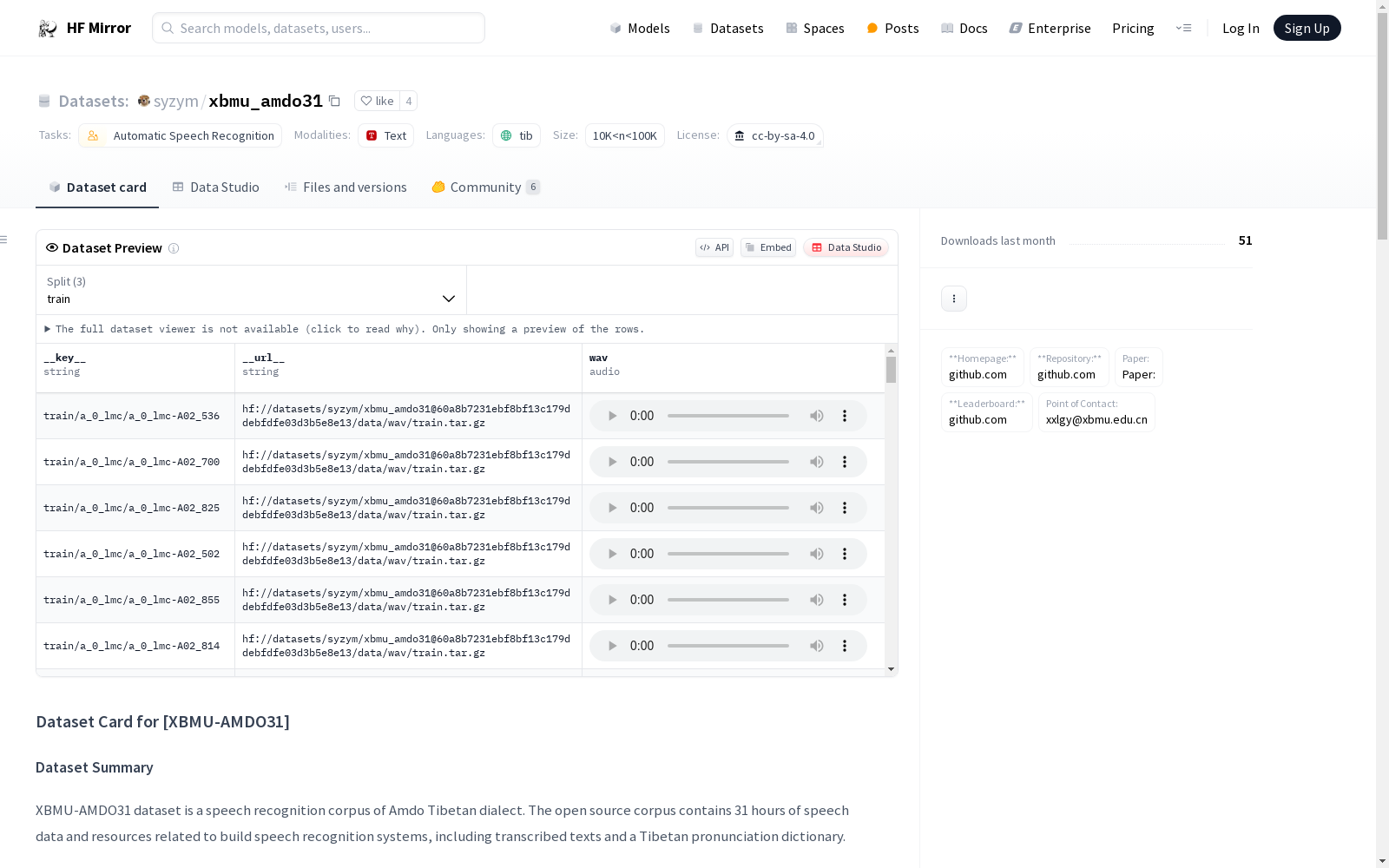
XBMU-AMDO31 dataset is a speech recognition corpus of Amdo Tibetan dialect. The open source corpus contains 31 hours of speech data and resources related to build speech recognition systems, including transcribed texts and a Tibetan pronunciation dictionary.
### Supported Tasks and Leaderboards
automatic-speech-recognition: The dataset can be used to train a model for Amdo Tibetan Automatic Speech Recognition (ASR). It was recorded by 66 native speakers of Amdo Tibetan, and the recorded audio was processed and manually inspected. The most common evaluation metric is the word error rate (WER). The task has an active leaderboard which can be found at https://github.com/sendream/xbmu_amdo31#leaderboard and ranks models based on their WER.
### Languages
XBMU-AMDO31 contains audio, a Tibetan pronunciation dictionary and transcription data in Amdo Tibetan.
## Dataset Structure
### Data Instances
[More Information Needed]
### Data Fields
[More Information Needed]
### Data Splits
The dataset has three splits: train, evaluation (dev) and test.Each speaker had approximately 450 sentences, with a small number of individuals having fewer than 200 sen
| Subset | Hours | Male | Female | Remarks |
| ------ | ----- | ---- | ------ | --------------------------------------- |
| Train | 25.41 | 27 | 27 | 18539 sentences recorded by 54 speakers |
| Dev | 2.81 | 2 | 4 | 2050 sentences recorded by 6 speakers |
| Test | 2.85 | 3 | 3 | 2041 sentences recorded by 6 speakers |
## Dataset Creation
### Curation Rationale
[More Information Needed]
### Source Data
#### Initial Data Collection and Normalization
[More Information Needed]
#### Who are the source language producers?
[More Information Needed]
### Annotations
#### Annotation process
[More Information Needed]
#### Who are the annotators?
[More Information Needed]
### Personal and Sensitive Information
[More Information Needed]
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed]
### Discussion of Biases
[More Information Needed]
### Other Known Limitations
[More Information Needed]
## Additional Information
### Dataset Curators
[More Information Needed]
### Licensing Information
This dataset is distributed under CC BY-SA 4.0.
### Citation Information
[More Information Needed]
### Contributions
Thanks to [@speechless-z](https://github.com/speechless-z) for adding this dataset.
pretty_name: XBMU-AMDO31
annotations_creators:
- 专家生成
language_creatosr:
- 专家生成
language:
- 藏语(Tibetan)
license:
- CC BY-SA 4.0(知识共享署名-相同方式共享4.0协议)
multilinguality:
- 单语言
size_categories:
- 10000 < 样本量 < 100000
task_categories:
- 自动语音识别
# XBMU-AMDO31数据集卡片
## 目录
- [目录](#目录)
- [数据集描述](#数据集描述)
- [数据集概述](#数据集概述)
- [支持任务与排行榜](#支持任务与排行榜)
- [使用语言](#使用语言)
- [数据集结构](#数据集结构)
- [数据实例](#数据实例)
- [数据字段](#数据字段)
- [数据划分](#数据划分)
- [数据集构建](#数据集构建)
- [数据集构建初衷](#数据集构建初衷)
- [源数据](#源数据)
- [标注信息](#标注信息)
- [个人与敏感信息](#个人与敏感信息)
- [数据集使用注意事项](#数据集使用注意事项)
- [数据集的社会影响](#数据集的社会影响)
- [偏差讨论](#偏差讨论)
- [其他已知局限性](#其他已知局限性)
- [附加信息](#附加信息)
- [数据集管理者](#数据集管理者)
- [许可信息](#许可信息)
- [引用信息](#引用信息)
- [贡献者](#贡献者)
## 数据集描述
- **主页**:https://github.com/sendream/xbmu_amdo31
- **代码仓库**:https://github.com/sendream/xbmu_amdo31
- **论文**:
- **排行榜**:https://github.com/sendream/xbmu_amdo31#leaderboard
- **联系方式**:[xxlgy@xbmu.edu.cn](mailto:xxlgy@xbmu.edu.cn)
### 数据集概述
XBMU-AMDO31数据集是安多藏语方言的语音识别语料库。该开源语料库包含31小时的语音数据,以及用于构建语音识别系统的相关资源,包括转写文本与藏语发音词典。
### 支持任务与排行榜
自动语音识别:该数据集可用于训练安多藏语自动语音识别(Automatic Speech Recognition, ASR)模型。数据由66名安多藏语母语使用者录制,录制的音频经过处理与人工核验。最常用的评估指标为词错误率(Word Error Rate, WER)。该任务设有活跃排行榜,可访问https://github.com/sendream/xbmu_amdo31#leaderboard查看,排行榜基于模型的词错误率进行排名。
### 使用语言
XBMU-AMDO31包含安多藏语的音频、藏语发音词典与转写数据。
## 数据集结构
### 数据实例
[需更多信息]
### 数据字段
[需更多信息]
### 数据划分
该数据集分为三个子集:训练集、验证集(开发集)与测试集。每位说话者约录制450条句子,少数个体录制的句子少于200条。
| 子集 | 时长(小时) | 男性说话者数量 | 女性说话者数量 | 备注 |
| ------ | ------------ | -------------- | -------------- | -------------------------------------- |
| 训练集 | 25.41 | 27 | 27 | 由54名说话者录制的18539条句子 |
| 验证集 | 2.81 | 2 | 4 | 由6名说话者录制的2050条句子 |
| 测试集 | 2.85 | 3 | 3 | 由6名说话者录制的2041条句子 |
## 数据集构建
### 数据集构建初衷
[需更多信息]
### 源数据
#### 初始数据收集与标准化
[需更多信息]
#### 源语言使用者是谁?
[需更多信息]
### 标注信息
#### 标注流程
[需更多信息]
#### 标注者是谁?
[需更多信息]
### 个人与敏感信息
[需更多信息]
## 数据集使用注意事项
### 数据集的社会影响
[需更多信息]
### 偏差讨论
[需更多信息]
### 其他已知局限性
[需更多信息]
## 附加信息
### 数据集管理者
[需更多信息]
### 许可信息
本数据集采用CC BY-SA 4.0协议分发。
### 引用信息
[需更多信息]
### 贡献者
感谢 [@speechless-z](https://github.com/speechless-z) 添加本数据集。
提供机构:
syzym
原始信息汇总
数据集概述
数据集名称
- 名称: XBMU-AMDO31
数据集描述
- 摘要: XBMU-AMDO31是一个针对安多藏语方言的语音识别语料库。该开源语料库包含31小时的语音数据及相关资源,用于构建语音识别系统,包括转录文本和一个藏语发音词典。
- 支持的任务: 自动语音识别(ASR),用于训练安多藏语自动语音识别模型。
- 语言: 安多藏语
数据集结构
- 数据分割: 数据集分为训练集、验证集(dev)和测试集。
- 训练集: 25.41小时,由54位说话者录制,共18539句。
- 验证集: 2.81小时,由6位说话者录制,共2050句。
- 测试集: 2.85小时,由6位说话者录制,共2041句。
数据集创建
- 许可证: 数据集遵循CC BY-SA 4.0许可证。
贡献者
- 贡献者: @speechless-z
搜集汇总
数据集介绍
构建方式
XBMU-AMDO31数据集的构建,是基于对安多藏语方言的语音识别需求,通过精心策划的数据采集与标注流程,收集了66位安多藏语母语者的语音数据。这些数据经过专业的处理与人工校验,形成了包含转录文本和藏语发音词典的31小时语音识别语料库。数据集分为训练集、验证集和测试集,确保了数据的多样性和可用性。
特点
该数据集的特点在于其专注于安多藏语这一特定方言的语音识别,提供了丰富的语音资源和对应的文本转录,以及发音词典,有助于推动该领域的研究和应用。此外,数据集遵循CC BY-SA 4.0许可,保证了数据的开放性和共享性。数据集规模适中,便于研究者进行有效的模型训练和评估。
使用方法
使用XBMU-AMDO31数据集,研究者可以将其用于自动语音识别模型的训练与评估。数据集的三种划分使得研究者可以方便地进行模型的开发、验证和测试。用户应遵循数据使用条款,尊重数据版权,并在研究成果中引用数据集来源。具体使用时,需从官方仓库获取数据,并根据研究需求对数据进行相应的预处理和后处理。
背景与挑战
背景概述
XBMU-AMDO31数据集是一项旨在推进安多藏语自动语音识别技术的研究成果,由西藏大学提供,收集了31小时的安多藏语方言语音数据。该数据集的创建,不仅丰富了藏语语言资源,也为藏语语音识别领域的研究提供了宝贵的实验材料。自发布以来,它吸引了众多研究者和开发者的关注,对促进藏语信息科技发展和语言资源的数字化保护具有深远影响。
当前挑战
该数据集在构建过程中遇到了诸多挑战,首先是在数据收集方面,由于藏语方言的多样性和地域分布的广泛性,确保语音样本的代表性是一大难题。其次,在语音标注和转录过程中,缺乏足够的专业知识和资源,导致标注质量难以保证。此外,数据集的多元应用也带来了如何平衡数据开放与隐私保护的挑战。在研究领域,如何利用该数据集提高藏语自动语音识别的准确率和鲁棒性,仍是一个待解决的问题。
常用场景
经典使用场景
在自动语音识别领域,XBMU-AMDO31数据集以其丰富的藏语阿坝方言语音资源,成为构建与训练藏语ASR系统的重要基石。该数据集提供了详尽的转录文本和藏语发音词典,使得研究者能够利用其进行声学模型和语言模型的训练,进而提升语音识别的准确率。
解决学术问题
XBMU-AMDO31数据集的构建,有效解决了藏语阿坝方言在自动语音识别领域的资源匮乏问题,为藏语语音识别技术的研究提供了高质量的数据支撑。这对于减少语言识别中的误差,提高跨语言语音识别系统的性能具有显著意义。
衍生相关工作
该数据集的发布,不仅直接推动了藏语自动语音识别技术的发展,还催生了一系列相关的学术研究,如藏语语音合成、藏语语音情感识别等领域的探索,为藏语信息处理技术的全面进步奠定了基础。
以上内容由遇见数据集搜集并总结生成


