SINAI/ALIA-es-cultural-hard-negatives
收藏Hugging Face2026-05-08 更新2026-05-10 收录
下载链接:
https://hf-mirror.com/datasets/SINAI/ALIA-es-cultural-hard-negatives
下载链接
链接失效反馈官方服务:
资源简介:
ALIA西班牙文化和遗产硬负例语料库是一个用于密集检索训练的数据集,包含从<SINAI/ALIA-es-cultural-pairs>中的<查询,段落>对生成的硬负例。硬负例是语义上与查询相似但不正确的段落,有助于训练鲁棒的检索系统。数据集包含两种配置:硬负例(训练)和评估(三元组)。训练配置包含查询、一个正例段落和多个硬负例段落;评估配置包含查询、段落和答案的三元组。数据集还包含不同难度级别的数据,从高中到博士级别。数据集的创建使用了SentenceTransformers和FAISS相似性搜索技术,嵌入模型为Qwen3-Embedding-0.6B。
The ALIA Spanish Cultural and Heritage Hard Negatives Corpus is a dataset designed for dense retrieval training, containing hard negatives generated from <query, passage> pairs in <SINAI/ALIA-es-cultural-pairs>. Hard negatives are passages that are semantically similar to a query but not correct answers, which helps in training robust retrieval systems. The dataset includes two configurations: hard-negatives (training) and evaluation (triplets). The training configuration contains queries, one positive passage, and multiple hard negative passages; the evaluation configuration contains triplets of query, passage, and answer. The dataset also includes data at different difficulty levels, ranging from high school to PhD. The dataset was created using SentenceTransformers and FAISS similarity search techniques, with the Qwen3-Embedding-0.6B embedding model.
提供机构:
SINAI
搜集汇总
数据集介绍
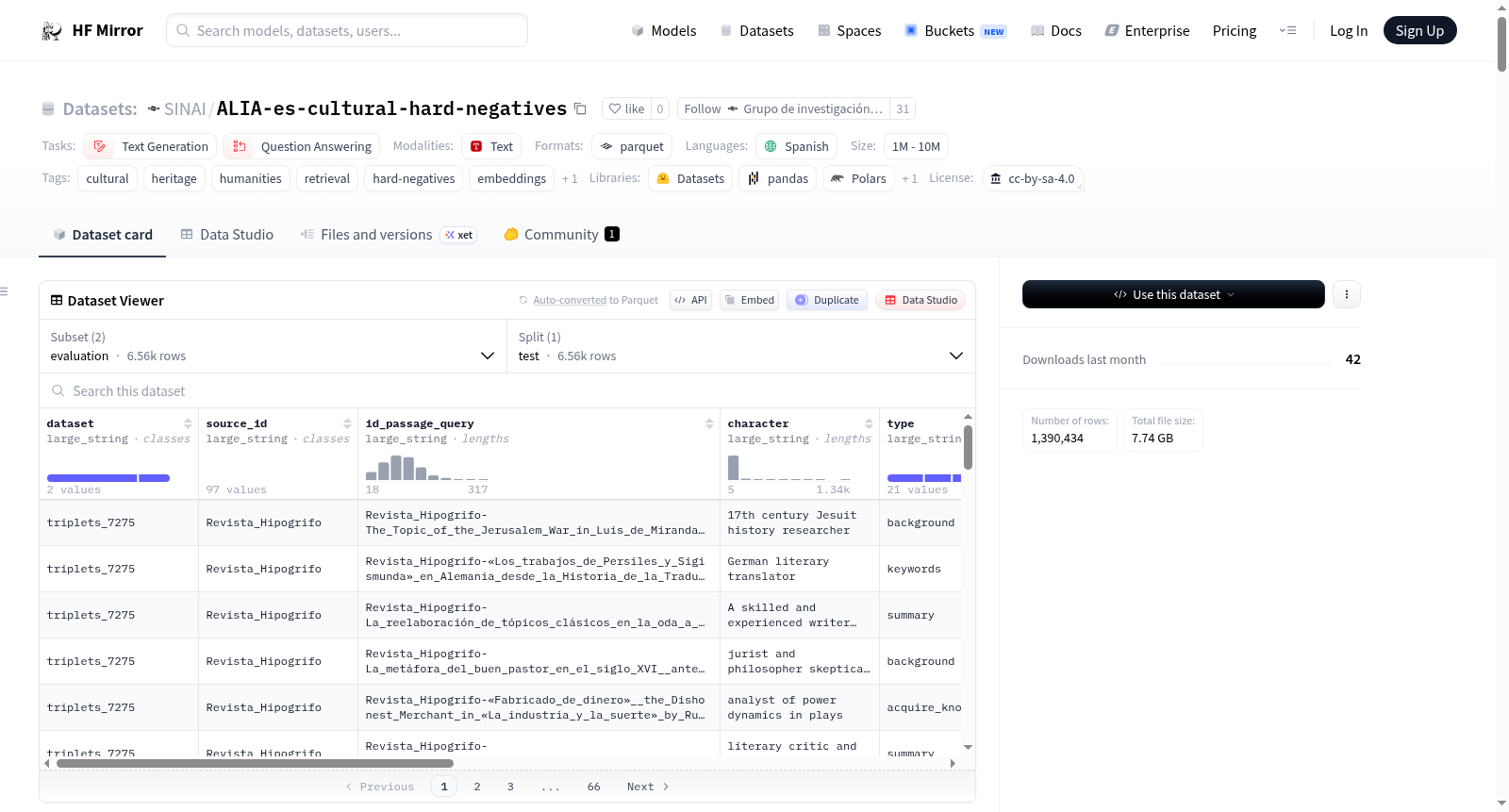
构建方式
该数据集基于SINAI/ALIA-es-cultural-pairs中的查询-段落对,利用SentenceTransformers框架与Qwen3-Embedding-0.6B嵌入模型,通过FAISS相似性搜索构建硬负样本挖掘流水线自动生成。具体而言,首先对查询和段落进行编码并建立FAISS索引,检索语义相近的段落,随后应用相似度过滤约束,选取与查询嵌入接近但非正确答案的段落作为硬负样本。挖掘过程中采用两种采样策略:阶段一从候选池中随机采样,阶段二则选取最相似的负样本,最终为每条查询配备多个硬负样本(通常为5个),以支持对比学习或排序损失的训练范式。
特点
数据集的核心特点在于其专注于西班牙文化遗产领域,提供了超过138万条训练硬负样本和6562条评估三元组,覆盖高中、大学、博士三级难度,以适应不同复杂度的检索任务。每个训练实例包含查询、一个正例段落及多个语义相近的硬负样本,格式采用对话式结构,便于直接用于双编码器或密集检索模型的训练。评估配置则提供完整的查询-段落-答案三元组,并附带来源、难度、角色类型等元数据,支持对检索模型排序质量进行精细化测评。所有数据均源自公开文化遗产与机构资源,并经过隐私过滤处理,确保合规性。
使用方法
用户可通过HuggingFace datasets库便捷加载数据:使用load_dataset函数指定'hard-negatives'配置加载训练集,或指定'evaluation'配置加载评估集。训练实例的查询、正例和负样本分别位于'messages'、'positive_messages'和'negative_messages'字段中,可直接提取用于构建对比学习样本。评估实例则直接提供'query'、'passage'和'answer'字段,适用于检索模型排序质量的评估或基准测试。该数据集特别适合用于训练SentenceTransformers密集检索器、双编码器模型以及基于对比学习的RAG检索器,并支持课程学习策略,从易到难逐步提升模型性能。
背景与挑战
背景概述
ALIA-es-cultural-hard-negatives数据集由西班牙SINAI研究团队于2026年创建,隶属于ALIA项目,旨在提升西班牙语文化遗产领域密集检索模型的训练质量。该数据集聚焦于文化遗产查询与文本段落的语义匹配,通过自动挖掘技术生成语义相近但非正确答案的难负样本,以增强模型对细微语义差别的辨识能力。作为首个专为西班牙语文化遗产领域设计的大规模难负样本语料库,其包含超过138万条训练样本和6562条评估三元组,覆盖高中、大学及博士三类难度层次,为数字人文与文化遗产信息检索研究提供了关键资源,推动了西班牙语自然语言处理在文化遗产保护中的应用。
当前挑战
该数据集所应对的领域核心挑战在于文化遗产文本的语义复杂性,专业术语与历史语境导致的语义模糊性使得传统检索模型难以区分高度相似的查询与段落,亟需难负样本以提升密集检索的排序性能。构建过程中面临多重困难:首先,需确保自动挖掘的难负样本虽语义接近但事实性错误,避免引入误导性信息;其次,基于Qwen3-Embedding-0.6B模型与FAISS索引的流水线需精细调节相似度阈值与距离范围,以平衡样本难度与数据质量;此外,数据来源涉及多源文化遗产文档,需过滤个人隐私信息并处理不同机构背景下的术语差异,保证语料库的鲁棒性与领域适用性。
常用场景
经典使用场景
在信息检索与自然语言处理领域,ALIA-es-cultural-hard-negatives数据集的核心应用场景聚焦于密集检索模型的对比学习训练。通过为每条查询提供语义高度相似但非正确答案的硬负例,该数据使得模型能够在西语文化遗产语境下学习精细的语义区分能力,显著提升排序与召回性能。具体而言,研究者和开发者可借助该多负例结构,基于SentenceTransformers等框架训练双编码器检索模型,并将不同难度层级(高中、大学、博士)的数据纳入课程学习策略,逐步增强模型对语义复杂度的适应能力。该数据集构建了从训练到评测的完整流程,为西语文化遗产领域的语义检索技术提供了标准化、可复现的基准资源。
衍生相关工作
该数据集的发布催生了一系列专精于文化遗产密集检索的模型与工作。其中,以Qwen3-Embedding-0.6B为基座的硬负例挖掘策略成为后续研究的重要基准,研究者基于同一管道进一步探索跨难度课程学习与多阶段负例采样策略。此外,该数据集与同源的SINAI/ALIA-es-cultural-pairs共同构成了ALIA项目下的双模块体系,前方提供配对训练基础,后者负责冲突负例供给,共同支撑了面向西班牙文化遗产文本的专用嵌入模型及其蒸馏优化工作。评测三元组格式的引入也促进了与其他西语NLP数据集的横向联合评估,为构建覆盖多领域、多难度的检索模型排行榜提供了可扩展数据基础,推动了小语种专用检索领域的方法论创新。
数据集最近研究
最新研究方向
该数据集聚焦于西班牙文化遗产领域的密集检索模型训练,通过自动挖掘语义相近但非正确答案的硬负样本,显著提升检索系统对细微语义差异的辨别能力。前沿方向包括融入多难度层级(高中、大学、博士)的课程学习策略,以及利用先进嵌入模型(如Qwen3-Embedding-0.6B)和FAISS相似性搜索技术,构建高质量负样本生成管道。这一研究响应了数字人文学科中对文化遗产精准检索的迫切需求,尤其助力西班牙语环境下历史文献、术语解读等复杂任务的智能化处理,为跨语言文化信息访问和数字遗产保护提供了关键基础设施。
以上内容由遇见数据集搜集并总结生成


