chonkiepedia
收藏Hugging Face2025-05-01 更新2025-05-02 收录
下载链接:
https://huggingface.co/datasets/chonkie-ai/chonkiepedia
下载链接
链接失效反馈官方服务:
资源简介:
Chonkiepedia是一个为微调模型而创建的Chonkified维基百科文章数据集,大约包含100万篇Chonkified维基百科文章。该数据集通过过滤长度至少为5000字符的英文维基百科文章,移除所有参考文献和'参见'部分,并标准化文本去除怪异空格和换行。使用Chonkie's RecursiveChunker在特定参数下生成高质量块,并将这些块与🦛表情结合以提高存储效率。
创建时间:
2025-04-30
原始信息汇总
Chonkiepedia数据集概述
基本信息
- 许可证:Creative Commons Attribution-ShareAlike 3.0 License、GNU Free Documentation License
- 语言:英语(en)
- 规模:100K<N<1M
- 任务类别:token-classification
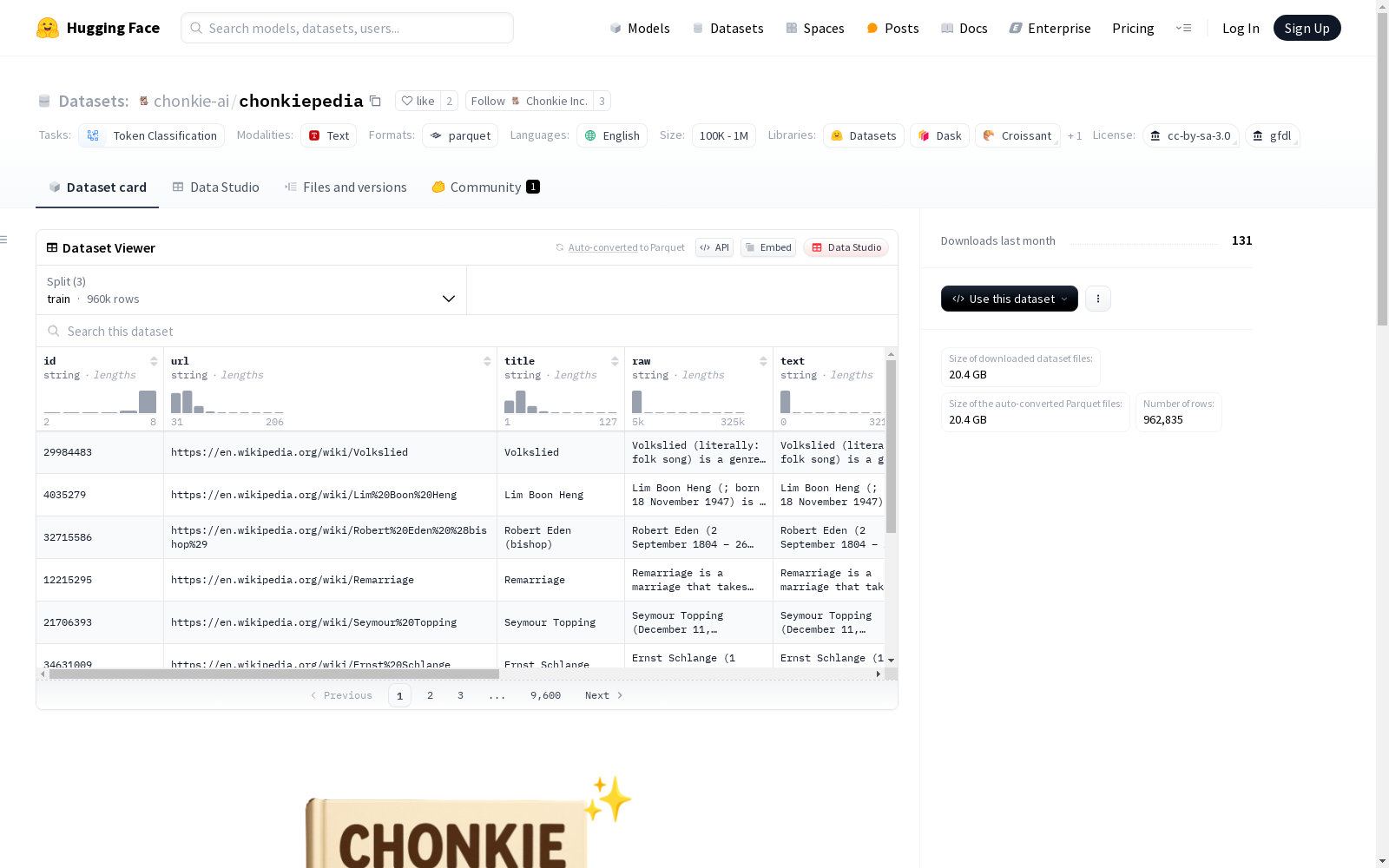
数据集内容
-
特征:
- id (string)
- url (string)
- title (string)
- raw (string)
- text (string)
- words (sequence: string)
- labels (sequence: int64)
-
数据划分:
- train:960,000条,52,609,904,366.17字节
- validation:1,835条,100,561,640.12字节
- test:1,000条,54,801,983.71字节
-
下载大小:20,400,944,781字节
-
数据集大小:52,765,267,990.0字节
概述
Chonkiepedia是一个用于微调模型的Chonkified Wikipedia数据集,包含约100万篇Chonkified Wikipedia文章。
方法
- 从英文维基百科中筛选至少5000个字符(约1000个单词)的文章。
- 删除所有引用和
see also部分。 - 规范化文本以去除奇怪的间距和换行符。
- 使用Chonkie的RecursiveChunker在特定参数下返回高质量块列表(平均而言)。
- 将块与
🦛表情符号结合以高效存储。
使用方式
python from datasets import load_dataset dataset = load_dataset("chonkie/chonkiepedia", split="train")
引用
bibtex @article{chonkiepedia2025, title={Chonkiepedia: A dataset of Chonkified Wikipedia for fine-tuning models}, author={Chonkie, Inc.}, year={2025} }
搜集汇总
数据集介绍
构建方式
在自然语言处理领域,高质量的数据集是模型微调的基础。Chonkiepedia数据集基于英文维基百科构建,通过严格的筛选流程,仅保留字符数超过5000的长篇文章。构建过程中移除了所有参考文献和'参见'章节,并对文本进行了标准化处理以消除异常空格和换行符。随后采用RecursiveChunker算法,在特定参数下生成平均质量优良的文本块,最后使用河马表情符号进行高效存储。
特点
该数据集包含约100万篇经过特殊处理的维基百科文章,具有显著的规模优势。其文本经过精心筛选和标准化处理,确保了数据质量。独特的河马表情符号存储方式不仅提升了存储效率,也为数据集增添了鲜明特色。作为token-classification任务的优质资源,其丰富的内容覆盖了广泛的知识领域,为模型微调提供了充足素材。
使用方法
研究人员可通过Hugging Face Hub便捷地获取该数据集。使用datasets库中的load_dataset函数,指定'chonkie/chonkiepedia'路径即可加载训练集。数据集遵循与维基百科相同的知识共享许可协议,确保了使用的合法性。为促进学术规范,建议使用者按照提供的引用格式在相关研究中注明数据来源。
背景与挑战
背景概述
Chonkiepedia数据集由Chonkie公司于2025年发布,旨在为模型微调提供高质量的文本数据资源。该数据集基于英文维基百科构建,筛选了长度超过5000字符的文章,并经过严格的预处理流程,包括去除参考文献和冗余章节、文本规范化等步骤。通过RecursiveChunker算法生成优质文本块,并以河马表情符号作为分隔符优化存储效率,最终形成约百万条文本样本。作为自然语言处理领域的新型语料库,Chonkiepedia为文本分块、序列标注等任务提供了规模可观且结构规范的数据支持,对提升语言模型的细粒度文本理解能力具有重要价值。
当前挑战
该数据集主要面临两个维度的挑战:在领域问题层面,如何保持维基百科知识广度的同时确保文本分块的语义完整性成为关键难题,过长分块会导致模型训练效率下降,过短则可能破坏知识连贯性;在构建过程层面,原始维基百科文本的异构性(如复杂排版、公式表格等非结构化内容)对规范化处理提出严峻考验,而RecursiveChunker算法的参数调优需要平衡分块质量与计算成本。此外,双许可协议(CC-BY-SA-3.0和GFDL)虽然保障了法律合规性,但也对数据集的商业应用场景形成一定限制。
常用场景
经典使用场景
在自然语言处理领域,Chonkiepedia数据集以其独特的处理方式和丰富的文本内容,成为模型微调的理想选择。该数据集通过对英文维基百科文章进行筛选和规范化处理,并结合Chonkie的RecursiveChunker技术,生成了高质量的文本块。这些文本块不仅保留了原始内容的语义完整性,还通过特定的参数优化,确保了数据的多样性和代表性。经典的使用场景包括语言模型的预训练和微调,特别是在需要处理长文本或复杂语义结构的任务中,Chonkiepedia展现了其独特的优势。
实际应用
在实际应用中,Chonkiepedia数据集被广泛用于各类自然语言处理任务。例如,在文本摘要、机器翻译和问答系统中,该数据集的高质量文本块为模型训练提供了坚实的基础。特别是在需要处理维基百科风格文本的应用场景中,如知识图谱构建和信息检索,Chonkiepedia的数据结构和处理方式显著提升了模型的准确性和效率。此外,该数据集还被用于教育领域,作为语言模型教学的典型案例,展示了数据预处理和模型微调的最佳实践。
衍生相关工作
Chonkiepedia数据集的推出,激发了大量相关研究工作的开展。基于该数据集的经典工作包括长文本处理算法的优化、递归分块技术的改进以及语言模型微调策略的探索。例如,一些研究利用Chonkiepedia的数据结构,开发了新型的文本分块算法,进一步提升了数据处理的效率和质量。此外,该数据集还被用于多模态学习的研究,结合图像和文本数据,推动了跨模态模型的发展。这些衍生工作不仅扩展了数据集的应用范围,也为自然语言处理领域的技术进步提供了新的思路。
以上内容由遇见数据集搜集并总结生成


