ColonINST-v1
收藏Hugging Face2024-10-15 更新2024-12-12 收录
下载链接:
https://huggingface.co/datasets/ai4colonoscopy/ColonINST-v1
下载链接
链接失效反馈官方服务:
资源简介:
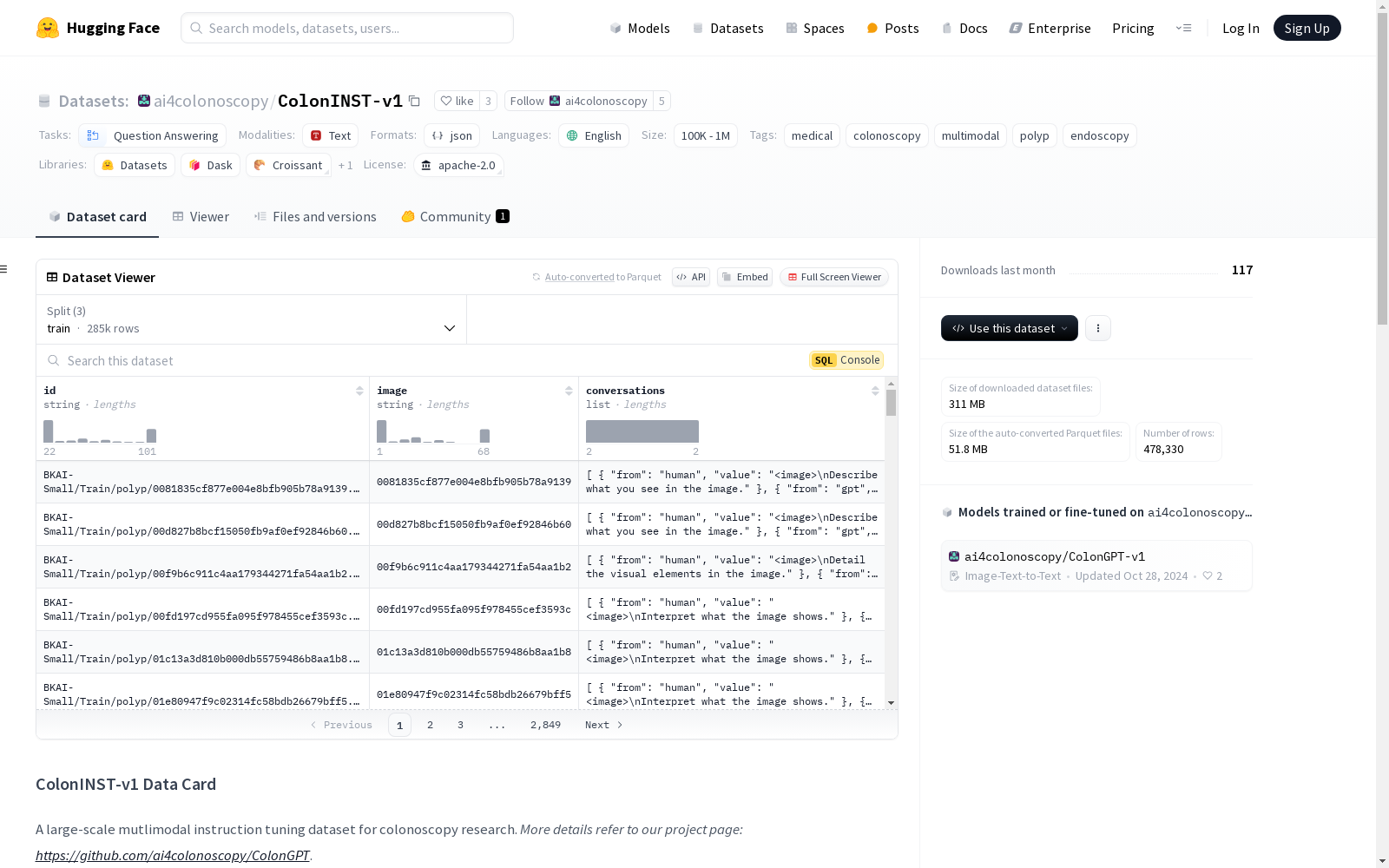
ColonINST-v1是一个大规模的多模态指令调优数据集,专门用于结肠镜检查研究。该数据集包含62个类别、超过30万张结肠镜图像、12.8万条医学描述(由GPT-4V生成)和超过45万条人机对话。数据集分为两部分:结肠镜图像和以JSON格式存储的人机对话。由于隐私问题,原始的结肠镜图像不能公开分享,但人机对话的JSON文件可以访问。数据集的目的是指导模型执行用户驱动的交互任务。
ColonINST-v1 is a large-scale multimodal instruction-tuning dataset dedicated to colonoscopy research. It encompasses 62 categories, over 300,000 colonoscopy images, 128,000 medical descriptions generated by GPT-4V, and more than 450,000 human-machine dialogues. The dataset is split into two components: colonoscopy images and human-machine dialogues stored in JSON format. Due to privacy concerns, the original colonoscopy images cannot be publicly shared, while the JSON files containing the human-machine dialogues are accessible. The purpose of this dataset is to guide models in executing user-driven interactive tasks.
创建时间:
2024-10-14
原始信息汇总
ColonINST-v1 数据集概述
基本信息
- 许可证: Apache 2.0
- 任务类别: 问答
- 语言: 英语
- 数据规模: 100K<n<1M
- 标签: 医疗、结肠镜检查、多模态、息肉、内窥镜
数据描述
- 数据集类型: 多模态指令调优数据集
- 目标领域: 结肠镜检查研究
- 数据组成:
- 62个类别
- 300K+ 结肠镜图像
- 128K+ 医学描述(由GPT-4V生成)
- 450K+ 人机对话
使用说明
- 数据集结构: 包含结肠镜图像和JSON格式的人机对话
- 数据访问:
- 由于隐私问题,原始结肠镜图像无法公开共享。请参考此说明准备所有结肠镜图像。
- JSON文件中的人机对话可直接访问。
- 安装与加载:
-
安装
datasets库: bash pip install datasets -
加载数据集: python from datasets import load_dataset
加载 ColonINST-v1 数据集
dataset = load_dataset("ai4colonoscopy/ColonINST-v1")
探索数据集
print(dataset)
-
访问特定分割(如训练、验证或测试): python train_dataset = load_dataset("ai4colonoscopy/ColonINST-v1", split="train")
-
许可证
- 许可证类型: Apache 2.0
搜集汇总
数据集介绍
构建方式
ColonINST-v1数据集作为一项开创性的多模态指令调优数据集,专为结肠镜研究设计,旨在指导模型执行用户驱动的交互任务。该数据集包含62个类别,涵盖了超过30万张结肠镜图像、12.8万条由GPT-4V生成的医学描述以及45万条人机对话。数据集的构建通过整合多模态信息,为模型提供了丰富的上下文和任务导向的训练材料。
特点
ColonINST-v1数据集以其规模庞大和多样性著称,涵盖了广泛的结肠镜图像和医学描述,为多模态研究提供了坚实的基础。数据集中的图像和对话内容经过精心筛选和标注,确保了数据的质量和实用性。特别值得一提的是,数据集中的医学描述由GPT-4V生成,展现了先进的自然语言处理技术在医学领域的应用潜力。
使用方法
ColonINST-v1数据集的使用分为两部分:结肠镜图像和人机对话。由于医学图像的隐私问题,原始图像未公开,用户需按照特定指南准备图像。人机对话部分以JSON格式提供,用户可通过安装datasets库并调用load_dataset函数轻松加载数据集。数据集支持按需划分训练、验证和测试集,方便用户进行模型训练和评估。
背景与挑战
背景概述
ColonINST-v1数据集是一个面向结肠镜检查研究的大规模多模态指令调优数据集,由ai4colonoscopy团队开发。该数据集旨在通过交互式任务指导模型执行用户驱动的操作,涵盖了62个类别、超过30万张结肠镜图像、12.8万条由GPT-4V生成的医学描述以及45万条人机对话。其核心研究问题在于如何利用多模态数据(图像与文本)提升结肠镜检查的智能化水平,为医学影像分析与诊断提供支持。该数据集的发布标志着结肠镜研究领域在人工智能应用方面迈出了重要一步,为相关领域的模型训练与优化提供了宝贵的资源。
当前挑战
ColonINST-v1数据集在构建与应用过程中面临多重挑战。首先,医学图像的隐私保护问题限制了原始数据的公开共享,需通过严格的访问控制机制确保数据安全。其次,多模态数据的对齐与融合是技术难点,如何高效整合图像与文本信息以提升模型性能仍需深入研究。此外,医学描述的生成依赖于GPT-4V等先进模型,但其准确性与专业性仍需进一步验证。最后,数据集规模庞大,对计算资源与存储能力提出了较高要求,如何在有限资源下高效处理与训练模型是亟待解决的问题。
常用场景
经典使用场景
ColonINST-v1数据集在医学影像分析领域具有广泛的应用,特别是在结肠镜检查的研究中。该数据集通过提供大量的结肠镜图像和人类与机器之间的对话,为研究人员提供了一个多模态的指令调优平台。经典的使用场景包括训练和评估基于深度学习的结肠镜图像分析模型,以及开发能够理解并执行复杂医学任务的智能系统。
实际应用
在实际应用中,ColonINST-v1数据集被广泛用于开发智能结肠镜辅助诊断系统。这些系统能够自动识别结肠镜图像中的异常区域,如息肉和肿瘤,并提供实时的诊断建议。此外,该数据集还被用于训练能够与医生进行自然语言交互的智能助手,提升结肠镜检查的效率和准确性,为临床实践带来了显著的技术革新。
衍生相关工作
基于ColonINST-v1数据集,研究人员已经开展了多项经典工作。例如,开发了基于深度学习的结肠镜图像分类模型,能够高精度地识别不同类型的息肉。此外,该数据集还催生了多模态医学影像理解系统,这些系统能够结合图像和文本信息,执行复杂的医学任务。这些工作不仅推动了结肠镜技术的发展,也为其他医学影像分析领域提供了宝贵的参考。
以上内容由遇见数据集搜集并总结生成


