MU-NLPC/Calc-aqua_rat
收藏Hugging Face2023-10-30 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/MU-NLPC/Calc-aqua_rat
下载链接
链接失效反馈资源简介:
---
language:
- en
license: apache-2.0
size_categories:
- 10K<n<100K
task_categories:
- question-answering
pretty_name: AQuA-RAT with Calculator
dataset_info:
- config_name: default
features:
- name: id
dtype: string
- name: question
dtype: string
- name: chain
dtype: string
- name: result
dtype: string
- name: options
struct:
- name: A
dtype: string
- name: B
dtype: string
- name: C
dtype: string
- name: D
dtype: string
- name: E
dtype: string
- name: question_without_options
dtype: string
splits:
- name: train
num_bytes: 72917721
num_examples: 94760
- name: validation
num_bytes: 212928
num_examples: 254
- name: test
num_bytes: 206180
num_examples: 254
download_size: 42057527
dataset_size: 73336829
- config_name: original-splits
features:
- name: id
dtype: string
- name: question
dtype: string
- name: chain
dtype: string
- name: result
dtype: string
- name: options
struct:
- name: A
dtype: string
- name: B
dtype: string
- name: C
dtype: string
- name: D
dtype: string
- name: E
dtype: string
- name: question_without_options
dtype: string
splits:
- name: train
num_bytes: 74265737
num_examples: 97467
- name: validation
num_bytes: 212928
num_examples: 254
- name: test
num_bytes: 206180
num_examples: 254
download_size: 42873590
dataset_size: 74684845
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: validation
path: data/validation-*
- split: test
path: data/test-*
- config_name: original-splits
data_files:
- split: train
path: original-splits/train-*
- split: validation
path: original-splits/validation-*
- split: test
path: original-splits/test-*
---
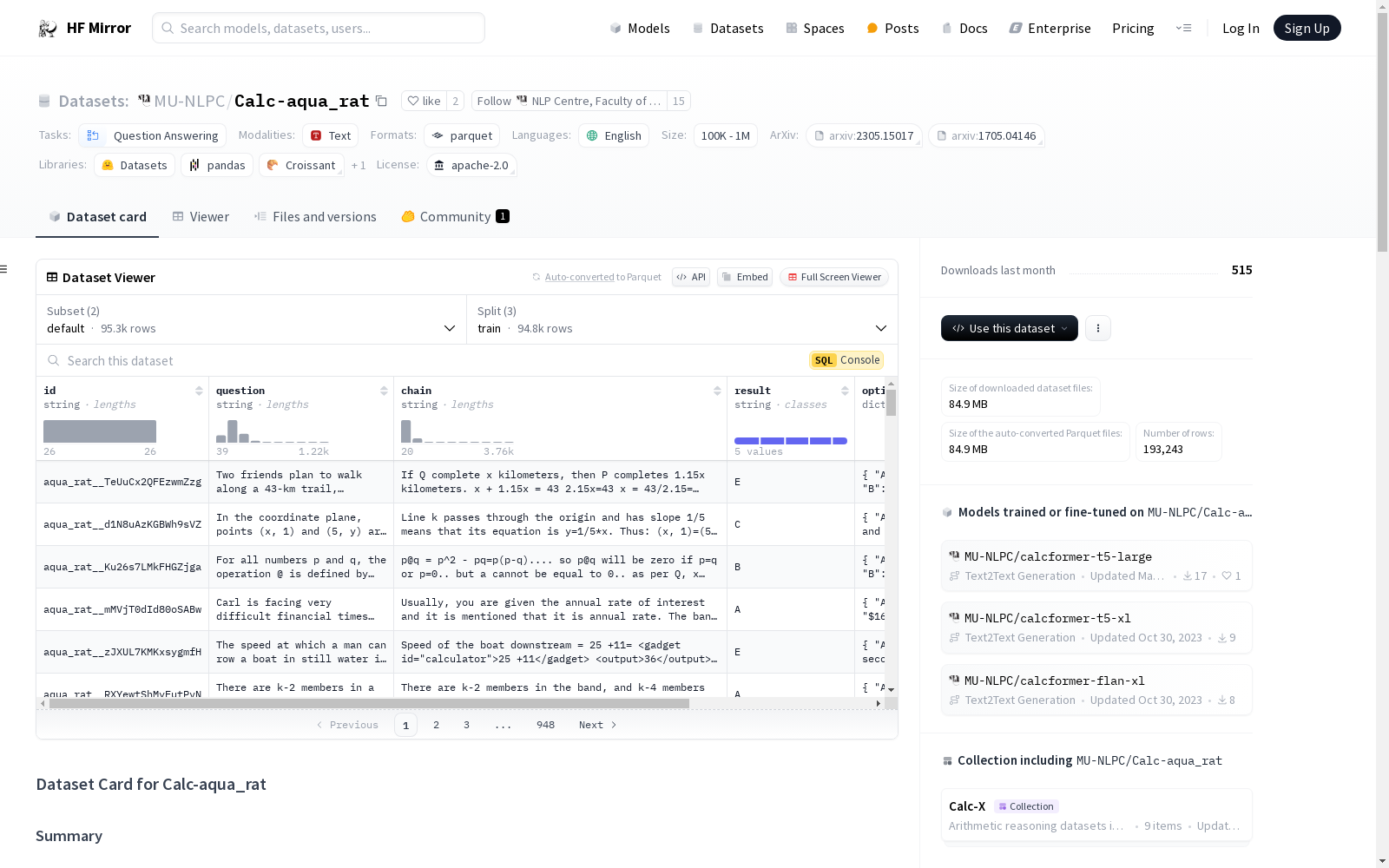
# Dataset Card for Calc-aqua_rat
## Summary
This dataset is an instance of [AQuA-RAT](https://huggingface.co/datasets/aqua_rat) dataset extended with in-context calls of a sympy calculator.
## Supported Tasks
The dataset is intended for training Chain-of-Thought reasoning models able to use external tools to enhance the factuality of their responses.
This dataset presents in-context scenarios where models can outsource the computations in the reasoning chain to a calculator.
## Construction Process
The dataset was constructed automatically by evaluating all candidate calls to a `sympy` library that were extracted from the originally annotated
*rationale*s. The selection of candidates is pivoted by the matching of equals ('=') symbols in the chain, where the left-hand side of the equation is evaluated,
and accepted as a correct gadget call, if the result occurs closely on the right-hand side.
Therefore, the extraction of calculator calls may inhibit false negatives (where the calculator could have been used but was not), but not any known
false positives.
We also perform in-dataset and cross-dataset data-leak detection within the [Calc-X collection](https://huggingface.co/collections/MU-NLPC/calc-x-652fee9a6b838fd820055483). Specifically for AQuA-RAT, we removed a few percent of the train split that were near-duplicates with some of the test or validation examples.
A full description of the extraction process can be found in the [corresponding parse script](https://github.com/prompteus/calc-x/blob/7799a7841940b15593d4667219424ee71c74327e/gadgets/aqua.py#L19),
**If you find an issue in the dataset or in the fresh version of the parsing script, we'd be happy if you report it, or create a PR.**
## Data splits
The dataset with the near-duplicates removed can be loaded in the default config using:
```python
datasets.load_dataset("MU-NLPC/calc-aqua_rat")
```
If you want the unfiltered version, you can use:
```python
datasets.load_dataset("MU-NLPC/calc-aqua_rat", "original-splits")
```
## Attributes
- **id**: an id of the example
- **question**: A natural language definition of the problem to solve, including the options to choose from
- **chain**: A natural language step-by-step solution with automatically inserted calculator calls and outputs of the sympy calculator
- **result**: The correct option (one of A...E)
- **options**: a dictionary with 5 possible options (A, B, C, D and E), among which one is correct
- **question_without_options**: same as **question** but without the options inserted
Attributes **id**, **question**, **chain**, and **result** are present in all datasets in [Calc-X collection](https://huggingface.co/collections/MU-NLPC/calc-x-652fee9a6b838fd820055483).
## Related work
This dataset was created as a part of a larger effort in training models capable of using a calculator during inference, which we call Calcformers.
- [**Calc-X collection**](https://huggingface.co/collections/MU-NLPC/calc-x-652fee9a6b838fd820055483) - datasets for training Calcformers
- [**Calcformers collection**](https://huggingface.co/collections/MU-NLPC/calcformers-65367392badc497807b3caf5) - calculator-using models we trained and published on HF
- [**Calc-X and Calcformers paper**](https://arxiv.org/abs/2305.15017)
- [**Calc-X and Calcformers repo**](https://github.com/prompteus/calc-x)
Here are links to the original dataset:
- [**original AQuA-RAT dataset**](https://huggingface.co/datasets/aqua_rat)
- [**original AQuA-RAT paper**](https://arxiv.org/pdf/1705.04146.pdf)
- [**original AQuA-RAT repo**](https://github.com/google-deepmind/AQuA)
## License
Apache-2.0, consistently with the original aqua-rat dataset.
## Cite
If you use this dataset in research, please cite the original [AQuA-RAT paper](https://arxiv.org/pdf/1705.04146.pdf), and [Calc-X paper](https://arxiv.org/abs/2305.15017) as follows:
```bibtex
@inproceedings{kadlcik-etal-2023-soft,
title = "Calc-X and Calcformers: Empowering Arithmetical Chain-of-Thought through Interaction with Symbolic Systems",
author = "Marek Kadlčík and Michal Štefánik and Ondřej Sotolář and Vlastimil Martinek",
booktitle = "Proceedings of the The 2023 Conference on Empirical Methods in Natural Language Processing: Main track",
month = dec,
year = "2023",
address = "Singapore, Singapore",
publisher = "Association for Computational Linguistics",
url = "https://arxiv.org/abs/2305.15017",
}
```
语言:
- en(英语)
许可证:Apache-2.0
规模类别:
- 10K < 样本数量 < 100K
任务类别:
- 问答(question-answering)
可视化名称:带计算器的AQuA-RAT(AQuA-RAT with Calculator)
数据集信息:
- 配置名称:default
特征:
- 名称:id
数据类型:字符串
- 名称:question
数据类型:字符串
- 名称:chain
数据类型:字符串
- 名称:result
数据类型:字符串
- 名称:options
结构体:
- 名称:A
数据类型:字符串
- 名称:B
数据类型:字符串
- 名称:C
数据类型:字符串
- 名称:D
数据类型:字符串
- 名称:E
数据类型:字符串
- 名称:question_without_options
数据类型:字符串
划分集:
- 名称:train
字节数:72917721
样本数:94760
- 名称:validation
字节数:212928
样本数:254
- 名称:test
字节数:206180
样本数:254
下载大小:42057527
数据集总大小:73336829
- 配置名称:original-splits
特征:
- 名称:id
数据类型:字符串
- 名称:question
数据类型:字符串
- 名称:chain
数据类型:字符串
- 名称:result
数据类型:字符串
- 名称:options
结构体:
- 名称:A
数据类型:字符串
- 名称:B
数据类型:字符串
- 名称:C
数据类型:字符串
- 名称:D
数据类型:字符串
- 名称:E
数据类型:字符串
- 名称:question_without_options
数据类型:字符串
划分集:
- 名称:train
字节数:74265737
样本数:97467
- 名称:validation
字节数:212928
样本数:254
- 名称:test
字节数:206180
样本数:254
下载大小:42873590
数据集总大小:74684845
配置项:
- 配置名称:default
数据文件:
- 划分集:train
路径:data/train-*
- 划分集:validation
路径:data/validation-*
- 划分集:test
路径:data/test-*
- 配置名称:original-splits
数据文件:
- 划分集:train
路径:original-splits/train-*
- 划分集:validation
路径:original-splits/validation-*
- 划分集:test
路径:original-splits/test-*
# Calc-aqua_rat 数据集卡片
## 概述
本数据集是[AQuA-RAT(AQuA-RAT)](https://huggingface.co/datasets/aqua_rat)数据集的衍生版本,新增了上下文内调用SymPy(sympy)计算器的功能。
## 支持任务
本数据集旨在用于训练能够借助外部工具提升回答事实性的思维链(Chain-of-Thought)推理模型。该数据集提供了上下文场景,允许模型将推理链中的计算任务外包给计算器。
## 构建流程
本数据集通过自动评估从原始标注的**解题思路(rationale)**中提取的所有`SymPy`库候选调用而构建。候选选择以推理链中等号(`=`)的匹配为核心:对等式左侧进行求值,若其结果恰好出现在等式右侧,则判定为有效的工具调用。因此,计算器调用的提取过程可能存在假阴性(即本可使用计算器却未被提取),但不会产生已知的假阳性错误。
我们还在[Calc-X 合集(Calc-X collection)](https://huggingface.co/collections/MU-NLPC/calc-x-652fee9a6b838fd820055483)内部进行了数据集内和跨数据集的数据泄露检测。针对AQuA-RAT数据集,我们移除了训练集中少量与测试或验证集样本近似重复的条目。
提取过程的完整说明可参见[对应解析脚本](https://github.com/prompteus/calc-x/blob/7799a7841940b15593d4667219424ee71c74327e/gadgets/aqua.py#L19)。
**若您发现数据集或解析脚本新版本存在问题,欢迎提交报告或拉取请求(PR)。**
## 数据划分
已移除近似重复样本的数据集可通过默认配置加载,命令如下:
python
datasets.load_dataset("MU-NLPC/calc-aqua_rat")
若需使用未经过滤的原始版本,可执行以下命令:
python
datasets.load_dataset("MU-NLPC/calc-aqua_rat", "original-splits")
## 字段说明
- **id**:样本唯一标识符
- **question**:待解决问题的自然语言描述,包含可选答案
- **chain**:逐步骤的自然语言解题过程,其中自动插入了计算器调用及SymPy计算器的输出结果
- **result**:正确选项(A到E中的一个)
- **options**:包含5个候选选项(A、B、C、D、E)的字典,其中仅有一个正确答案
- **question_without_options**:与`question`字段内容一致,但不包含候选选项的版本
`id`、`question`、`chain`和`result`这四个字段是[Calc-X 合集](https://huggingface.co/collections/MU-NLPC/calc-x-652fee9a6b838fd820055483)中所有数据集的通用字段。
## 相关工作
本数据集是训练能够在推理阶段使用计算器的模型(我们将其称为Calcformers)这一整体工作的一部分。
- [**Calc-X 合集**](https://huggingface.co/collections/MU-NLPC/calc-x-652fee9a6b838fd820055483):用于训练Calcformers的数据集合集
- [**Calcformers 合集**](https://huggingface.co/collections/MU-NLPC/calcformers-65367392badc497807b3caf5):我们在Hugging Face上发布的训练得到的计算器使用型模型合集
- [**Calc-X与Calcformers论文**](https://arxiv.org/abs/2305.15017):对应研究论文
- [**Calc-X与Calcformers代码仓库**](https://github.com/prompteus/calc-x):对应开源代码仓库
以下为原始数据集的相关链接:
- [**原始AQuA-RAT数据集**](https://huggingface.co/datasets/aqua_rat)
- [**原始AQuA-RAT论文**](https://arxiv.org/pdf/1705.04146.pdf)
- [**原始AQuA-RAT代码仓库**](https://github.com/google-deepmind/AQuA)
## 许可证
许可证采用Apache-2.0协议,与原始AQuA-RAT数据集保持一致。
## 引用方式
若您在研究中使用本数据集,请引用原始[AQuA-RAT论文](https://arxiv.org/pdf/1705.04146.pdf)以及[Calc-X论文](https://arxiv.org/abs/2305.15017),引用格式如下:
bibtex
@inproceedings{kadlcik-etal-2023-soft,
title = "Calc-X and Calcformers: Empowering Arithmetical Chain-of-Thought through Interaction with Symbolic Systems",
author = "Marek Kadlčík and Michal Štefánik and Ondřej Sotolář and Vlastimil Martinek",
booktitle = "Proceedings of the The 2023 Conference on Empirical Methods in Natural Language Processing: Main track",
month = dec,
year = "2023",
address = "新加坡共和国,新加坡",
publisher = "Association for Computational Linguistics",
url = "https://arxiv.org/abs/2305.15017",
}
提供机构:
MU-NLPC
原始信息汇总
数据集概述
基本信息
- 名称: AQuA-RAT with Calculator
- 语言: 英语 (en)
- 许可证: Apache-2.0
- 大小: 10K<n<100K
- 任务类别: 问答 (question-answering)
数据集结构
- 配置名称: default 和 original-splits
- 特征:
- id: 字符串类型
- question: 字符串类型
- chain: 字符串类型
- result: 字符串类型
- options: 结构体,包含选项A至E,均为字符串类型
- question_without_options: 字符串类型
数据分割
- 训练集:
- default: 94760个样本,72917721字节
- original-splits: 97467个样本,74265737字节
- 验证集:
- default 和 original-splits: 254个样本,212928字节
- 测试集:
- default 和 original-splits: 254个样本,206180字节
数据集大小
- 下载大小: 42057527字节 (default) 和 42873590字节 (original-splits)
- 数据集大小: 73336829字节 (default) 和 74684845字节 (original-splits)
加载方式
- 默认配置:
datasets.load_dataset("MU-NLPC/calc-aqua_rat") - 原始分割:
datasets.load_dataset("MU-NLPC/calc-aqua_rat", "original-splits")
AI搜集汇总
数据集介绍
构建方式
该数据集通过自动评估从原始注释的*rationale*中提取的所有候选`sympy`库调用,构建而成。具体而言,构建过程基于链中等于符号('=')的匹配,其中等式左侧被评估,若结果在右侧紧密出现,则被接受为正确的计算器调用。此方法可能抑制了假阴性(即计算器本应被使用但未被使用的情况),但未发现任何已知的假阳性。此外,数据集还进行了数据泄露检测,特别是针对[Calc-X集合](https://huggingface.co/collections/MU-NLPC/calc-x-652fee9a6b838fd820055483),移除了与测试或验证样本接近重复的训练样本。
使用方法
使用该数据集时,用户可通过调用`datasets.load_dataset("MU-NLPC/calc-aqua_rat")`加载默认配置的数据集,或通过指定`"original-splits"`加载未过滤的版本。数据集适用于训练能够利用外部工具进行推理的链式思维模型,特别适合于需要高事实准确性的任务。用户可根据具体需求选择不同的数据集配置,并结合相关工具进行模型训练和评估。
背景与挑战
背景概述
MU-NLPC/Calc-aqua_rat数据集是基于AQuA-RAT数据集的扩展版本,旨在通过引入上下文中的sympy计算器调用来增强模型在推理过程中的事实性。该数据集由MU-NLPC团队创建,主要研究人员包括Marek Kadlčík、Michal Štefánik、Ondřej Sotolář和Vlastimil Martinek。其核心研究问题是如何使模型在推理过程中能够有效利用外部工具,如计算器,以提高答案的准确性。该数据集的构建过程通过自动评估从原始注释中提取的所有候选计算器调用,确保了计算器调用的准确性。这一研究对推动链式思维推理模型的发展具有重要意义,尤其是在需要精确计算的场景中。
当前挑战
MU-NLPC/Calc-aqua_rat数据集面临的挑战主要集中在两个方面。首先,如何在推理过程中准确识别并调用计算器,以避免误用或遗漏计算步骤,这是一个技术上的挑战。其次,数据集的构建过程中需要处理数据泄露问题,确保训练集与测试集之间的独立性,这涉及到复杂的去重和数据清洗工作。此外,尽管该数据集通过自动化的方式减少了人为错误,但仍需进一步验证和优化提取计算器调用的算法,以减少假阴性和假阳性的情况。这些挑战不仅影响数据集的质量,也对模型的训练效果和泛化能力提出了更高的要求。
常用场景
经典使用场景
Calc-aqua_rat数据集的经典使用场景主要集中在训练和评估链式推理(Chain-of-Thought)模型,这些模型能够利用外部工具(如sympy计算器)来增强其推理过程的准确性。通过在推理链中嵌入计算器调用,模型能够更精确地处理数学计算问题,从而提高其在复杂问题上的表现。
解决学术问题
该数据集解决了在自然语言处理领域中,如何使模型在推理过程中有效利用外部工具的学术问题。通过引入计算器调用,模型能够更准确地执行数学运算,减少因计算错误导致的推理偏差,从而提升模型的推理能力和事实性。这一研究对推动链式推理模型的发展具有重要意义。
实际应用
在实际应用中,Calc-aqua_rat数据集可用于开发和优化需要复杂数学推理能力的智能系统,如教育辅导系统、自动化问题解答平台等。通过集成计算器功能,这些系统能够更准确地解决用户提出的数学问题,提供更高质量的服务。
数据集最近研究
最新研究方向
在自然语言处理领域,MU-NLPC/Calc-aqua_rat数据集的最新研究方向主要集中在提升模型在推理过程中使用外部工具的能力,特别是通过引入计算器来增强模型响应的准确性。该数据集通过在上下文中嵌入sympy计算器的调用,训练模型在推理链中动态使用计算器进行计算,从而提高模型在复杂数学问题上的表现。这一研究方向不仅推动了Chain-of-Thought推理模型的发展,还为未来能够与外部工具交互的智能系统奠定了基础。此外,该数据集的构建过程强调了数据泄露检测和去重处理,确保了数据集的高质量和适用性,为相关研究提供了可靠的实验平台。
以上内容由AI搜集并总结生成


