taiwan-ly-law-research
收藏Hugging Face2024-08-03 更新2024-12-12 收录
下载链接:
https://huggingface.co/datasets/aigrant/taiwan-ly-law-research
下载链接
链接失效反馈官方服务:
资源简介:
该数据集包含来自台湾立法机构的法律研究文件,这些文件不定期发布,旨在提供对社会问题的法律方面的更好理解。数据集中的文档富含技术术语,可作为训练数据使用。数据字段包括研究文档ID、标题、相关法律名称、作者、发布日期、全文内容和下载链接。数据集由【g0v 零時小學校】繁體中文AI 開源實踐計畫赞助,并由報導者和歐噴有限公司提供支持。
创建时间:
2024-07-23
原始信息汇总
台湾立法院法律研究数据集
概述
该数据集包含台湾立法院不定期发布的法律研究文件,旨在帮助更好地理解法律方面的社会问题。这些文件富含技术术语,可作为训练数据使用。
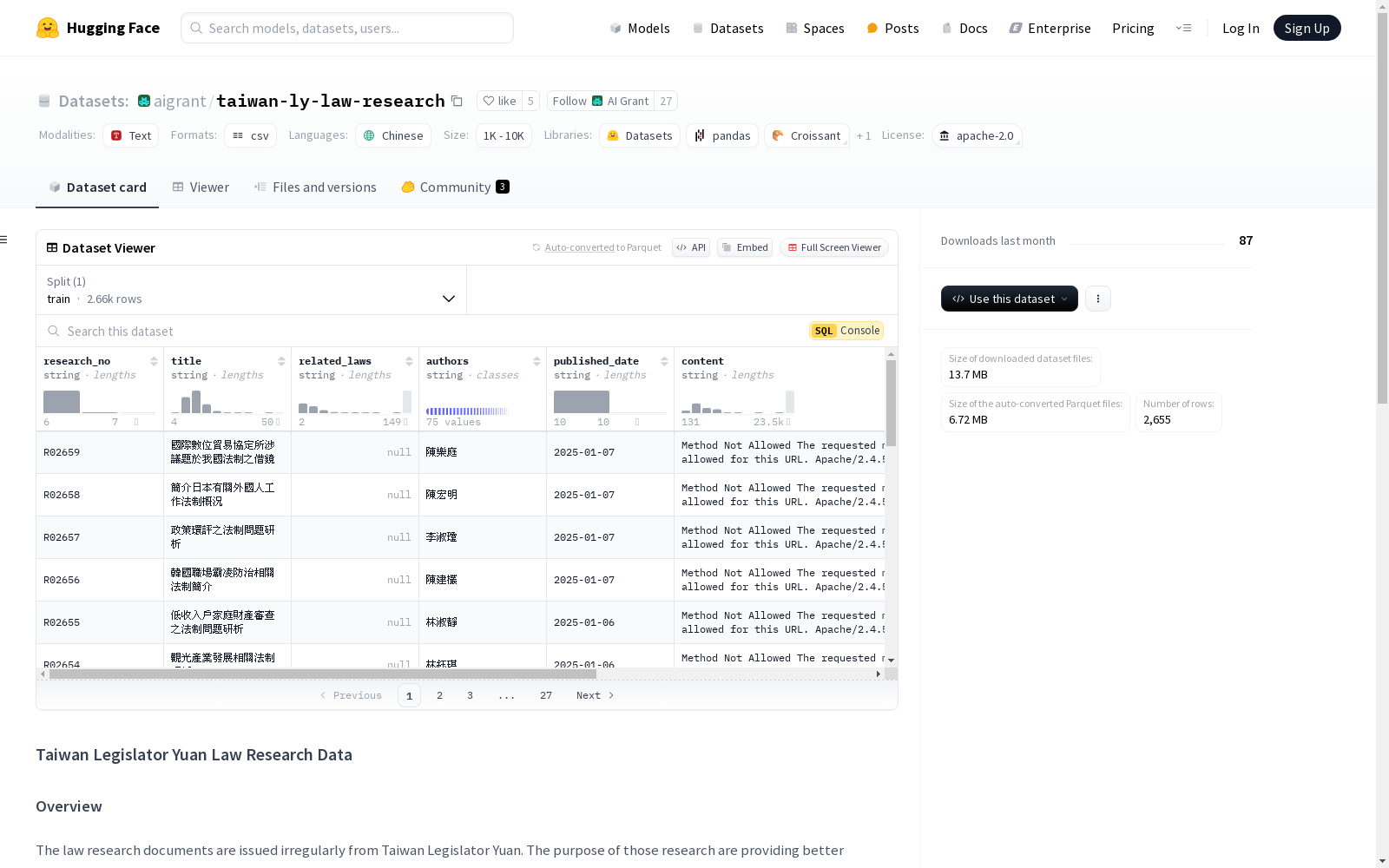
数据字段
| 字段名称 | 描述 |
|---|---|
| research_no | 研究文件的ID |
| title | 文件标题 |
| related_laws | 文件中涉及的相关法律名称,以;分隔 |
| authors | 文件作者,以;分隔 |
| published_date | 文件发布日期,格式为YYYY-mm-dd |
| content | 文件的全文内容,原始内容也可在.html格式的文件中找到,路径为html/{research_no}.html |
| doc_url | 文件在ly.gov.tw上的下载链接 |
许可证
该数据集的许可证为Apache-2.0。
搜集汇总
数据集介绍
构建方式
该数据集由台湾立法院发布的法律研究文档构成,旨在从法律角度提供对社会问题的深入理解。文档通过爬虫技术从立法院官网抓取,涵盖了丰富且专业的技术术语,适合作为训练数据。尽管在第九届和第十届期间存在部分文档链接缺失的问题,但团队承诺将尽快补充这些数据。
特点
该数据集包含多个关键字段,如研究编号、标题、相关法律、作者、发布日期、文档内容及下载链接。文档内容以全文形式呈现,并附有HTML格式的原始内容链接,便于用户进行深入分析和研究。数据集的语言为中文,特别适合用于中文自然语言处理任务。
使用方法
用户可以通过研究编号、标题或相关法律等字段进行数据检索和分析。文档内容可直接用于文本挖掘、法律术语提取等任务。此外,数据集还提供了原始HTML格式的文档链接,方便用户进行更细致的文本分析。数据集的使用需遵循Apache 2.0许可协议,确保在合法范围内进行研究和应用。
背景与挑战
背景概述
台湾立法院法律研究数据集(taiwan-ly-law-research)是由台湾立法院发布的法律研究文献集合,旨在通过法律视角深入探讨社会问题。该数据集由【g0v 零時小學校】繁體中文AI 開源實踐計畫赞助,涵盖了丰富的研究文献,包括研究编号、标题、相关法律、作者、发布日期、内容及文档链接等字段。这些文献不仅为法律研究提供了宝贵的资源,也为自然语言处理领域的技术发展提供了训练数据。
当前挑战
该数据集面临的挑战主要包括两个方面:首先,由于爬虫技术的限制,部分文献的下载链接在第九届和第十届期间存在缺失,这影响了数据的完整性和可用性。其次,文献中大量使用专业术语和复杂的法律语言,这对自然语言处理模型的训练提出了更高的要求,尤其是在理解和处理这些专业内容时,模型需要具备更高的准确性和深度理解能力。
常用场景
经典使用场景
在法学研究领域,taiwan-ly-law-research数据集为研究者提供了丰富的法律文献资源,特别是针对台湾地区的立法研究。该数据集包含了大量的法律研究报告,涵盖了从法律条文解释到社会问题法律分析的多方面内容。研究者可以利用这些数据进行法律文本分析、法律条文关联性研究以及法律政策影响评估等。
实际应用
在实际应用中,taiwan-ly-law-research数据集被广泛用于法律教育、法律咨询和政策制定等领域。教育机构可以利用这些数据进行案例教学,法律顾问可以引用这些报告进行法律分析,政策制定者则可以参考这些研究来优化法律政策。
衍生相关工作
基于taiwan-ly-law-research数据集,已经衍生出多项相关研究工作,包括法律文本的自然语言处理模型开发、法律知识图谱构建以及法律智能问答系统的研究。这些工作不仅提升了法律文本的处理效率,也为法律智能化的实现提供了技术支持。
以上内容由遇见数据集搜集并总结生成


