PIÖTOST
收藏github2023-01-10 更新2024-05-31 收录
下载链接:
https://github.com/edoardosignoroni/piotost
下载链接
链接失效反馈官方服务:
资源简介:
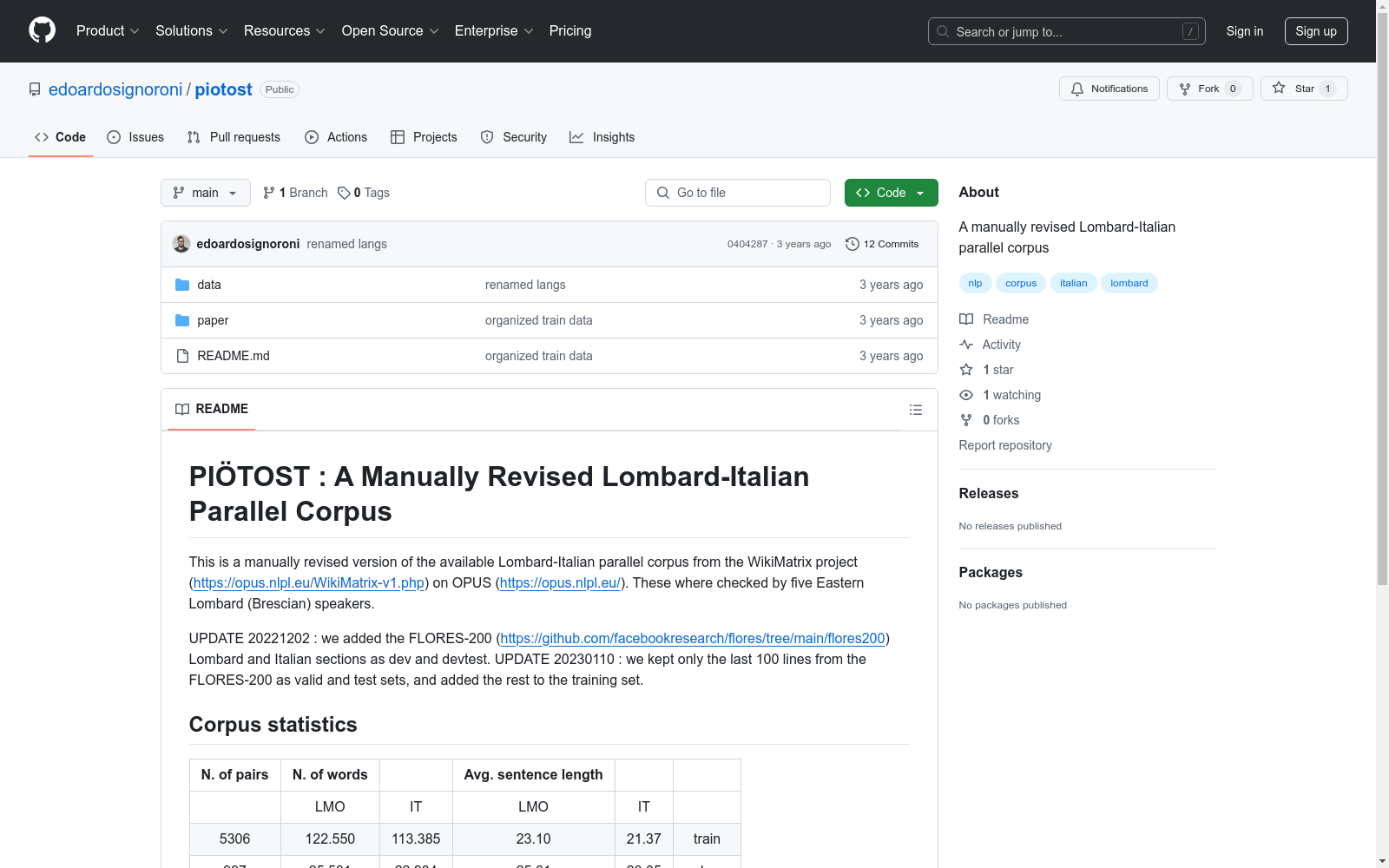
PIÖTOST是一个手动修订的Lombard-Italian平行语料库,来源于WikiMatrix项目,由五位Eastern Lombard(Brescian)发言人进行了检查。数据集包括训练、开发和测试集,并提供了详细的统计信息。
PIÖTOST is a manually revised Lombard-Italian parallel corpus derived from the WikiMatrix project, which has been reviewed by five Eastern Lombard (Brescian) speakers. The dataset includes training, development, and test sets, and provides detailed statistical information.
创建时间:
2022-11-01
原始信息汇总
数据集概述
数据集名称
- 名称: PIÖTOST : A Manually Revised Lombard-Italian Parallel Corpus
数据集来源
- 原始来源: WikiMatrix project on OPUS
- 修订版本: 由五名Eastern Lombard (Brescian) 母语者手动修订
数据集更新
- 20221202更新: 添加了FLORES-200的Lombard和Italian部分作为dev和devtest。
- 20230110更新: 保留了FLORES-200的最后100行作为valid和test sets,其余部分添加到训练集。
数据集统计
- 训练集:
- 句子对数量: 5306
- LMO词数: 122,550
- Italian词数: 113,385
- LMO平均句子长度: 23.10
- Italian平均句子长度: 21.37
- dev集:
- 句子对数量: 997
- LMO词数: 25,531
- Italian词数: 22,984
- LMO平均句子长度: 25.61
- Italian平均句子长度: 23.05
- devtest集:
- 句子对数量: 1012
- LMO词数: 26,954
- Italian词数: 24,311
- LMO平均句子长度: 26.63
- Italian平均句子长度: 24.02
引用信息
-
作者: Edoardo Signoroni
-
出版物: RASLAN 2022 Recent Advances in Slavonic Natural Language Processing
-
引用格式:
Signoroni, E. (2022). Piötòst Ché Niènt, Mèi Piötòst-A Manually Revised Lombard-Italian Parallel Corpus. RASLAN 2022 Recent Advances in Slavonic Natural Language Processing, 105.
@article{signoroni2022piotost, title={Pi{"o}t{
o}st Ch{e} Ni{e}nt, M{e}i Pi{"o}t{o}st-A Manually Revised Lombard-Italian Parallel Corpus}, author={Signoroni, Edoardo}, journal={RASLAN 2022 Recent Advances in Slavonic Natural Language Processing}, pages={105}, year={2022} }
搜集汇总
数据集介绍
构建方式
PIÖTOST数据集是基于WikiMatrix项目中的伦巴第语-意大利语平行语料库,经过五位东伦巴第语(布雷西亚方言)母语者的手动修订而成。该数据集进一步整合了FLORES-200项目中的伦巴第语和意大利语部分,将其划分为开发集和开发测试集。在2023年1月的更新中,数据集仅保留了FLORES-200的最后100行作为验证集和测试集,其余部分则被纳入训练集。
特点
PIÖTOST数据集包含了5306对伦巴第语-意大利语平行句子,涵盖了122,550个伦巴第语单词和113,385个意大利语单词。数据集的句子平均长度分别为伦巴第语23.10个单词和意大利语21.37个单词。开发集和开发测试集分别包含997和1012对句子,句子长度略高于训练集。该数据集的高质量手动修订确保了其语言准确性和文化适应性,适用于机器翻译和语言学研究。
使用方法
PIÖTOST数据集可用于训练和评估伦巴第语-意大利语机器翻译模型。用户可以通过加载训练集、开发集和开发测试集进行模型训练、调优和性能评估。数据集的引用格式为Signoroni, E. (2022)的文献,确保在使用时遵循学术规范。此外,数据集的结构化格式便于直接应用于自然语言处理工具链,支持多种实验设计和分析需求。
背景与挑战
背景概述
PIÖTOST数据集是一个经过人工修订的伦巴第语-意大利语平行语料库,源自WikiMatrix项目中的原始语料库。该数据集由五位东伦巴第语(布雷西亚方言)使用者进行校对,确保了语料的高质量。数据集于2022年发布,主要研究人员为Edoardo Signoroni,其研究背景涉及斯拉夫自然语言处理领域。PIÖTOST的创建旨在为低资源语言(如伦巴第语)的机器翻译和语言学研究提供支持,填补了该领域的数据空白。该数据集不仅扩展了WikiMatrix项目的应用范围,还为低资源语言的自动翻译系统开发提供了重要资源。
当前挑战
PIÖTOST数据集面临的挑战主要体现在两个方面。首先,伦巴第语作为一种低资源语言,其语言资源的稀缺性使得数据集的构建过程充满挑战,尤其是在确保语料库的多样性和代表性方面。其次,人工校对过程虽然提升了数据质量,但也带来了时间和人力成本的高昂问题。此外,数据集的规模相对较小,可能限制了其在训练大规模机器翻译模型时的应用效果。如何在有限的资源下进一步扩展数据集规模,并保持高质量的语言对齐,是该领域未来需要解决的关键问题。
常用场景
经典使用场景
PIÖTOST数据集在语言学和自然语言处理领域中被广泛用于研究语言翻译和语言模型训练。特别是在处理低资源语言如伦巴第语(Lombard)时,该数据集提供了一个高质量的平行语料库,支持从伦巴第语到意大利语的精确翻译研究。
衍生相关工作
基于PIÖTOST数据集,研究者们已经开发出多种先进的自然语言处理工具和模型。例如,利用该数据集训练的神经机器翻译模型在伦巴第语翻译任务中表现出色。此外,该数据集还激发了更多关于低资源语言处理的研究,推动了相关算法和技术的进步。
数据集最近研究
最新研究方向
在自然语言处理领域,低资源语言的机器翻译一直是研究的热点之一。PIÖTOST数据集作为一个经过人工修订的伦巴第语-意大利语平行语料库,为这一领域提供了宝贵的资源。该数据集不仅包含了从WikiMatrix项目中提取的原始语料,还整合了FLORES-200中的伦巴第语和意大利语部分,进一步丰富了数据集的多样性和实用性。近年来,随着多语言模型和迁移学习技术的发展,PIÖTOST数据集在低资源语言翻译任务中的应用潜力逐渐显现。研究者们通过该数据集,能够更好地训练和评估模型在伦巴第语等低资源语言上的表现,推动了跨语言信息处理技术的进步。此外,该数据集的发布也为语言学和文化遗产保护领域提供了新的研究工具,有助于保存和传播濒危语言的独特文化价值。
以上内容由遇见数据集搜集并总结生成


