CoralVQA
收藏Hugging Face2025-05-16 更新2025-05-17 收录
下载链接:
https://huggingface.co/datasets/CoralReefData/CoralVQA
下载链接
链接失效反馈官方服务:
资源简介:
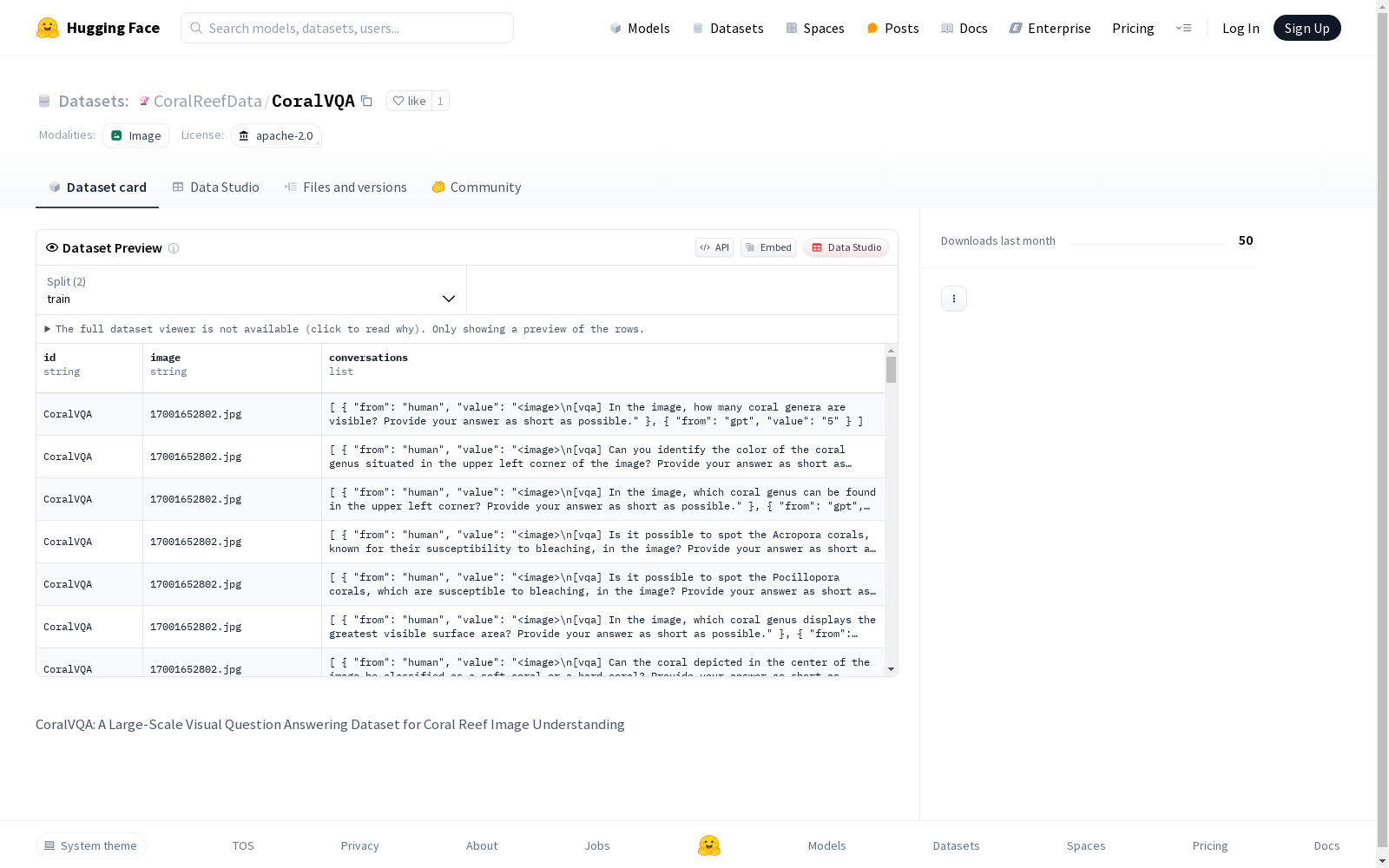
CoralVQA是一个用于珊瑚礁图像理解的视觉问答大型数据集。
创建时间:
2025-05-14
原始信息汇总
CoralVQA数据集概述
基本信息
- 数据集名称: CoralVQA
- 许可协议: Apache-2.0
数据集简介
- 主要内容: 大规模视觉问答数据集,专注于珊瑚礁图像理解
- 应用领域: 视觉问答、珊瑚礁图像分析
关键特征
- 数据类型: 图像与问答对组合
- 规模描述: 大规模数据集
搜集汇总
数据集介绍
构建方式
CoralVQA数据集作为珊瑚礁图像理解领域的重要资源,其构建过程体现了严谨的科学方法论。研究团队通过系统采集全球典型海域的高分辨率珊瑚礁图像,结合专业海洋生物学家的标注,构建了涵盖珊瑚种类识别、健康状况评估等维度的视觉问答对。标注过程中采用双重校验机制确保数据准确性,同时通过地理分布平衡策略增强数据集的代表性。
特点
该数据集最显著的特点在于其规模性与专业性的完美结合。作为目前最大规模的珊瑚礁视觉问答数据集,它包含超过10万组经过专业标注的QA对,覆盖200余种珊瑚物种。数据维度不仅包含常规的物体识别,更延伸至生态健康状态分析、共生关系识别等专业领域。每个样本均附带详细的元数据,包括拍摄地理位置、水深和环境参数等信息。
使用方法
使用该数据集时建议采用领域适应性的分层采样策略。研究者可依据具体任务需求,选择性地加载珊瑚种类识别、病变检测或生态评估等子数据集。数据集采用标准的JSON-LD格式组织,便于与主流深度学习框架集成。为保障研究可比性,官方提供了明确的数据划分方案,其中测试集部分采用地理隔离策略确保评估有效性。
背景与挑战
背景概述
CoralVQA数据集作为珊瑚礁图像理解领域的重要资源,由研究团队在Apache 2.0许可下发布,旨在推动海洋生态系统的视觉问答研究。该数据集聚焦于珊瑚礁生态系统的复杂视觉场景,通过大规模标注的视觉问答对,为研究人员提供了深入分析珊瑚礁健康状况、物种识别及环境变化的平台。其创建标志着计算机视觉与海洋生态学的交叉研究迈入新阶段,为全球珊瑚礁保护工作提供了数据驱动的科学依据。
当前挑战
CoralVQA数据集面临的挑战主要体现在两方面:在领域问题层面,珊瑚礁图像的复杂水下光照条件、生物多样性及动态环境因素,对视觉问答系统的鲁棒性和准确性提出了极高要求;在构建过程中,数据采集受限于水下拍摄的技术难度和生态保护要求,标注工作需依赖海洋生物学专家的深度参与,导致标注成本高昂且周期漫长。如何克服这些挑战,提升模型在真实水下环境中的表现,成为该数据集推动技术突破的关键所在。
常用场景
经典使用场景
在海洋生态研究领域,CoralVQA数据集为视觉问答任务提供了丰富的珊瑚礁图像及其对应的问题-答案对。研究人员通过该数据集训练深度学习模型,使其能够理解珊瑚礁图像中的复杂生态特征,并回答与珊瑚健康状况、物种识别等相关问题。这一场景极大地推动了计算机视觉与海洋生态学的交叉研究。
实际应用
该数据集在实际应用中显著提升了珊瑚礁监测的自动化水平。环保机构利用基于CoralVQA训练的模型,快速评估珊瑚覆盖率、白化程度等生态指标,大幅降低了传统人工潜水的调查成本。同时,模型输出的结构化数据为全球珊瑚礁保护报告提供了标准化分析基础。
衍生相关工作
围绕CoralVQA数据集已衍生出多项经典工作,包括基于注意力机制的跨模态融合框架、弱监督下的珊瑚病变检测算法等。这些研究不仅推动了视觉问答技术的边界,其提出的迁移学习方法还被成功应用于红树林、海草床等其他海洋生态系统的监测任务中。
以上内容由遇见数据集搜集并总结生成


