oasst
收藏Hugging Face2024-10-06 更新2024-12-12 收录
下载链接:
https://huggingface.co/datasets/zakariarada/oasst
下载链接
链接失效反馈官方服务:
资源简介:
该数据集由H2O.ai设计,用于微调对话模型,特别是在多轮问答场景中。它包含结构化的对话,每个对话通过唯一标识符链接,以在多轮中保持上下文。数据集结构包括'instruction'、'output'、'id'和'parent_id'字段,用于跟踪层次对话流。它适用于微调模型以进行多轮对话任务、指令跟随对话和聊天机器人应用。该数据集由H2O.ai策划,旨在增强对话模型管理多轮对话的能力,并具有上下文意识。
This dataset was designed by H2O.ai for fine-tuning conversational models, particularly in multi-turn question-answering scenarios. It contains structured dialogues, where each dialogue is linked via a unique identifier to maintain context across multiple conversation turns. The dataset structure includes fields "instruction", "output", "id", and "parent_id" to track hierarchical dialogue flows. It is suitable for fine-tuning models for multi-turn dialogue tasks, instruction-following dialogues, and chatbot applications. Curated by H2O.ai, this dataset aims to enhance the contextual awareness and multi-turn dialogue management capabilities of conversational models.
创建时间:
2024-10-06
原始信息汇总
Conversational Dataset
数据集概述
该数据集由H2O.ai设计,用于微调对话模型,特别是在多轮问答场景中。它包含结构化的对话,每个对话通过唯一标识符链接,以在多轮中保持上下文。
数据集详情
数据集描述
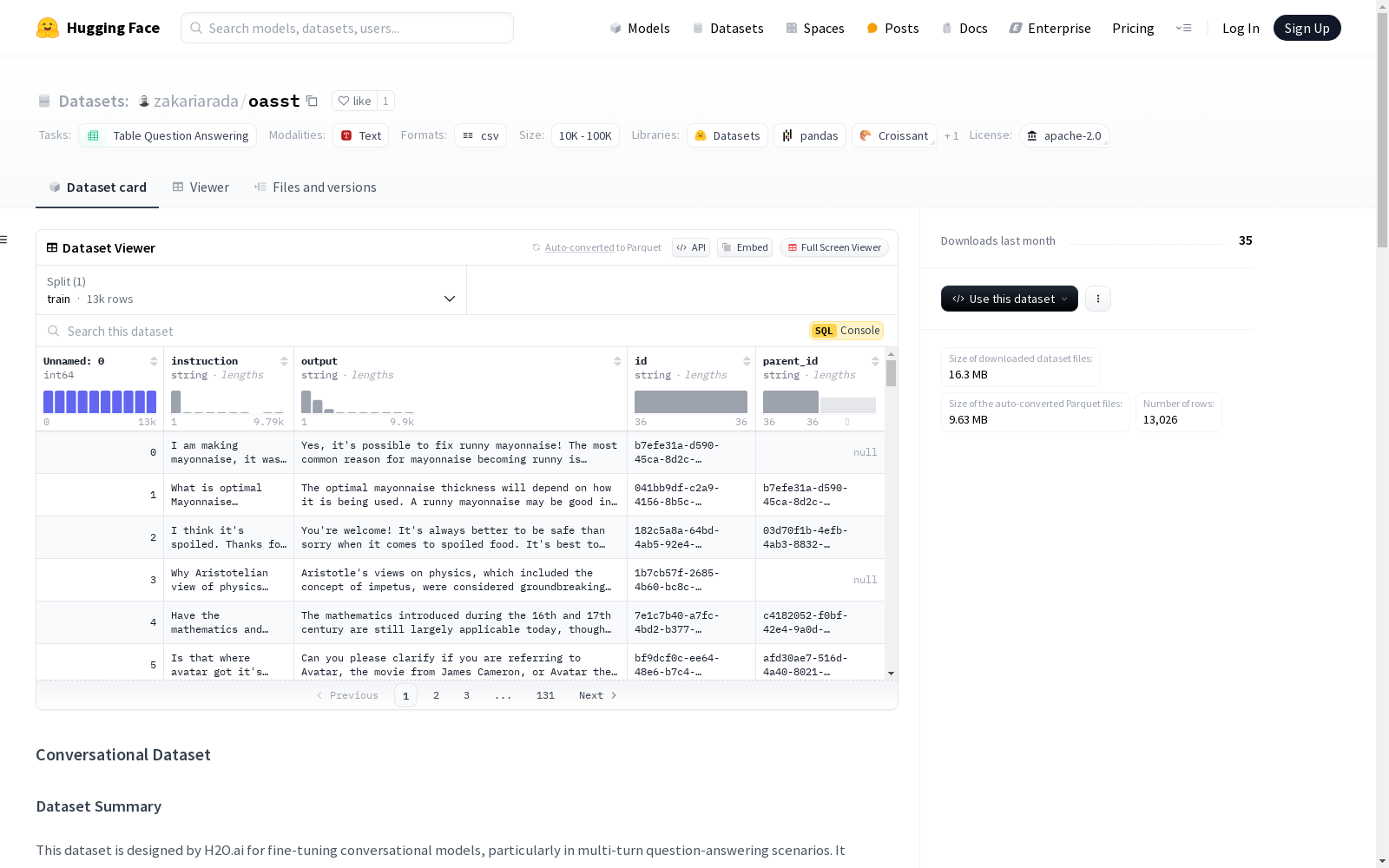
该数据集包括多轮对话,结构化方式为每个instruction有一个关联的output,并带有id和parent_id字段以跟踪层次对话流。该数据集使模型能够理解和生成上下文适当的响应,适用于聊天机器人、任务型对话系统和其他对话AI应用。
- 由: H2O.ai 策划
- 语言(NLP): 英语
- 许可证: Apache 2.0
数据集来源
- 仓库: [Link to dataset repository on Hugging Face]
- 论文 [可选]: [Link to relevant papers, e.g., Hugging Face papers or H2O.ai papers]
- 演示: [Add link if there’s an available demo]
用途
直接使用
该数据集旨在用于微调以下模型:
- 多轮对话任务
- 指令跟随对话
- 聊天机器人或虚拟助手应用
超出范围的使用
该数据集在不相关的任务中(如分类或摘要)可能表现不佳,除非进行额外的预处理。
数据集结构
- Instruction: 提供给模型的输入或提示。
- Output: 模型预期的响应。
- Id: 每个交互对的唯一标识符。
- Parent_id: 将指令与其先前的上下文链接,使模型能够保持对话流程。
数据集创建
策划理由
H2O.ai创建此数据集以增强对话模型管理多轮对话的能力,并具有上下文意识。这是公司通过强大、易于使用的工具实现AI民主化承诺的一部分。
源数据
数据收集和处理
数据从各种对话AI场景中收集,经过策划以启用上下文跟踪。数据集经过清理和结构化,以确保相关性,重点关注指令和对话的准确性。
源数据生产者是谁?
该数据集由H2O.ai策划,这是一家在AI云领域领先的公司,以其为企业应用实现AI民主化的工作而闻名。
注释
该数据集不包括任何额外的手动注释,除了结构化的输入-输出对。
偏见、风险和局限性
该数据集可能携带从其收集来源固有的偏见。鼓励用户评估和调整其模型以减轻任何偏见,特别是在敏感或企业应用中。
建议
建议用户在涉及决策或客户接触应用的上下文中,彻底测试基于此数据集微调的模型,以确保公平性和偏见。
引用
如果您使用此数据集,请引用:
bibtex @dataset{h2oai_conversational_dataset, author = {H2O.ai}, title = {Multi-turn Conversational Dataset for Chatbot Fine-tuning}, year = {2024}, url = {Link to your dataset}, }
搜集汇总
数据集介绍
构建方式
该数据集由H2O.ai精心构建,旨在通过多轮对话场景优化对话模型的微调。数据收集自多种对话AI场景,经过清洗和结构化处理,确保每段对话的指令与输出之间具有明确的关联性。通过`id`和`parent_id`字段,数据集能够有效追踪对话的层次结构,从而维持上下文的一致性。
特点
该数据集的核心特点在于其多轮对话的结构化设计,每段对话均包含指令和对应的输出,并通过唯一标识符链接上下文。这种设计使得模型能够在复杂的对话场景中生成符合语境的响应,特别适用于聊天机器人、任务导向型对话系统等应用。数据集以英语为主,采用Apache 2.0许可,确保了其开放性和可扩展性。
使用方法
该数据集主要用于微调多轮对话任务中的模型,特别适合用于指令跟随型对话和虚拟助手应用的开发。用户可以通过加载数据集,利用其结构化对话数据训练模型,以提升其在复杂对话场景中的表现。需要注意的是,该数据集在非对话类任务(如分类或摘要生成)中可能表现不佳,需额外预处理。
背景与挑战
背景概述
OASST数据集由H2O.ai于2024年推出,旨在优化多轮对话场景中的对话模型微调。该数据集包含结构化的对话数据,每个对话通过唯一的标识符链接,以保持多轮对话的上下文连贯性。H2O.ai作为AI领域的领先企业,致力于通过强大的工具推动AI的民主化应用。该数据集特别适用于聊天机器人、任务型对话系统等对话式AI应用,帮助模型理解和生成符合上下文的响应。
当前挑战
OASST数据集在解决多轮对话任务时面临的主要挑战包括:1) 上下文连贯性的维护,模型需要在多轮对话中准确捕捉并利用历史信息;2) 数据偏差问题,由于数据来源的多样性,数据集可能携带潜在的偏差,需在模型训练中加以识别和缓解;3) 数据结构的复杂性,数据集通过`id`和`parent_id`字段追踪对话层级,这对模型的上下文理解能力提出了更高要求。此外,构建过程中需确保数据的准确性和对话的自然性,这对数据清洗和结构化处理提出了较高标准。
常用场景
经典使用场景
OASST数据集专为多轮对话场景设计,特别适用于微调对话模型。其结构化的对话数据通过唯一的标识符链接,确保模型能够在多轮对话中保持上下文连贯性。这一特性使其成为开发聊天机器人、任务型对话系统等应用的理想选择。
衍生相关工作
基于OASST数据集,许多经典研究工作得以展开。例如,研究人员利用该数据集开发了更高效的上下文感知对话模型,进一步提升了对话系统的性能。此外,该数据集还催生了一系列关于对话系统公平性和偏见缓解的研究,推动了对话AI领域的伦理发展。
数据集最近研究
最新研究方向
近年来,随着对话式人工智能技术的快速发展,多轮对话数据集如OASST在提升模型上下文理解能力方面发挥了关键作用。该数据集通过独特的标识符和层次化对话流结构,为模型提供了丰富的上下文信息,使其能够在多轮对话中生成更加连贯和准确的响应。当前研究热点集中在如何利用此类数据集进一步提升对话系统的上下文感知能力,尤其是在复杂任务型对话和虚拟助手应用中。此外,研究者们也在探索如何通过数据增强和迁移学习技术,减少数据集中的潜在偏见,确保模型在敏感场景下的公平性和可靠性。OASST数据集的广泛应用不仅推动了对话式AI技术的进步,也为企业级应用提供了强有力的支持。
以上内容由遇见数据集搜集并总结生成


