LoT-insts
收藏arXiv2023-02-19 更新2024-06-21 收录
下载链接:
https://lot-insts.github.io/
下载链接
链接失效反馈官方服务:
资源简介:
LoT-insts是由上海交通大学创建的大型机构名称归一化数据集,包含超过25,000个类别,自然呈现长尾分布。数据集从Microsoft Academic Graph(MAG)中提取,通过清理和过滤过程构建,确保数据的高质量和多样性。该数据集特别关注长尾和开放集分类问题,旨在解决现实世界中机构名称的多样性和复杂性问题,适用于文本分类、信息检索和作者概况分析等下游任务。
LoT-insts is a large-scale institutional name normalization dataset created by Shanghai Jiao Tong University, which contains over 25,000 categories and exhibits a natural long-tailed distribution. Extracted from Microsoft Academic Graph (MAG), the dataset is constructed through cleaning and filtering processes to ensure high data quality and diversity. Specifically focusing on long-tailed and open-set classification problems, it aims to address the diversity and complexity of institutional names in real-world scenarios, and is applicable to downstream tasks such as text classification, information retrieval and author profile analysis.
提供机构:
上海交通大学
创建时间:
2023-02-19
搜集汇总
数据集介绍
构建方式
LoT-insts数据集源自微软学术图谱(Microsoft Academic Graph),通过提取论文作者所属机构字段构建。首先从PaperAuthorAffiliations.txt中抽取原始机构名称与标准化ID的映射关系,经过去除HTML标签、字符规范化等预处理后,利用置信度投票机制消除同一原始名称指向多个ID的歧义。随后通过子串检测构建无向图,在每个连通分量中仅保留一个代表样本,以滤除占比超过90%的冗余简单样例。最终按类别全局频次(阈值为5和20)划分为多样本、中样本、少样本子集,并额外抽取2%类别作为零样本开放测试集,形成涵盖25,129个类别的自然长尾分布数据集。
特点
该数据集是首个面向自然语言处理领域的原生长尾分布文本分类基准,相较于ImageNet-LT等人工重采样数据集,其类别频率遵循真实世界分布规律而非帕累托采样。训练样本量达223万条,较现有最大长尾数据集高出一个数量级,且包含512个零样本开放类别。数据呈现显著的长尾特性:头部6693个类别占据97.4%的训练样本,而尾部12990个类别平均仅有1.1个样本。独特的开放集验证任务(OSV)通过对比从未见过类别中的样本对,评估模型对未知类别的判别能力,为长尾学习研究提供了全新的评估维度。
使用方法
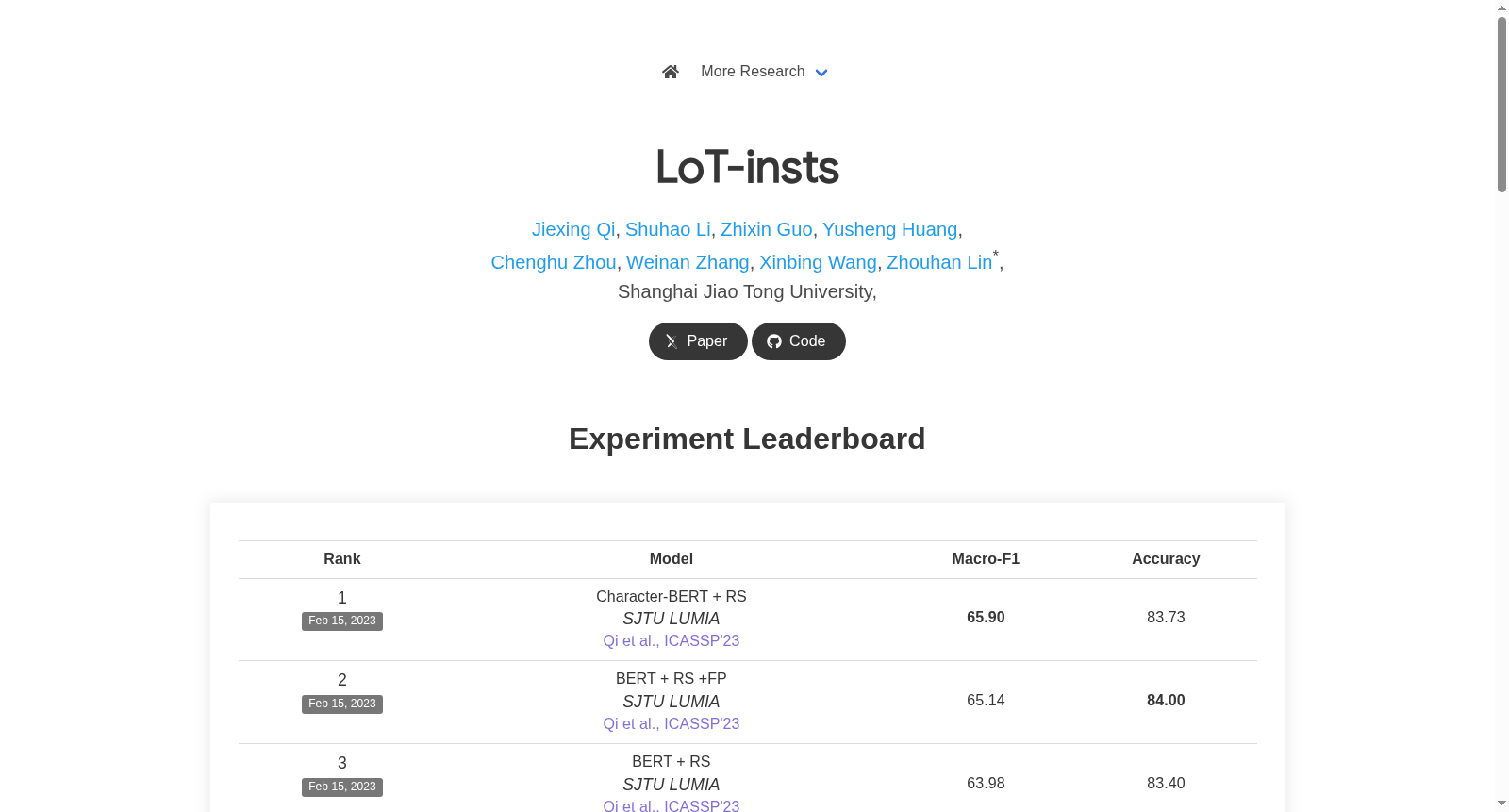
数据集支持三类任务:闭集分类(CSC)要求模型从已知类别中预测标准化机构名称,使用准确率和宏F1作为指标;开集分类(OSC)通过设定已知类别概率阈值检测未见类别,以ROC曲线评估;开集验证(OSV)则需判断两个样本是否属于同一未见类别。研究者可直接加载预划分的多/中/少样本训练集与测试集,复现论文中提供的朴素贝叶斯、sCool、CompanyDepot、FastText及BERT基线方法。建议采用字符级BERT模型处理机构名称中的拼写错误与OOV词汇,并配合重采样策略缓解类别不平衡问题。
背景与挑战
背景概述
真实世界的数据分布往往呈现出长尾特性,即少数类别拥有大量样本,而多数类别仅包含少量实例。这一现象在机构名称标准化任务中尤为突出,全球范围内学术机构名称的变体繁多,给信息检索、作者画像等下游任务带来了严峻挑战。为深入探究该问题,上海交通大学团队于2023年构建了LoT-insts数据集,该数据集源自微软学术图谱,包含超过25,000个类别,训练样本数达220余万,呈现出天然的长尾分布,而非人工重采样所得。作为自然语言处理领域首个聚焦长尾与开集分类问题的公开数据集,LoT-insts不仅提供了大规模的训练数据,还通过划分多样本、中样本、少样本和零样本测试子集,为长尾文本分类研究奠定了重要基础,推动了相关技术的发展。
当前挑战
LoT-insts数据集所面临的挑战主要体现在两个方面。首先,在领域问题层面,机构名称标准化任务需处理因OCR解析、PDF提取等过程导致的拼写错误、缩写变体、粒度差异等词汇多样性问题,同时长尾分布下大量少样本和零样本类别的存在,使得传统分类模型难以有效泛化,尤其是对未见类别的识别与验证构成了显著困难。其次,在数据集构建过程中,原始数据存在大量标注噪声,如同一个原始名称映射到多个不同机构ID的冲突,以及冗余样本占据主导地位的问题——超过90%的样本可通过简单字符串匹配正确分类,掩盖了更具挑战性的样本。为此,研究团队设计了基于投票机制的冲突消解方法和基于子串关系的冗余过滤策略,以提升数据质量,但如何在保留数据真实分布特性的同时平衡类别不平衡,仍是持续存在的挑战。
常用场景
经典使用场景
LoT-insts数据集专为长尾分布下的文本分类任务而设计,其核心应用场景在于机构名称归一化。该任务要求将海量非标准化机构名称(如缩写、拼写错误、不同粒度表述)映射至其规范形式,是自然语言处理中极具挑战性的长尾分类问题。数据集包含超过2.5万个类别,天然呈现长尾分布,并细分为多样本、中样本、少样本及零样本开放集四个子集,为评估模型在不同数据丰度下的泛化能力提供了标准化测试平台。研究者可基于该数据集开展封闭集分类、开放集分类及开放集验证三项经典任务,全面检验模型对高频类的拟合能力与对低频类及未见类的判别鲁棒性。
解决学术问题
该数据集填补了自然语言处理领域缺乏长尾分布文本分类基准的空白,解决了传统平衡数据集无法真实反映现实世界类别分布的问题。相较于计算机视觉领域人工重采样的长尾数据集,LoT-insts天然呈现的长尾特性更贴近真实场景,其庞大的训练规模(超220万样本)使研究者得以探索重采样、重加权、迁移学习等策略在文本分类中的有效性。更重要的是,数据集首次引入开放集验证任务,推动模型在零样本场景下对未见类别的判别能力研究,为克服学术文献中机构名称歧义性、冗余性等下游应用瓶颈提供了关键实验基础,显著促进了自然语言处理领域从封闭分类向开放长尾分类的范式演进。
衍生相关工作
LoT-insts的发布催生了一系列面向长尾文本分类的经典工作。在方法层面,研究者基于该数据集验证了重采样策略(如类平衡采样)和重加权损失函数(如焦点损失)在文本领域的适用性,并推动了字符级预训练模型的发展——论文提出的字符级BERT模型通过掩码语言建模在机构名称语料上预训练,显著提升了少样本与零样本场景的泛化能力。此外,对比学习机制的引入(如开放集验证任务中的对比损失)为未见类判别提供了新范式。在基准方法复现方面,该数据集系统对比了朴素贝叶斯、FastText、sCool、CompanyDepot及原始BERT等方法的性能差异,为后续研究建立了公平的评估基线,并启发了跨领域(如从计算机视觉到自然语言处理)长尾学习技术的迁移与融合。
以上内容由遇见数据集搜集并总结生成


