OpenSeeker-v1-Data
收藏arXiv2026-03-17 更新2026-03-18 收录
下载链接:
https://huggingface.co/datasets/OpenSeeker/OpenSeeker-v1-Data
下载链接
链接失效反馈官方服务:
资源简介:
OpenSeeker-v1-Data是由上海交通大学团队构建的首个全开源搜索智能体训练数据集,包含1.17万条合成样本(含10.3k英文和1.4k中文)。该数据集通过逆向工程网络拓扑结构生成多跳推理任务,并采用实体混淆技术增强问题复杂性,同时利用回顾性摘要机制净化轨迹数据以提升质量。其核心创新在于事实锚定的可扩展QA合成与去噪轨迹合成技术,旨在解决前沿搜索智能体研究中高质量训练数据稀缺的问题,支持复杂网络搜索、多语言信息检索等应用场景。
提供机构:
上海交通大学
创建时间:
2026-03-17
原始信息汇总
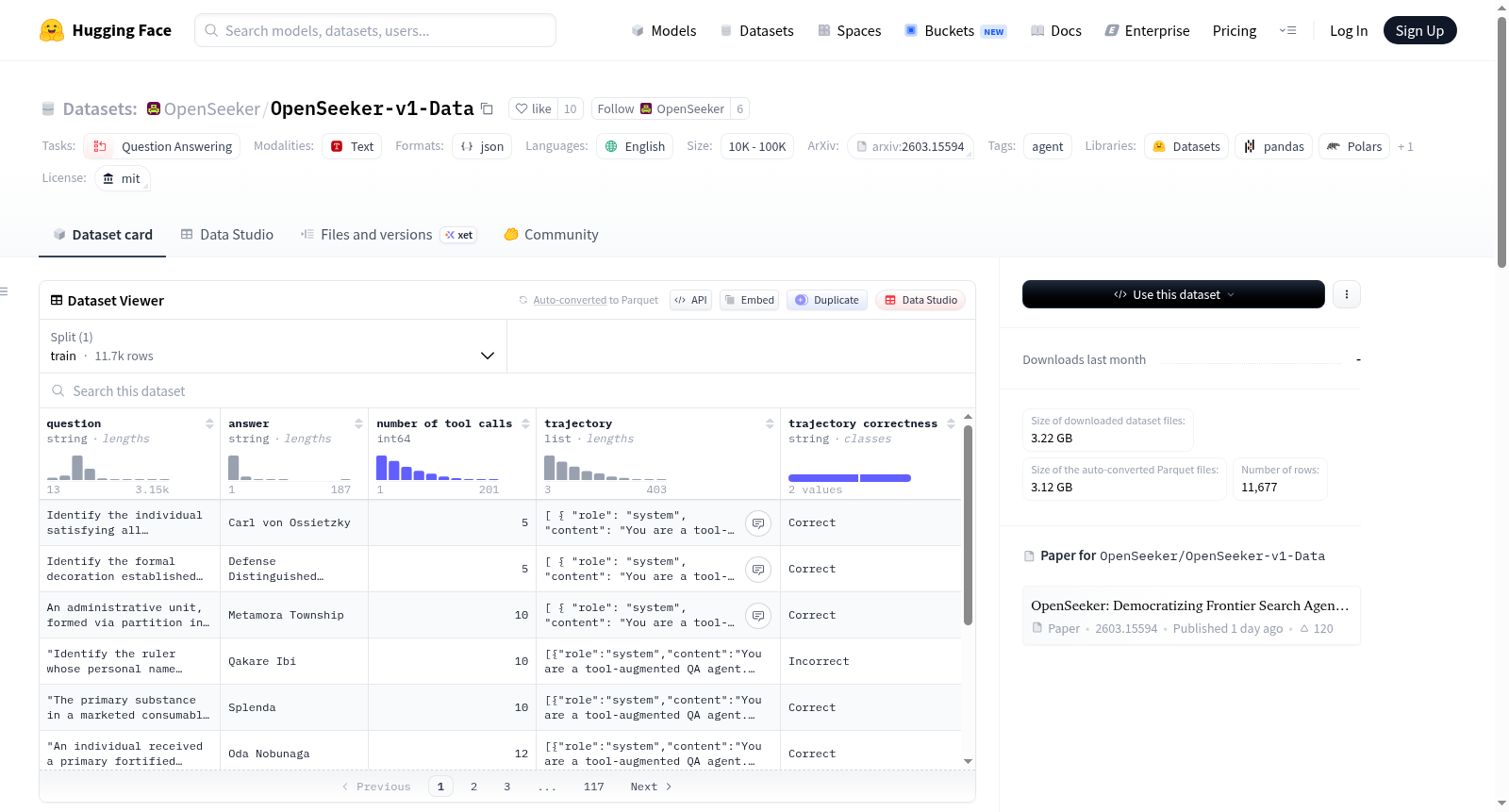
OpenSeeker/OpenSeeker-v1-Data 数据集概述
基本信息
- 数据集名称: OpenSeeker/OpenSeeker-v1-Data
- 语言: 英语 (en)
- 许可证: MIT
- 任务类别: 问答 (question-answering)
- 标签: 智能体 (agent)
- 数据规模: 10K<n<100K (数据量介于1万到10万之间)
数据配置
- 配置名称: default
- 数据文件:
- 分割: train
- 路径: openseeker_v1_data.jsonl
相关资源
- GitHub仓库: https://github.com/rui-ye/OpenSeeker
- 论文: https://arxiv.org/abs/2603.15594
搜集汇总
数据集介绍
构建方式
在大型语言模型智能体研究领域,高质量训练数据的匮乏长期制约着开源社区的创新。OpenSeeker-v1-Data的构建旨在打破这一壁垒,其核心采用了两种创新的合成方法。首先,基于事实的可扩展可控问答合成框架,通过从大规模网络语料库中随机选取种子页面,进行拓扑图扩展以识别相互关联的信息簇,并构建实体子图。随后应用实体混淆技术,将具体事实转化为需要多步推理的复杂问题,确保了数据的真实性、可扩展性和难度可控性。其次,去噪轨迹合成方法通过引入回顾性总结机制,在生成过程中对原始网络响应进行动态摘要,为教师模型提供清晰的历史上下文,从而合成高质量的动作序列,而在训练阶段则让模型基于原始噪声轨迹进行学习,以培养其内在的信息去噪与提取能力。
特点
该数据集最显著的特点在于其合成数据的高保真度与前沿性能导向。其问题设计深度植根于真实的网络拓扑结构,通过图扩展与实体混淆,生成了大量需要长视野、多跳推理的复杂查询,有效避免了模型通过浅层模式匹配即可解决的问题。数据集的难度经过精心校准,在工具调用次数和轨迹长度等指标上,甚至超越了现有的标准评测基准,确保了训练信号的有效性。尽管总体数据量相对精简,但其通过仅约1.17万个样本的监督微调,便能驱动模型在多个搜索基准测试中达到或超越工业界前沿模型的性能,这充分证明了其样本的高信息密度与卓越的监督质量。
使用方法
该数据集为训练高性能网络搜索智能体提供了完整的资源。研究者可直接将其用于模型的监督微调阶段,数据集包含了复杂的问答对以及与之对应的详细工具使用轨迹。在使用时,模型被训练基于原始的、包含噪声的网络观测历史,来预测由教师模型生成的优质推理步骤和工具调用动作,从而学习在真实嘈杂网络环境中进行稳健决策的能力。该数据集完全开源,支持社区在其基础上进行进一步的模型训练、数据质量分析、课程学习策略研究,或作为基准用于评估不同数据合成方法的有效性,旨在推动搜索智能体研究向更透明、协作的生态系统发展。
背景与挑战
背景概述
在信息爆炸的时代,从浩瀚互联网中精准、实时地获取可靠信息已成为现代决策的基石,深度搜索能力也因此成为前沿大语言模型智能体不可或缺的核心竞争力。长期以来,高性能搜索智能体的研发被工业巨头所主导,其关键壁垒在于高质量训练数据的稀缺与封闭。为打破这一数据垄断,上海交通大学的研究团队于2026年推出了OpenSeeker-v1-Data数据集。该数据集旨在通过完全开源的高质量训练数据,推动前沿搜索智能体研究的民主化,其核心研究问题聚焦于如何自动化合成具备事实基础、可扩展且难度可控的复杂多跳推理任务,以及如何生成高质量、去噪的搜索轨迹,以赋能开源社区训练出具备竞争性能的搜索智能体。
当前挑战
该数据集旨在解决的领域挑战,是训练能够执行深度、多跳网络搜索的智能体,其核心在于克服传统方法在生成复杂推理任务和高质量交互轨迹方面的不足。具体而言,领域挑战包括如何设计超越简单检索、强制模型进行多步推理的查询,以及如何确保智能体在充满噪声的网页内容中稳定提取关键信息。在数据集构建过程中,研究团队面临两大核心挑战:一是合成高难度问答对的挑战,需通过逆向工程网页图谱、进行拓扑扩展与实体模糊化,以生成事实基础牢固且推理复杂度可控的任务,避免模型通过关键词匹配走捷径;二是合成高质量轨迹的挑战,需设计去噪轨迹合成机制,利用回顾性总结来净化上下文,使教师模型能生成清晰的推理与精准的工具调用,同时确保训练时学生模型能基于原始噪声轨迹学习内在的信息提取与去噪能力。
常用场景
经典使用场景
在大型语言模型智能体研究领域,OpenSeeker-v1-Data数据集主要用于训练和评估具备深度网络搜索能力的智能体模型。该数据集通过其基于事实的、可扩展可控的问答合成技术,生成了大量需要多跳推理的复杂查询,模拟了真实网络环境中信息分散、需要多步导航才能获取答案的挑战性场景。研究者在开发搜索代理时,利用该数据集进行监督微调,能够有效训练模型掌握长序列工具调用、信息去噪与提取等核心能力,从而在BrowseComp、xbench-DeepSearch等标准基准测试中达到前沿性能。
解决学术问题
该数据集主要解决了搜索智能体研究领域长期存在的高质量训练数据稀缺问题。此前,高性能搜索代理的开发被少数工业巨头垄断,其训练数据不公开,形成了阻碍学术社区创新的“数据护城河”。OpenSeeker-v1-Data通过完全开源其合成的高保真数据,包括复杂的问答对和去噪后的轨迹序列,为学术界提供了可复现、可迭代的研究基础。它使得研究者能够深入探索如何通过数据合成而非单纯扩大模型规模或依赖强化学习来提升智能体的深度搜索能力,推动了该领域向更透明、协作的方向发展。
衍生相关工作
OpenSeeker-v1-Data的发布及其展现的高数据效能,激励并催生了一系列关注搜索智能体数据合成与训练效率的后续研究。其基于网络图拓扑扩展和实体混淆的合成范式,为后续工作如OpenResearcher等提供了重要的方法论参考。该数据集确立的“高质量小数据也能达到前沿性能”的范例,促使社区更加重视数据合成策略而非单纯追求数据规模,推动了如REDSearcher等工作在数据质量和训练协议上的进一步优化。同时,它作为首个完全开源且达到前沿性能的学术数据集,为后续完全透明的、可复现的搜索智能体研究树立了新的标杆。
以上内容由遇见数据集搜集并总结生成


