KETI-AIR/kor_quarel
收藏Hugging Face2023-12-06 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/KETI-AIR/kor_quarel
下载链接
链接失效反馈官方服务:
资源简介:
---
language:
- ko
license:
- cc-by-4.0
pretty_name: QUAREL
dataset_info:
features:
- name: data_index_by_user
dtype: int32
- name: id
dtype: string
- name: answer_index
dtype: int32
- name: logical_forms
sequence: string
- name: logical_form_pretty
dtype: string
- name: world_literals
struct:
- name: world1
sequence: string
- name: world2
sequence: string
- name: question
dtype: string
splits:
- name: train
num_bytes: 1191886
num_examples: 1941
- name: validation
num_bytes: 171905
num_examples: 278
- name: test
num_bytes: 342838
num_examples: 552
download_size: 615579
dataset_size: 1706629
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: validation
path: data/validation-*
- split: test
path: data/test-*
---
# Dataset Card for Quarel
## Licensing Information
The data is distributed under the [CC BY 4.0](https://creativecommons.org/licenses/by/4.0/) license.
## Source Data Citation INformation
```
@inproceedings{quarel_v1,
title={QuaRel: A Dataset and Models for Answering Questions about Qualitative Relationships},
author={Oyvind Tafjord, Peter Clark, Matt Gardner, Wen-tau Yih, Ashish Sabharwal},
year={2018},
journal={arXiv:1805.05377v1}
}
```
语言:
- 韩语
许可协议:
- CC BY 4.0
数据集名称:QUAREL
数据集信息:
特征:
- 名称:用户数据索引(data_index_by_user),数据类型:int32
- 名称:标识符(id),数据类型:字符串
- 名称:答案索引(answer_index),数据类型:int32
- 名称:逻辑形式序列(logical_forms),数据类型:字符串序列
- 名称:易读逻辑形式(logical_form_pretty),数据类型:字符串
- 名称:世界命题集合(world_literals),结构体包含:
- 世界1(world1):字符串序列
- 世界2(world2):字符串序列
- 名称:问题(question),数据类型:字符串
数据集划分:
- 名称:训练集(train),字节大小:1191886,样本数量:1941
- 名称:验证集(validation),字节大小:171905,样本数量:278
- 名称:测试集(test),字节大小:342838,样本数量:552
下载总大小:615579字节
数据集总大小:1706629字节
配置项:
- 配置名称:默认配置(default),数据文件路径:
- 训练集:data/train-*
- 验证集:data/validation-*
- 测试集:data/test-*
---
# QUAREL 数据集卡片
## 许可信息
本数据集采用[CC BY 4.0](https://creativecommons.org/licenses/by/4.0/)许可协议进行分发。
## 源数据引用信息
@inproceedings{quarel_v1,
title={QuaRel:用于定性关系问题回答的数据集与模型},
author={Oyvind Tafjord, Peter Clark, Matt Gardner, Wen-tau Yih, Ashish Sabharwal},
year={2018},
journal={arXiv:1805.05377v1}
}
提供机构:
KETI-AIR
原始信息汇总
数据集概述
基本信息
- 语言: 韩语 (ko)
- 许可证: CC BY 4.0
- 数据集名称: QUAREL
数据集结构
特征
- data_index_by_user: 数据类型为 int32
- id: 数据类型为 string
- answer_index: 数据类型为 int32
- logical_forms: 序列类型为 string
- logical_form_pretty: 数据类型为 string
- world_literals: 结构类型,包含两个序列类型的字段:
- world1: 序列类型为 string
- world2: 序列类型为 string
- question: 数据类型为 string
分割
- 训练集 (train):
- 字节数: 1191886
- 样本数: 1941
- 验证集 (validation):
- 字节数: 171905
- 样本数: 278
- 测试集 (test):
- 字节数: 342838
- 样本数: 552
大小
- 下载大小: 615579 字节
- 数据集大小: 1706629 字节
配置
- 默认配置 (default):
- 数据文件:
- 训练集: data/train-*
- 验证集: data/validation-*
- 测试集: data/test-*
- 数据文件:
搜集汇总
数据集介绍
构建方式
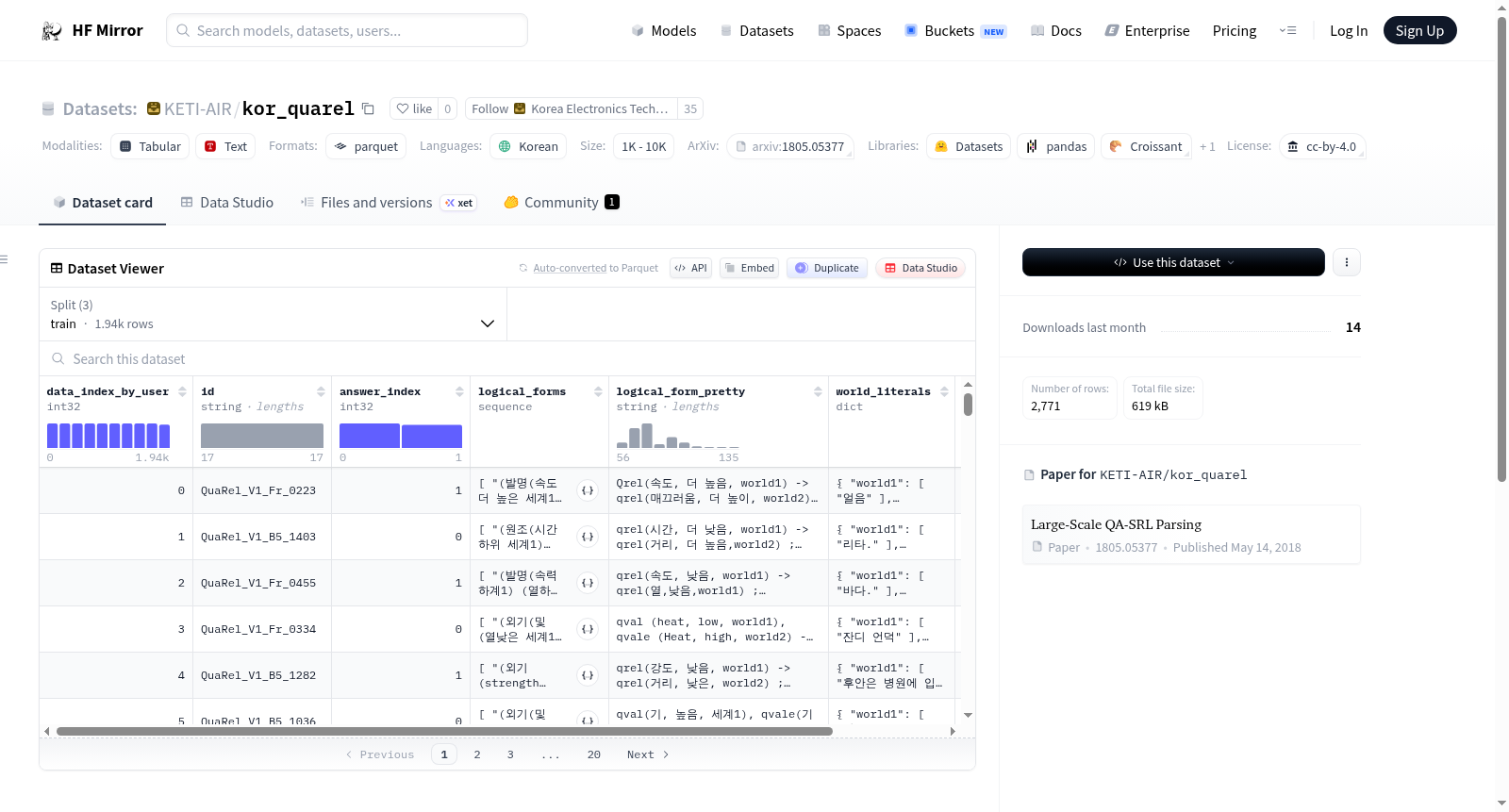
在自然语言处理领域,定性关系推理是评估模型逻辑理解能力的关键任务。KETI-AIR/kor_quarel数据集基于QuaRel框架构建,通过人工标注与结构化设计,将韩语自然语言问题转化为逻辑形式表达。该过程涉及对两个物理世界的描述,每个世界包含一组文字陈述,要求模型识别定性关系并选择正确世界。数据涵盖训练、验证和测试分割,确保任务多样性与评估可靠性,为韩语推理研究提供坚实基础。
特点
该数据集以韩语为核心,专注于定性关系推理,其独特之处在于每个问题均关联两个对比世界,每个世界由一系列文字定义物理属性。数据集提供逻辑形式序列与美观的逻辑形式表示,支持深度语义分析。条目包含用户索引、答案索引及详细问题文本,结构清晰且规模适中,涵盖近两千个训练实例,适用于模型训练与评估,促进跨语言推理能力的研究与发展。
使用方法
使用KETI-AIR/kor_quarel数据集时,研究者可加载训练、验证和测试分割,利用其逻辑形式与世界文字特征进行模型训练。该数据集适用于自然语言推理任务,通过分析问题与对应世界描述,模型需预测正确世界索引。其结构化格式便于集成到机器学习流程中,支持韩语定性关系理解模型的开发与基准测试,推动人工智能在复杂推理领域的应用。
背景与挑战
背景概述
在自然语言处理领域,定性关系推理作为复杂推理任务的重要分支,旨在探究实体间抽象属性的比较与关联。KETI-AIR/kor_quarel数据集由韩国电子通信研究院(KETI)人工智能研究部门于近年构建,其核心研究问题聚焦于韩语环境下的定性关系问答,即通过自然语言问题推断两个实体在特定属性上的相对状态。该数据集基于2018年发布的英文QuaRel数据集进行韩语适配与扩展,不仅推动了跨语言推理模型的发展,也为韩语自然语言理解研究提供了宝贵的基准资源,对提升智能系统在东亚语言环境下的逻辑推理能力具有显著影响力。
当前挑战
该数据集首要挑战在于解决定性关系推理这一领域问题,即模型需准确解析问题中隐含的物理或抽象属性(如速度、重量)及其比较关系,并基于给定的世界知识进行逻辑推断,这对模型的语义理解和常识推理能力提出了较高要求。在构建过程中,研究人员面临韩语语言特性带来的独特挑战,包括韩语语法结构中的助词与语序变化对逻辑形式标注的影响,以及如何将英文原数据集中的定性关系与世界知识精准地本地化为符合韩语文化背景的表达,同时确保数据在翻译与扩展过程中的逻辑一致性与多样性。
常用场景
经典使用场景
在自然语言处理领域,KETI-AIR/kor_quarel数据集为研究定性关系推理提供了关键资源。该数据集通过韩语构建的问答对,聚焦于物理世界中的定性比较问题,例如速度、温度或亮度等属性的相对关系。研究者利用其结构化逻辑形式与自然语言问题的对应关系,训练模型进行深层语义解析,从而评估模型在跨语言环境下的推理能力。这一场景不仅推动了多语言理解技术的发展,也为构建更智能的问答系统奠定了实验基础。
实际应用
在实际应用中,Kor-Quarel数据集支持智能教育系统和客服机器人的开发。例如,在韩语教育平台中,系统可以利用该数据训练模型,自动解答学生关于物理概念的定性比较问题,如“哪个物体更热?”。同时,在商业客服场景,它能增强机器人对用户比较性查询的理解,提供更准确的响应。这些应用提升了人机交互的自然性与效率,体现了数据集在推动现实世界AI解决方案落地中的价值。
衍生相关工作
基于Kor-Quarel数据集,衍生了一系列经典研究工作。例如,研究者扩展了原始英语Quarel框架,开发了跨语言迁移学习模型,以验证推理能力的语言无关性。同时,该数据激发了多模态推理任务的探索,如结合视觉信息进行定性判断。此外,许多工作利用其逻辑形式标注,设计了新型神经符号架构,增强了模型的解释性与泛化能力。这些衍生成果丰富了定性推理领域的研究图谱,持续推动着人工智能向更深层理解迈进。
以上内容由遇见数据集搜集并总结生成


