Henrychur/MMedBench
收藏Hugging Face2024-05-26 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/Henrychur/MMedBench
下载链接
链接失效反馈官方服务:
资源简介:
---
license: cc-by-nc-4.0
language:
- en
- zh
- ja
- fr
- ru
- es
tags:
- medical
task_categories:
- question-answering
---
# MMedBench
[💻Github Repo](https://github.com/MAGIC-AI4Med/MMedLM) [🖨️arXiv Paper](https://arxiv.org/abs/2402.13963)
The official benchmark for "Towards Building Multilingual Language Model for Medicine".
## Introduction
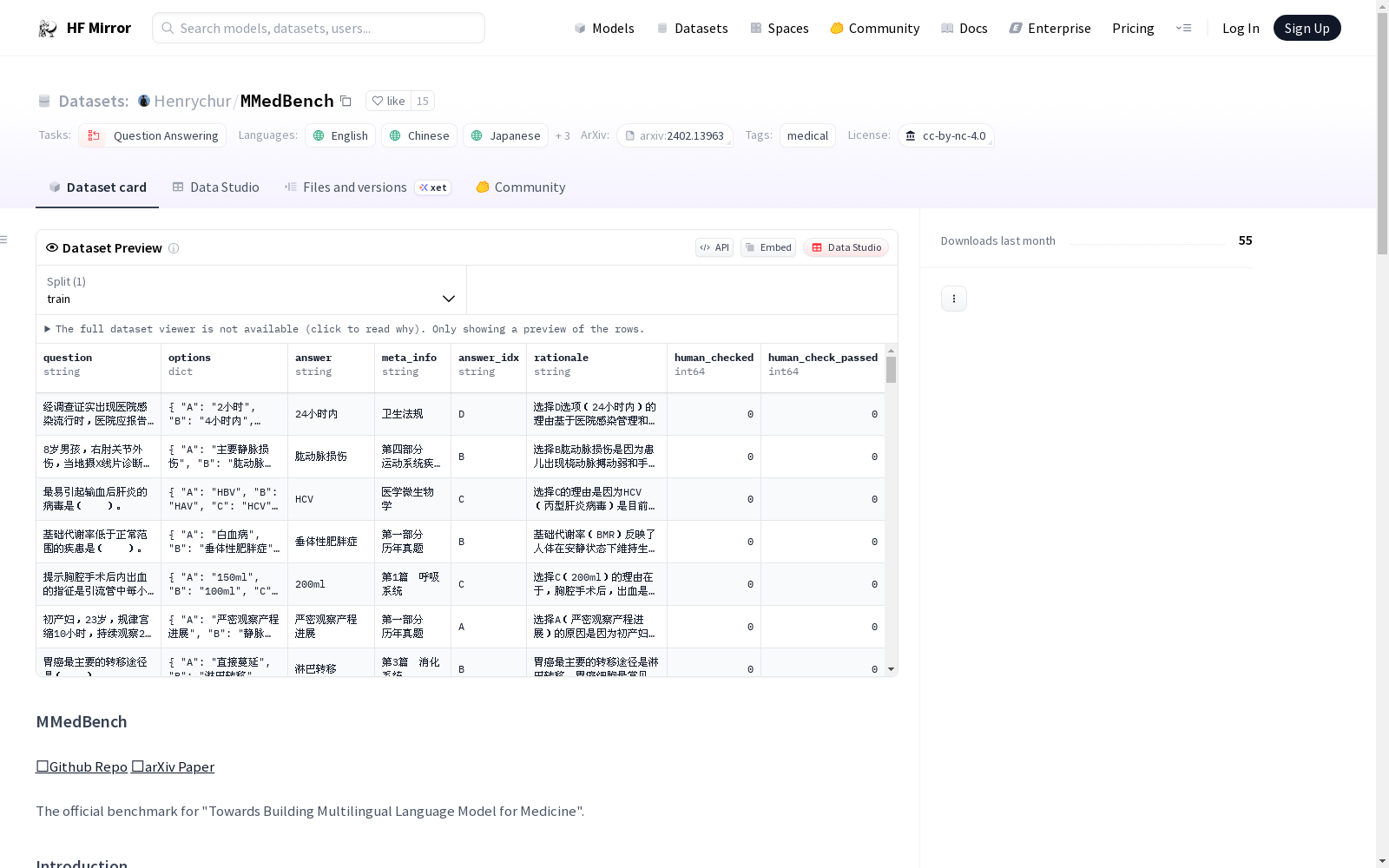
This repo contains MMedBench, a comprehensive multilingual medical benchmark comprising 45,048 QA pairs for training and 8,518 QA pairs for testing. Each sample includes a question, options, the correct answer, and a reference explanation for the selection of the correct answer.
To access the data, please download MMedBench.zip. Upon extracting the file, you will find two folders named Train and Test. Each folder contains six .jsonl files, each named after its respective language. Each line in these files represents a sample, with the following attributes for each sample:
|Key |Value Type |Description |
|------------------|-------------------|-----------------------------------------|
|question |String | A string of question |
|options |Dict | A dict where key is the index ‘A,B,C,D,E’ and value is the string of option| |
|answer_idx |String | A string of right answer idxs. Each idx is split by ','|
|rationale |String | A string of explanation for the selection of the correct answer |
|human_checked |Bool | Whether the rationale has been manually checked. |
|human_check_passed |Bool | Whether the rationale has passed manual check. |
Our [GitHub](https://github.com/MAGIC-AI4Med/MMedLM) provides the code for finetuning on the trainset of MMedBench. Check out for more details.
## News
[2024.2.21] Our pre-print paper is released ArXiv. Dive into our findings [here](https://arxiv.org/abs/2402.13963).
[2024.2.20] We release [MMedLM](https://huggingface.co/Henrychur/MMedLM) and [MMedLM 2](https://huggingface.co/Henrychur/MMedLM2). With an auto-regressive continues training on MMedC, these models achieves superior performance compared to all other open-source models, even rivaling GPT-4 on MMedBench.
[2023.2.20] We release [MMedC](https://huggingface.co/datasets/Henrychur/MMedC), a multilingual medical corpus containing 25.5B tokens.
[2023.2.20] We release [MMedBench](https://huggingface.co/datasets/Henrychur/MMedBench), a new multilingual medical multi-choice question-answering
benchmark with rationale. Check out the leaderboard [here](https://henrychur.github.io/MultilingualMedQA/).
## Evaluation on MMedBench
The further pretrained MMedLM 2 showcast it's great performance in medical domain across different language.
| Method | Size | Year | MMedC | MMedBench | English | Chinese | Japanese | French | Russian | Spanish | Avg. |
|------------------|------|---------|-----------|-----------|----------------|----------------|----------------|----------------|----------------|----------------|----------------|
| GPT-3.5 | - | 2022.12 | ✗ | ✗ | 56.88 | 52.29 | 34.63 | 32.48 | 66.36 | 66.06 | 51.47 |
| GPT-4 | - | 2023.3 | ✗ | ✗ | 78.00 | 75.07 | 72.91 | 56.59 | 83.62 | 85.67 | 74.27 |
| Gemini-1.0 pro | - | 2024.1 | ✗ | ✗ | 53.73 | 60.19 | 44.22 | 29.90 | 73.44 | 69.69 | 55.20 |
| BLOOMZ | 7B | 2023.5 | ✗ | trainset | 43.28 | 58.06 | 32.66 | 26.37 | 62.89 | 47.34 | 45.10 |
| InternLM | 7B | 2023.7 | ✗ | trainset | 44.07 | 64.62 | 37.19 | 24.92 | 58.20 | 44.97 | 45.67 |
| Llama\ 2 | 7B | 2023.7 | ✗ | trainset | 43.36 | 50.29 | 25.13 | 20.90 | 66.80 | 47.10 | 42.26 |
| MedAlpaca | 7B | 2023.3 | ✗ | trainset | 46.74 | 44.80 | 29.64 | 21.06 | 59.38 | 45.00 | 41.11 |
| ChatDoctor | 7B | 2023.4 | ✗ | trainset | 43.52 | 43.26 | 25.63 | 18.81 | 62.50 | 43.44 | 39.53 |
| PMC-LLaMA | 7B | 2023.4 | ✗ | trainset | 47.53 | 42.44 | 24.12 | 20.74 | 62.11 | 43.29 | 40.04 |
| Mistral | 7B | 2023.10 | ✗ | trainset | 61.74 | 71.10 | 44.72 | 48.71 | 74.22 | 63.86 | 60.73 |
| InternLM\ 2 | 7B | 2024.2 | ✗ | trainset | 57.27 | 77.55 | 47.74 | 41.00 | 68.36 | 59.59 | 58.59 |
| MMedLM~(Ours) | 7B | - | ✗ | trainset | 49.88 | 70.49 | 46.23 | 36.66 | 72.27 | 54.52 | 55.01 |
| MMedLM\ 2~(Ours) | 7B | - | ✗ | trainset | 61.74 | 80.01 | 61.81 | 52.09 | 80.47 | 67.65 | 67.30 |
- GPT and Gemini is evluated under zero-shot setting through API
- Open-source models first undergo training on the trainset of MMedBench before evaluate.
## Contact
If you have any question, please feel free to contact qiupengcheng@pjlab.org.cn.
## Citation
```
@misc{qiu2024building,
title={Towards Building Multilingual Language Model for Medicine},
author={Pengcheng Qiu and Chaoyi Wu and Xiaoman Zhang and Weixiong Lin and Haicheng Wang and Ya Zhang and Yanfeng Wang and Weidi Xie},
year={2024},
eprint={2402.13963},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
许可证:cc-by-nc-4.0
语言:
- 英语
- 汉语
- 日语
- 法语
- 俄语
- 西班牙语
标签:医疗
任务类别:问答
# MMedBench
[💻GitHub仓库](https://github.com/MAGIC-AI4Med/MMedLM) [🖨️arXiv论文](https://arxiv.org/abs/2402.13963)
本项目为《面向医疗领域的多语言大语言模型构建》一文的官方基准数据集。
## 简介
本仓库包含MMedBench,这是一套全面的多语言医疗基准数据集,包含45048条训练用问答(QA)样本与8518条测试用问答样本。每条样本均包含问题、选项、正确答案以及用于解释正确选项选择依据的参考解析。
如需获取数据集,请下载MMedBench.zip。解压后将得到两个名为Train(训练集)与Test(测试集)的文件夹,每个文件夹内包含六个以对应语言命名的.jsonl文件。文件中的每一行代表一条样本,每条样本包含以下属性:
| 属性键名 | 数据类型 | 描述说明 |
|------------------|-------------------|-----------------------------------------|
| question | 字符串(String) | 问题文本字符串 |
| options | 字典(Dict) | 键为选项索引'A,B,C,D,E'、值为选项文本字符串的字典|
| answer_idx | 字符串(String) | 正确答案索引的字符串,多个索引以英文逗号分隔|
| rationale | 字符串(String) | 用于解释正确选项选择逻辑的文本字符串 |
| human_checked | 布尔值(Bool) | 解析依据是否经过人工核查 |
| human_check_passed | 布尔值(Bool) | 解析依据是否通过人工核查 |
我们的[GitHub仓库](https://github.com/MAGIC-AI4Med/MMedLM)提供了基于MMedBench训练集进行微调的代码,更多细节可前往查看。
## 动态更新
[2024.2.21] 我们的预印本论文已在ArXiv平台发布。可前往[此处](https://arxiv.org/abs/2402.13963)查阅我们的研究成果。
[2024.2.20] 我们发布了[MMedLM](https://huggingface.co/Henrychur/MMedLM)与[MMedLM 2](https://huggingface.co/Henrychur/MMedLM2)。通过在MMedC上进行自回归持续预训练,这些模型的性能优于所有其他开源模型,在MMedBench上的表现甚至可与GPT-4媲美。
[2023.2.20] 我们发布了[MMedC](https://huggingface.co/datasets/Henrychur/MMedC),这是一个包含25.5亿Token的多语言医疗语料库。
[2023.2.20] 我们发布了[MMedBench](https://huggingface.co/datasets/Henrychur/MMedBench),这是一款全新的带解析依据的多语言医疗多选问答基准数据集。可前往[此处](https://henrychur.github.io/MultilingualMedQA/)查看排行榜。
## MMedBench 评估结果
经过进一步预训练的MMedLM 2展现出了在多语言医疗领域的优异性能。
| 模型方法 | 参数规模 | 发布年份 | MMedC | MMedBench | 英语 | 汉语 | 日语 | 法语 | 俄语 | 西班牙语 | 平均得分 |
|------------------|------|---------|-----------|-----------|----------------|----------------|----------------|----------------|----------------|----------------|----------------|
| GPT-3.5 | - | 2022.12 | × | × | 56.88 | 52.29 | 34.63 | 32.48 | 66.36 | 66.06 | 51.47 |
| GPT-4 | - | 2023.3 | × | × | 78.00 | 75.07 | 72.91 | 56.59 | 83.62 | 85.67 | 74.27 |
| Gemini-1.0 pro | - | 2024.1 | × | × | 53.73 | 60.19 | 44.22 | 29.90 | 73.44 | 69.69 | 55.20 |
| BLOOMZ | 7B | 2023.5 | × | 训练集 | 43.28 | 58.06 | 32.66 | 26.37 | 62.89 | 47.34 | 45.10 |
| InternLM | 7B | 2023.7 | × | 训练集 | 44.07 | 64.62 | 37.19 | 24.92 | 58.20 | 44.97 | 45.67 |
| Llama 2 | 7B | 2023.7 | × | 训练集 | 43.36 | 50.29 | 25.13 | 20.90 | 66.80 | 47.10 | 42.26 |
| MedAlpaca | 7B | 2023.3 | × | 训练集 | 46.74 | 44.80 | 29.64 | 21.06 | 59.38 | 45.00 | 41.11 |
| ChatDoctor | 7B | 2023.4 | × | 训练集 | 43.52 | 43.26 | 25.63 | 18.81 | 62.50 | 43.44 | 39.53 |
| PMC-LLaMA | 7B | 2023.4 | × | 训练集 | 47.53 | 42.44 | 24.12 | 20.74 | 62.11 | 43.29 | 40.04 |
| Mistral | 7B | 2023.10 | × | 训练集 | 61.74 | 71.10 | 44.72 | 48.71 | 74.22 | 63.86 | 60.73 |
| InternLM 2 | 7B | 2024.2 | × | 训练集 | 57.27 | 77.55 | 47.74 | 41.00 | 68.36 | 59.59 | 58.59 |
| MMedLM(本文团队) | 7B | - | × | 训练集 | 49.88 | 70.49 | 46.23 | 36.66 | 72.27 | 54.52 | 55.01 |
| MMedLM 2(本文团队) | 7B | - | × | 训练集 | 61.74 | 80.01 | 61.81 | 52.09 | 80.47 | 67.65 | 67.30 |
- GPT与Gemini系列模型均通过API以零样本(Zero-shot)设置进行评估
- 开源模型均先在MMedBench训练集上完成微调,再进行评估。
## 联系方式
如有任何疑问,欢迎联系邮箱qiupengcheng@pjlab.org.cn。
## 引用格式
@misc{qiu2024building,
title={Towards Building Multilingual Language Model for Medicine},
author={Pengcheng Qiu and Chaoyi Wu and Xiaoman Zhang and Weixiong Lin and Haicheng Wang and Ya Zhang and Yanfeng Wang and Weidi Xie},
year={2024},
eprint={2402.13963},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
提供机构:
Henrychur
原始信息汇总
MMedBench 数据集概述
数据集介绍
MMedBench 是一个综合性的多语种医学基准测试数据集,包含 45,048 个 QA 对用于训练和 8,518 个 QA 对用于测试。每个样本包括问题、选项、正确答案以及选择正确答案的参考解释。
数据结构
数据集分为训练集和测试集,每个集包含六个 .jsonl 文件,每个文件对应一种语言。每个样本的属性如下:
| 键 | 值类型 | 描述 |
|---|---|---|
| question | 字符串 | 问题文本 |
| options | 字典 | 选项字典,键为索引 A,B,C,D,E,值为选项文本 |
| answer_idx | 字符串 | 正确答案的索引,多个索引用逗号分隔 |
| rationale | 字符串 | 选择正确答案的解释文本 |
| human_checked | 布尔值 | 解释是否经过人工检查 |
| human_check_passed | 布尔值 | 解释是否通过人工检查 |
数据下载
要访问数据,请下载 MMedBench.zip 文件,解压后会看到名为 Train 和 Test 的两个文件夹,每个文件夹包含六个 .jsonl 文件。
数据集评估
MMedBench 的评估结果显示,MMedLM 2 在医学领域跨不同语言表现出色。
| 方法 | 大小 | 年份 | MMedC | MMedBench | 英语 | 中文 | 日语 | 法语 | 俄语 | 西班牙语 | 平均 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| GPT-3.5 | - | 2022.12 | ✗ | ✗ | 56.88 | 52.29 | 34.63 | 32.48 | 66.36 | 66.06 | 51.47 |
| GPT-4 | - | 2023.3 | ✗ | ✗ | 78.00 | 75.07 | 72.91 | 56.59 | 83.62 | 85.67 | 74.27 |
| Gemini-1.0 pro | - | 2024.1 | ✗ | ✗ | 53.73 | 60.19 | 44.22 | 29.90 | 73.44 | 69.69 | 55.20 |
| BLOOMZ | 7B | 2023.5 | ✗ | trainset | 43.28 | 58.06 | 32.66 | 26.37 | 62.89 | 47.34 | 45.10 |
| InternLM | 7B | 2023.7 | ✗ | trainset | 44.07 | 64.62 | 37.19 | 24.92 | 58.20 | 44.97 | 45.67 |
| Llama 2 | 7B | 2023.7 | ✗ | trainset | 43.36 | 50.29 | 25.13 | 20.90 | 66.80 | 47.10 | 42.26 |
| MedAlpaca | 7B | 2023.3 | ✗ | trainset | 46.74 | 44.80 | 29.64 | 21.06 | 59.38 | 45.00 | 41.11 |
| ChatDoctor | 7B | 2023.4 | ✗ | trainset | 43.52 | 43.26 | 25.63 | 18.81 | 62.50 | 43.44 | 39.53 |
| PMC-LLaMA | 7B | 2023.4 | ✗ | trainset | 47.53 | 42.44 | 24.12 | 20.74 | 62.11 | 43.29 | 40.04 |
| Mistral | 7B | 2023.10 | ✗ | trainset | 61.74 | 71.10 | 44.72 | 48.71 | 74.22 | 63.86 | 60.73 |
| InternLM 2 | 7B | 2024.2 | ✗ | trainset | 57.27 | 77.55 | 47.74 | 41.00 | 68.36 | 59.59 | 58.59 |
| MMedLM~(Ours) | 7B | - | ✗ | trainset | 49.88 | 70.49 | 46.23 | 36.66 | 72.27 | 54.52 | 55.01 |
| MMedLM 2~(Ours) | 7B | - | ✗ | trainset | 61.74 | 80.01 | 61.81 | 52.09 | 80.47 | 67.65 | 67.30 |
- GPT 和 Gemini 在零样本设置下通过 API 进行评估。
- 开源模型首先在 MMedBench 的训练集上进行训练,然后进行评估。
搜集汇总
数据集介绍
构建方式
MMedBench数据集的构建,旨在针对医学领域打造一款全面的多元语言问答基准。该数据集通过整合45,048个训练用的问答对以及8,518个测试用的问答对,每一对问答均包含问题、选项、正确答案以及选择正确答案的参考解释,从而为模型训练与评估提供了丰富而细致的语言资源。
特点
MMedBench的特点在于其多元语言的覆盖范围,包含英语、中文、日语、法语、俄语及西班牙语等。此外,数据集提供了详细的参考解释以及人工审核过的答案,这不仅增强了数据集的实用价值,也为模型的性能评估提供了可靠的标准。
使用方法
使用MMedBench数据集时,用户需下载MMedBench.zip文件,解压后可得到训练集和测试集,每个集合包含对应语言的.jsonl文件。文件中的每一行代表一个样本,包含问题、选项、答案索引以及答案选择的解释。用户可通过GitHub提供的代码对训练集进行微调,进而对模型在医学领域的多语言问答能力进行评估。
背景与挑战
背景概述
MMedBench,作为医学领域构建多语言语言模型的官方基准测试,由MAGIC-AI4Med团队于2023年推出。该数据集包含45,048个用于训练的多语言问答对以及8,518个用于测试的问答对,覆盖了英语、中文、日语、法语、俄语和西班牙语等多种语言。数据集的构建旨在推动医学领域多语言语言模型的研究与开发,其研究成果已在arXiv上发布。MMedBench的推出对医学自然语言处理领域产生了重要影响,为相关研究提供了宝贵的数据资源。
当前挑战
在构建MMedBench的过程中,研究团队面临了多语言数据收集和标注的挑战,确保了数据的质量和多样性。此外,MMedBench在解决医学领域问题时,也面临着模型跨语言适应性和准确性的挑战。当前,评估MMedBench上的模型性能时,不同模型在处理不同语言时表现出较大的性能差异,这提示了在医学多语言模型研究中,仍需进一步探索和优化模型的泛化能力和语言适应性。
常用场景
经典使用场景
在医学问答系统的构建与评估领域,MMedBench作为一个全面的多元语言医学问答基准,提供了45,048个训练问答对和8,518个测试问答对,每个样本包括问题、选项、正确答案以及选择正确答案的参考解释。该数据集的经典使用场景在于,研究者可以利用这些问答对来训练和评估多语言医学语言模型,以实现跨语言医学知识的准确问答。
实际应用
在实际应用中,MMedBench可被用于开发和优化医疗健康领域的智能助手,这些助手能够协助医生和患者进行跨语言的医学咨询和健康教育。此外,该数据集还可助力医学知识库的构建,为医疗决策提供支持,提升医疗服务的质量和效率。
衍生相关工作
基于MMedBench,研究者们已经衍生出了一系列相关工作,如MMedLM和MMedLM 2等模型,这些模型在MMedBench上的表现优于其他开源模型,甚至在某些语言上能与GPT-4相媲美。这些成果不仅推动了医学语言模型的进步,也为医学自然语言处理领域带来了新的研究视角和技术突破。
以上内容由遇见数据集搜集并总结生成


