yashm/bioinformatics-qa-dataset
收藏Hugging Face2026-04-25 更新2026-04-26 收录
下载链接:
https://hf-mirror.com/datasets/yashm/bioinformatics-qa-dataset
下载链接
链接失效反馈官方服务:
资源简介:
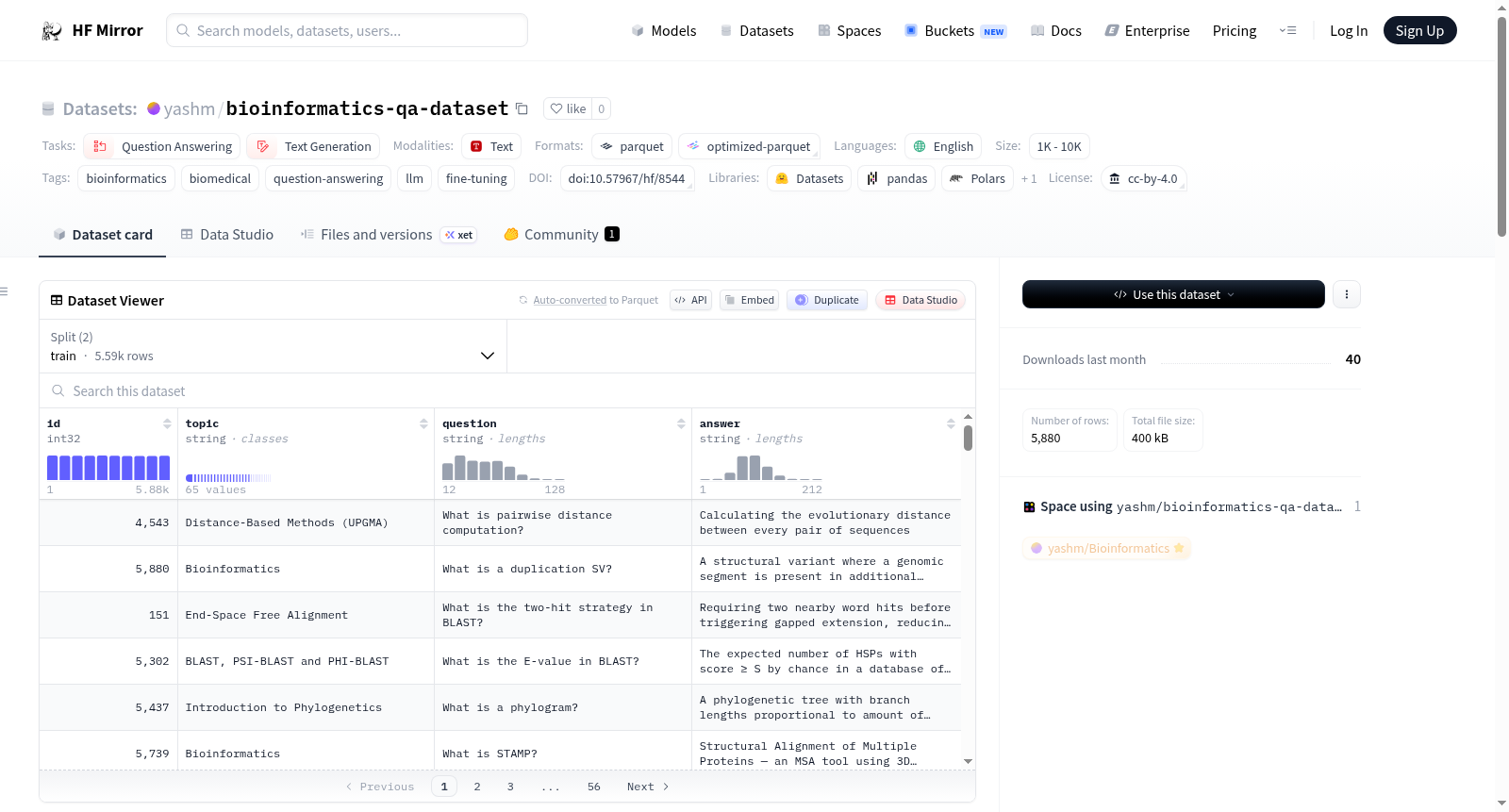
一个精心整理的生物信息学和计算生物学问题回答数据集,用于模型训练。数据集包含5880个示例,涵盖65个独特主题,每行数据包含id、主题、问题和回答四个字段。该数据集主要用于生物医学和生物信息学领域的大型语言模型的指令调适和领域适应,以及生命科学术语的问答基准测试和提示-响应训练流程。数据经过清洗处理,包括去除空白字符、空行和重复数据,并重新索引id。
A curated question-answer dataset for bioinformatics and computational biology model training. The dataset contains 5880 examples covering 65 unique topics, with each row containing id, topic, question, and answer fields. It is primarily intended for instruction tuning and domain adaptation of large language models in biomedical and bioinformatics fields, as well as QA benchmarking in life-science terminology and prompt-response training pipelines. The data has been cleaned by trimming whitespace, removing empty question/answer rows and exact duplicates, and reindexing ids.
提供机构:
yashm
搜集汇总
数据集介绍
构建方式
生物信息学与计算生物学作为联结生命科学与数据科学的交叉领域,其研究范式的革新高度依赖于高质量领域数据的支撑。该数据集通过系统化整理涵盖65个主题的5880个问答对,构建起面向生物信息学领域的专业知识库。数据清洗流程严格规范,包括去除空值行、消除基于主题、问题与答案三重维度的精确重复项、修剪空白字符以及重新索引ID序列,最终以CSV格式转化为HuggingFace Dataset标准格式。
特点
该数据集最显著的特征在于其细粒度的主题覆盖与结构化设计,每个样本均包含唯一的数值标识符、主题类别标签、自然语言问题及其专业参考答案。作为面向大语言模型指令微调与领域适配的稀缺资源,它既可用于生命科学术语体系的问答基准测试,也能支撑提示-响应对训练流水线的构建。数据集仅提供训练集与测试集划分,整体规模紧凑但高度专注。
使用方法
该数据集专为学习和研究目的设计,主要用于生物信息学方向大语言模型的指令微调与领域适应,以及生命科学术语的问答基准评估与提示-响应训练流程。需要特别注意的是,数据集中的回答可能存在简化、遗漏或信息过时的情况,经其微调的模型输出必须经过独立验证,严禁用于临床诊断、治疗决策或其他高风险场景。引用时需标注数据集的DOI与版本号。
背景与挑战
背景概述
随着高通量测序、蛋白质组学和结构生物学等技术的飞速发展,生物信息学领域积累了海量异构数据,亟需高效的计算模型来解析其内在规律。在此背景下,Yash Munnalal Gupta于2026年发布了Bioinformatics QA Dataset,该数据集由Hugging Face平台托管,包含5880条精心整理的问答对,覆盖65个独特主题,旨在为大型语言模型(LLM)提供生物信息学与计算生物学领域的指令微调与领域适配资源。作为首个专攻生物信息学的问答基准,该数据集填补了通用生物医学语料库在分子生物学算法、基因组注释等专业子领域上的精细标注空白,为评估和提升LLM在生命科学前沿问题上的推理能力提供了关键支撑,对推动人工智能驱动的生物医学发现具有重要影响力。
当前挑战
该数据集面临的核心领域挑战在于生物信息学问题的高度专业性和动态演化性,例如基因功能预测、蛋白质结构解析等议题常随技术进步而更新,导致静态问答对可能包含简化或过时信息,难以完全反映前沿知识。在构建过程中,数据清洗虽已去除空白行与重复项,但原始来源的多样性与术语歧义性仍构成挑战——不同文献对同一生物学概念可能使用同义表达,而问题与答案之间的逻辑一致性需精细校验。此外,多源异构数据的整合导致主题覆盖不均衡,某些冷门专题的样本量稀疏,易使模型在微调后产生偏见,且模型输出必须经独立验证方可应用于高风险场景,如临床诊断或药物设计,这进一步提高了对数据集质量与鲁棒性的要求。
常用场景
经典使用场景
在生物信息学与计算生物学这一交叉学科领域,精准理解专业术语与复杂生命科学概念是构建智能问答系统的核心挑战。Bioinformatics QA Dataset凭借其精心策划的5,880条问答对,覆盖65个独特主题,成为领域内模型指令微调与域适配的经典基准。该数据集最常用于训练和评估面向生物医学的大语言模型,使其能够准确回答关于基因组学、蛋白质结构、系统发育等专业问题,从而弥合通用语言模型与专业生物信息学知识之间的鸿沟。
解决学术问题
该数据集旨在解决生物信息学领域中专业问答语料匮乏的长期困境。传统上,研究人员难以获得结构化、高质量且覆盖广泛主题的问答对来评估模型对生命科学术语的理解能力。通过提供经过清洗与去重的训练和测试划分,该数据集为学术界提供了一个标准化的指令微调平台,助力模型在理解复杂生物过程、解析实验结果及推理分子机制等关键任务上取得突破,显著推动了领域内大语言模型的学术评估体系发展。
衍生相关工作
基于该数据集的质量与结构化特性,它已衍生出多项具有影响力的学术工作。研究者们将其作为基准数据集,开发了面向生物信息学的专用大语言模型(如BioBERT、PubMedBERT等)的微调变体,并在此基础上构建了更复杂的检索增强生成(RAG)框架。此外,该数据集启发了多个跨领域的问答数据集构建工作,例如将其范式迁移至化学信息学与药物发现领域,催生了用于分子属性预测与药物-靶标相互作用识别的专业知识库,推动了生命科学领域知识问答生态的持续扩展。
以上内容由遇见数据集搜集并总结生成


