Action with RAre Scene (ARAS)
收藏arXiv2022-09-20 更新2024-06-21 收录
下载链接:
https://github.com/kennymckormick/ARAS-Dataset
下载链接
链接失效反馈官方服务:
资源简介:
ARAS数据集是由香港中文大学的研究团队创建,专门用于评估动作识别模型在罕见场景下的表现。该数据集包含1038个视频片段,每个片段都与Kinetics-400中的特定动作类别相关联,但场景设置为罕见或不常见。创建过程中,研究团队通过在YouTube上使用特定动作和罕见场景的组合作为查询,筛选并手动检查视频以确保其符合要求。ARAS数据集的应用领域主要集中在动作识别技术中,特别是在模型需要处理多样化和非典型场景时的性能评估。
The ARAS dataset was developed by a research team from The Chinese University of Hong Kong, specifically designed to evaluate the performance of action recognition models in rare scenarios. This dataset comprises 1038 video clips, each linked to a specific action category within Kinetics-400, but with rare or atypical scene setups. During its creation, the research team utilized combinations of target actions and rare scenarios as search queries on YouTube, before screening and manually verifying the videos to confirm their compliance with the dataset requirements. The ARAS dataset is primarily applied in the field of action recognition, especially for assessing model performance when handling diverse and non-standard scenarios.
提供机构:
香港中文大学
创建时间:
2022-09-20
搜集汇总
数据集介绍
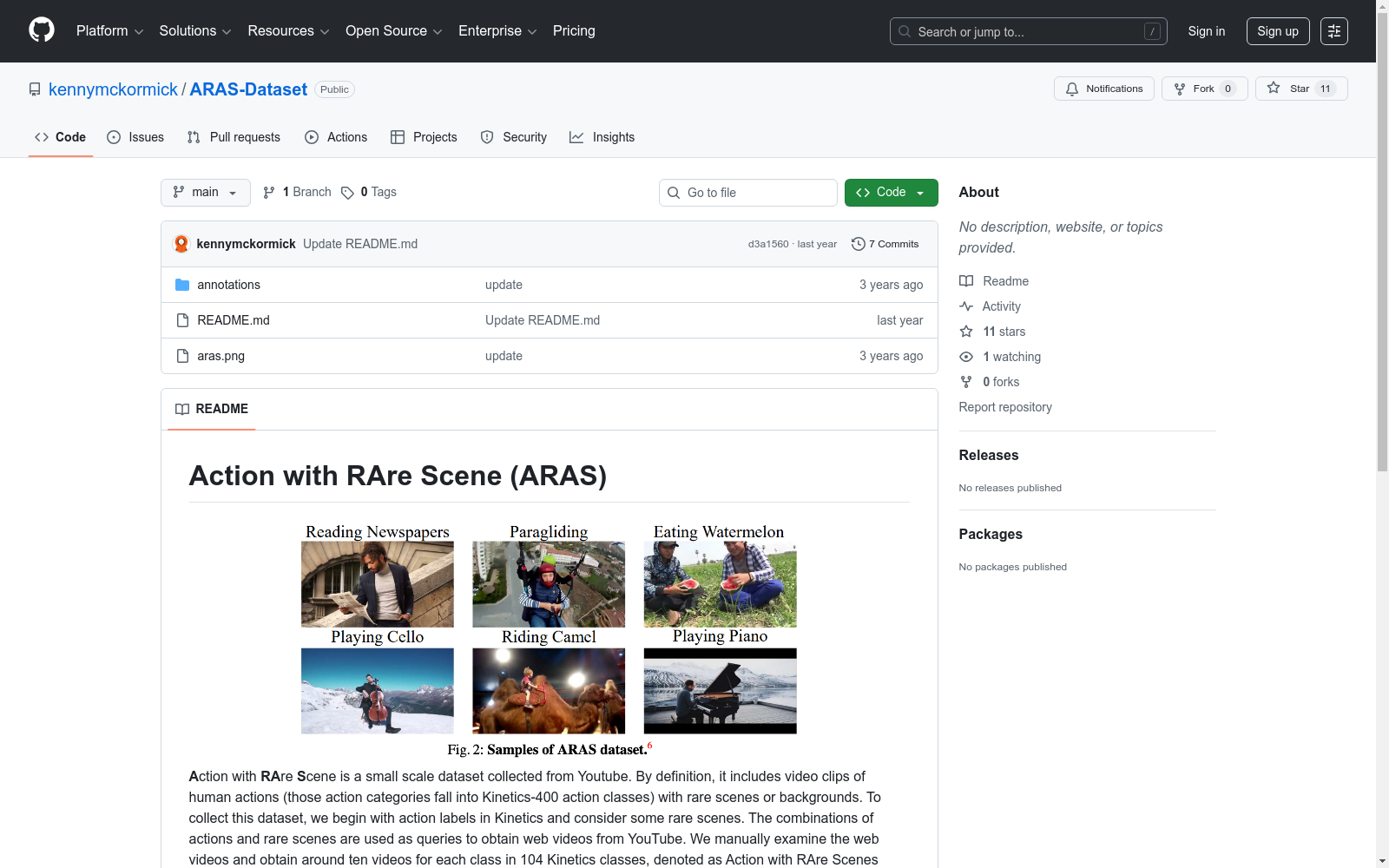
构建方式
在动作识别领域,数据集的场景偏差问题长期制约着模型的泛化能力。为系统评估算法在罕见场景下的表现,ARAS数据集通过精心设计的流程构建而成。研究者首先从Kinetics-400数据集中筛选出104个动作类别,针对每个类别,人工分析其训练视频中的常见场景分布,并逆向定义与之形成鲜明对比的罕见场景。随后,以“动作-罕见场景”组合作为查询关键词,从YouTube平台系统性地爬取原始视频素材。经过严格的人工审核与去重处理,确保数据不与现有训练集重叠,最终为每个类别保留约10段高质量视频片段,形成包含1038个剪辑的平衡测试集。
特点
ARAS数据集的核心特征在于其刻意构建的分布外测试属性。该数据集通过动作与场景的非常规组合,模拟了现实部署中模型可能遇到的极端分布偏移情况。其视频内容呈现出显著的长尾场景分布特性,即每个动作类别所对应的背景环境均偏离常规训练数据中的高频模式。这种设计使得数据集能够有效暴露模型对场景线索的过度依赖,为评估去偏算法的鲁棒性提供了高区分度的测试基准。数据集的规模虽精炼,但类别平衡且标注质量严格受控,确保了评估结果的统计可靠性。
使用方法
ARAS数据集主要作为评估基准,用于量化动作识别模型在面临场景分布偏移时的泛化性能下降程度。在标准使用流程中,研究者首先在常规数据集(如Kinetics)上训练模型,随后直接在ARAS的测试集上进行零样本评估,通过准确率对比衡量模型对场景偏差的敏感度。该数据集亦可与K200db等重分布数据集结合,构成多层次的评估体系,用于验证去偏算法(如SMAD、OmniDebias)的有效性。其评估结果能够直观反映模型表征对非动作因素的依赖程度,为改进算法设计提供关键洞察。
背景与挑战
背景概述
在计算机视觉领域,动作识别旨在理解视频中的人类行为,然而现有的大规模视频数据集普遍存在表征偏差问题,即模型过度依赖与动作无关的场景或物体等非动作特征进行预测。为系统性地研究并缓解此问题,香港中文大学、上海人工智能实验室等机构的研究团队于2022年共同创建了ARAS数据集。该数据集聚焦于动作与罕见场景的组合,核心研究目标在于评估模型在分布外场景下的泛化能力,旨在推动动作识别模型学习更具泛化性的表征,减少对特定背景信息的依赖,从而提升其在真实复杂环境中的鲁棒性。
当前挑战
ARAS数据集所应对的核心领域挑战,是动作识别模型因训练数据偏差而产生的脆弱泛化能力,即在面对训练集中罕见或未出现过的场景时,模型性能会显著下降。这一挑战深刻揭示了现有模型对非动作语义线索的过度依赖问题。在构建过程中,研究团队面临两大具体挑战:其一,如何从海量网络视频中精准筛选出符合‘常见动作-罕见场景’这一矛盾组合的有效样本,这需要对动作与场景的联合分布有深刻理解并进行大量人工核查;其二,构建一个具有足够规模且类别平衡的评估集本身存在困难,因为许多动作类别天然与特定场景强相关,或难以在现实世界中找到与之匹配的罕见场景实例,这限制了数据集的全面覆盖范围。
常用场景
经典使用场景
在计算机视觉领域,ARAS数据集专为评估动作识别模型在罕见场景下的泛化能力而设计。其经典使用场景在于模拟真实世界中的分布外测试环境,通过精心构建动作与罕见场景的组合,为研究者提供了一个衡量模型抗场景偏见能力的基准平台。该数据集通常用于训练后的模型评估阶段,通过对比模型在常规数据集与ARAS上的性能差异,量化模型对场景变化的敏感程度。
衍生相关工作
围绕ARAS数据集及其提出的偏见评估范式,衍生出一系列专注于去偏见算法改进的研究工作。其直接催生了原文提出的SMAD框架与OmniDebias方法,为多角度对抗训练和网络数据利用提供了新思路。此外,该数据集建立的评估协议(如基于属性的数据重划分、分布外测试)也被后续研究采纳,成为衡量去偏见算法有效性的新标准,推动了公平性学习、领域泛化等技术在视频理解领域的深入探索。
数据集最近研究
最新研究方向
在计算机视觉领域,动作识别模型常因训练数据集的表示偏差而泛化能力受限,尤其在罕见场景下性能显著下降。ARAS数据集作为专门评估模型抗场景偏差能力的新兴基准,其最新研究聚焦于开发先进的去偏算法与数据增强策略。前沿工作如SMAD框架通过多维度对抗训练与空间感知动作重加权机制,有效解耦动作特征与非动作语义的关联;同时,OmniDebias方法利用网络数据的多样性进行选择性联合训练,显著提升了模型在分布外场景下的鲁棒性。这些进展不仅推动了动作识别模型公平性与泛化性的理论探索,也为自动驾驶、智能监控等实际应用中应对复杂环境变化提供了关键技术支撑。
相关研究论文
- 1Mitigating Representation Bias in Action Recognition: Algorithms and Benchmarks香港中文大学 · 2022年
以上内容由遇见数据集搜集并总结生成


