neuralbioinfo/phage-test-10k
收藏Hugging Face2025-01-09 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/neuralbioinfo/phage-test-10k
下载链接
链接失效反馈官方服务:
资源简介:
这是一个用于噬菌体预测的样本数据集,包含10,000个随机样本和噬菌体基因组段。数据集由来自RefSeq数据库和TemPhD方法的噬菌体序列组成,经过CD-HIT算法去重,共有40,512个独特的噬菌体序列,平均长度约为43,356个碱基对,总共有35亿个碱基对。这些序列覆盖了660个细菌属。数据集分为三个子集,基于段长度分别为512、1024和2048个碱基对。
This is a sample dataset for phage prediction, containing 10,000 random samples and segments of phage genomes. The dataset is compiled from phage sequences and annotations from the RefSeq database and the TemPhD method, redundancy is addressed using the CD-HIT algorithm, resulting in 40,512 unique phage sequences with an average length of approximately 43,356 base pairs, totaling 3.5 billion base pairs. These sequences target a wide spectrum of 660 bacterial genera. The dataset is divided into three subsets based on segment lengths: 512, 1024, and 2048 base pairs.
提供机构:
neuralbioinfo
原始信息汇总
噬菌体预测数据集概述
数据集描述
该数据集用于训练和评估预测模型,汇集了来自多个来源的全面噬菌体序列数据库。截至2023年7月9日,我们从RefSeq数据库中获取了病毒序列和注释,并通过筛选标记为“噬菌体”的条目,获得了6,075个连续片段。此外,我们还加入了TemPhD数据库,增加了192,326个噬菌体连续片段,这些片段来自148,229个组装体。
为了解决RefSeq和TemPhD数据库中的序列冗余问题,我们使用了CD-HIT算法(使用CD-HIT-EST,默认单词大小为5)。经过多次实验,我们选择了0.99的聚类阈值,最终得到了40,512个独特的噬菌体序列,平均长度约为43,356个碱基对,总计35亿个碱基对。这些序列针对660个细菌属。在序列筛选后,噬菌体序列被映射到其对应的细菌宿主。
这是一个包含10,000个片段的样本数据集,代表了噬菌体基因组的随机样本和片段。
特征
- 噬菌体-宿主关联:数据集代表了噬菌体及其细菌宿主。
- 平衡表示:数据集结构旨在通过均匀地表示不同属中的噬菌体及其宿主,并包含反向互补序列来减少偏差。
- 数据集组成:最终集合包括不同长度的序列,以满足不同的研究需求,并在训练、验证和测试集之间保持平衡分布。
- 采样策略:为了确保一个全面且易于管理的数据集,我们采用了欠采样和过采样技术,创建了多种序列长度,并确保在物种水平上训练和测试集之间没有重叠。
数据集结构
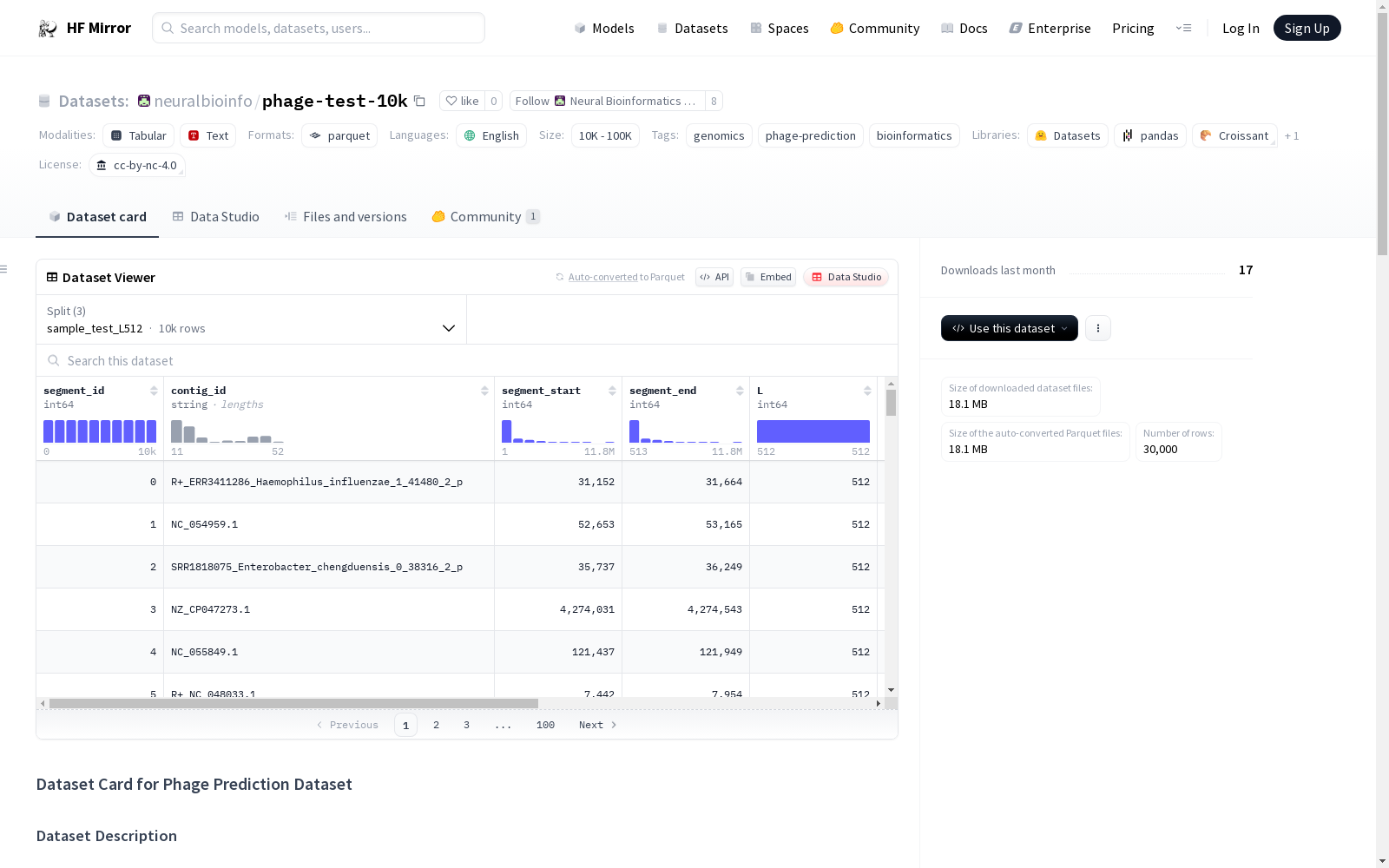
数据集根据片段长度分为三个子集:512、1024和2048个碱基对。这些子集分别命名为sample_test_L512、sample_test_L1024和sample_test_L2048。
数据字段
segment_id:每个基因组片段的唯一标识符。contig_id:片段来源的连续片段的标识符。segment_start:片段在连续片段中的起始位置。segment_end:片段在连续片段中的结束位置。L:基因组片段的长度(512、1024或2048)。segment:片段的基因组序列。label:分类标签(例如,phage)。y:二进制标签(1表示噬菌体,0表示非噬菌体)。
数据分割
数据集结构如下:
sample_test_L512:片段长度为512的测试集。sample_test_L1024:片段长度为1024的测试集。sample_test_L2048:片段长度为2048的测试集。
数据集创建
源数据
数据集从多个基因组源编译而成,重点关注来自RefSeq数据库的噬菌体序列和注释,以及通过TemPhD方法验证的数据集。序列冗余问题通过CD-HIT算法解决。
搜集汇总
数据集介绍
构建方式
该数据集的构建始于对RefSeq数据库和TemPhD数据库中病毒序列及注释的采集,通过筛选标注为'phage'的条目,获取了大量phage contigs。为减少序列冗余,使用了CD-HIT算法进行聚类处理,最终形成了一个包含40,512个独特phage序列的数据集,这些序列平均长度约为43,356个碱基对,总计约35亿个碱基对。该数据集的构建充分考虑了不同细菌属的广泛靶向,并通过映射至相应细菌宿主,确保了样本的多样性和代表性。
特点
该数据集特点显著,其包含的10,000个片段是phage基因组随机样本和片段的集合。数据集通过均衡表示不同属的噬菌体及其宿主,减少了偏差,并包含反向互补序列以确保完整性。数据集由不同长度的序列组成,以适应不同研究需求,并在训练集、验证集和测试集之间保持了平衡的分布。此外,通过欠采样和过采样技术,确保了在物种水平上训练集和测试集之间无重叠。
使用方法
数据集的使用方法包括三个基于不同片段长度(512、1024、2048碱基对)的子集,分别命名为`sample_test_L512`、`sample_test_L1024`和`sample_test_L2048`。每个子集均包含唯一的segment_id、contig_id、segment的起始和结束位置、片段长度、序列本身、分类标签以及二进制标签。用户可根据研究需求选择合适的子集进行下载和使用,同时遵循cc-by-nc-4.0的许可证规定。
背景与挑战
背景概述
neuralbioinfo/phage-test-10k数据集,旨在为噬菌体预测研究提供训练和评估模型的数据基础。该数据集由Balázs Ligeti等研究人员于2023年7月9日从RefSeq数据库中筛选出6,075个标记为'phage'的病毒序列和注释,以及TemPhD数据库中提取的192,326个噬菌体片段组成。数据集通过CD-HIT算法处理序列冗余,最终形成了包含40,512个独特噬菌体序列的集合,这些序列覆盖了660个细菌属,为相关领域的研究提供了宝贵资源。
当前挑战
该数据集在构建过程中面临的挑战主要包括处理序列冗余、保证数据集的平衡代表性以及确保不同长度序列的覆盖范围。此外,数据集在解决噬菌体-宿主关联预测问题的挑战上,需通过精确的采样策略来维持训练集与测试集之间在物种水平上的不重叠,从而确保模型的泛化能力和预测精度。
常用场景
经典使用场景
在生物信息学的领域中,neuralbioinfo/phage-test-10k数据集被广泛应用于噬菌体预测模型的训练与评估。该数据集通过提供经过精心筛选和处理的噬菌体序列,使得研究者能够构建和测试预测模型,以识别和分类噬菌体基因组序列。
衍生相关工作
基于neuralbioinfo/phage-test-10k数据集,已经衍生出一系列相关工作,包括但不限于ProkBERT语言模型家族的研究,这些工作进一步推动了基因组语言模型的发展,并在微生物学、生物信息学等多个领域产生了广泛影响。
数据集最近研究
最新研究方向
在基因组学领域,neuralbioinfo/phage-test-10k数据集的构建旨在促进噬菌体预测模型的研究与评估。该数据集的创建,通过对RefSeq数据库和TemPhD数据库的整合,并应用CD-HIT算法进行序列冗余处理,为研究人员提供了一组由10,000个基因组片段组成的样本数据,这些片段代表了随机选取的噬菌体基因组部分。目前,该数据集在本领域的前沿研究方向主要集中在噬菌体-宿主关联预测的精确性提升,及其在细菌分类学中的应用。通过这一数据集,研究者能够开发更为精确的噬菌体识别工具,对于疾病控制、抗药性管理和微生物生态学研究具有深远的影响。
以上内容由遇见数据集搜集并总结生成


