SPIQA
收藏SPIQA 数据集卡片
数据集详情
数据集名称: SPIQA(Scientific Paper Image Question Answering)
数据集摘要: SPIQA 是一个大规模且具有挑战性的 QA 数据集,专注于来自各种计算机科学领域的科学研究论文中的图表、表格和文本段落。这些图表涵盖了广泛的图表、图表、示意图、结果可视化等。该数据集是通过精心策划过程的结果,利用多模态大型语言模型(MLLMs)的广度和能力来理解图表。我们采用自动和手动策划来确保最高级别的质量和可靠性。SPIQA 包含超过 270K 个问题,分为训练、验证和三种不同的评估拆分。该数据集的目的是评估大型多模态模型理解复杂图表和表格以及科学论文文本段落的能力。
支持的任务:
- 直接通过图表和表格进行 QA
- 直接通过全文进行 QA
- CoT QA(检索有用的图表、表格;然后回答)
语言: 英语
发布日期: SPIQA 于 2024 年 6 月发布。
数据拆分
SPIQA 的不同拆分的统计数据如下:
| <center>拆分</center> | <center>论文</center> | <center>问题</center> | <center>示意图</center> | <center>图表 & 图表</center> | <center>可视化</center> | <center>其他图表</center> | <center>表格</center> |
|---|---|---|---|---|---|---|---|
| <center>训练</center> | <center>25,459</center> | <center>262,524</center> | <center>44,008</center> | <center>70,041</center> | <center>27,297</center> | <center>6,450</center> | <center>114,728</center> |
| <center>验证</center> | <center>200</center> | <center>2,085</center> | <center>360</center> | <center>582</center> | <center>173</center> | <center>55</center> | <center>915</center> |
| <center>测试-A</center> | <center>118</center> | <center>666</center> | <center>154</center> | <center>301</center> | <center>131</center> | <center>95</center> | <center>434</center> |
| <center>测试-B</center> | <center>65</center> | <center>228</center> | <center>147</center> | <center>156</center> | <center>133</center> | <center>17</center> | <center>341</center> |
| <center>测试-C</center> | <center>314</center> | <center>493</center> | <center>415</center> | <center>404</center> | <center>26</center> | <center>66</center> | <center>1,332</center> |
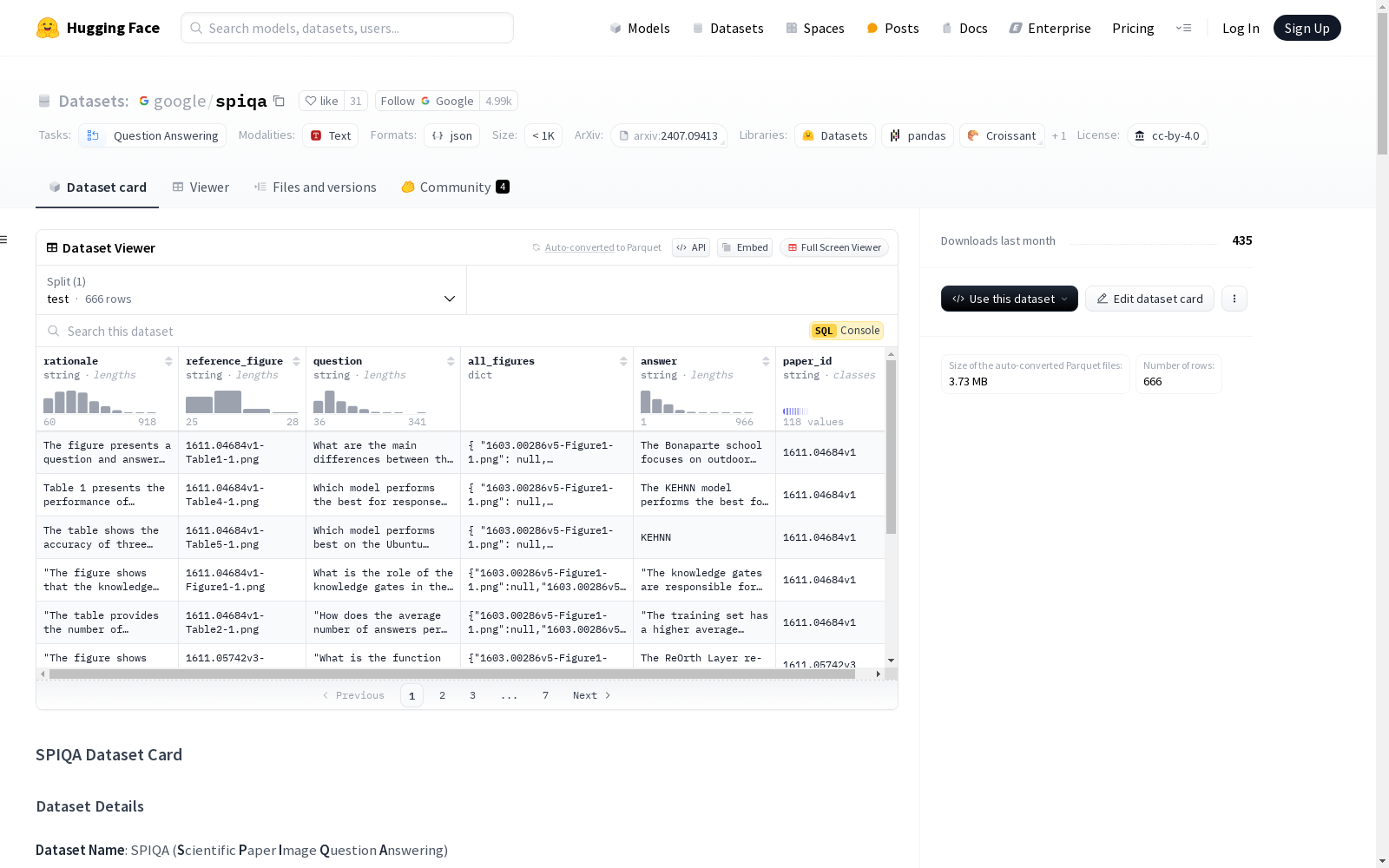
数据集结构
数据集卡片的内容结构如下:
bash SPIQA ├── SPIQA_train_val_test-A_extracted_paragraphs.zip ├── 从 SPIQA 训练、验证和测试-A 拆分中提取的文本段落 ├── SPIQA_train_val_test-A_raw_tex.zip └── SPIQA 训练、验证和测试-A 拆分中的原始 tex 文件。这些文件不是重现我们结果所必需的;我们开源它们用于未来的研究。 ├── train_val ├── SPIQA_train_val_Images.zip └── SPIQA 训练、验证拆分中的全分辨率图表和表格 ├── SPIQA_train.json └── SPIQA 训练元数据 ├── SPIQA_val.json └── SPIQA 验证元数据 ├── test-A ├── SPIQA_testA_Images.zip └── SPIQA 测试-A 拆分中的全分辨率图表和表格 ├── SPIQA_testA_Images_224px.zip └── SPIQA 测试-A 拆分中的 224px 图表和表格 ├── SPIQA_testA.json └── SPIQA 测试-A 元数据 ├── test-B ├── SPIQA_testB_Images.zip └── SPIQA 测试-B 拆分中的全分辨率图表和表格 ├── SPIQA_testB_Images_224px.zip └── SPIQA 测试-B 拆分中的 224px 图表和表格 ├── SPIQA_testB.json └── SPIQA 测试-B 元数据 ├── test-C ├── SPIQA_testC_Images.zip └── SPIQA 测试-C 拆分中的全分辨率图表和表格 ├── SPIQA_testC_Images_224px.zip └── SPIQA 测试-C 拆分中的 224px 图表和表格 ├── SPIQA_testC.json └── SPIQA 测试-C 元数据
testA_data_viewer.json 文件仅用于在 HuggingFace 查看器上查看部分数据,以快速了解元数据。
元数据结构
每个拆分的元数据以字典形式提供,键是论文的 arXiv ID。每个字典项的主要内容包括:
- arXiv ID
- Semantic scholar ID(用于测试-B)
- 图表和表格
- png 文件的名称
- 标题
- 内容类型(图表或表格)
- 图表类型(示意图、图表、照片(可视化)、其他)
- QAs
- 问题、答案和理由
- 参考图表和表格
- 文本证据(用于测试-B 和测试-C)
- 摘要和全文文本(用于测试-B 和测试-C;其他拆分的全文以 zip 文件提供)
数据集使用和入门代码片段
下载数据集到本地
我们建议用户将元数据和图像下载到他们的本地机器。
-
下载整个数据集(所有拆分)。 bash from huggingface_hub import snapshot_download snapshot_download(repo_id="google/spiqa", repo_type="dataset", local_dir=.) ### 指定本地目录路径
-
下载特定文件。 bash from huggingface_hub import hf_hub_download hf_hub_download(repo_id="google/spiqa", filename="test-A/SPIQA_testA.json", repo_type="dataset", local_dir=.) ### 指定本地目录路径
从测试-A 中的特定论文获取问题和答案
bash import json testA_metadata = json.load(open(test-A/SPIQA_testA.json, r)) paper_id = 1702.03584v3 print(testA_metadata[paper_id][qa])
从测试-B 中的特定论文获取问题和答案
bash import json testB_metadata = json.load(open(test-B/SPIQA_testB.json, r)) paper_id = 1707.07012 print(testB_metadata[paper_id][question]) ## 问题 print(testB_metadata[paper_id][composition]) ## 答案
从测试-C 中的特定论文获取问题和答案
bash import json testC_metadata = json.load(open(test-C/SPIQA_testC.json, r)) paper_id = 1808.08780 print(testC_metadata[paper_id][question]) ## 问题 print(testC_metadata[paper_id][answer]) ## 答案
注释概述
SPIQA 训练、验证和测试-A 集的问题和答案是机器生成的。此外,SPIQA 测试-A 集经过手动过滤和策划。SPIQA 测试-B 集的问题来自 QASA 数据集,而 SPIQA 测试-C 集的问题来自 QASPER 数据集。所有拆分中的问题回答都需要对图表和表格以及相关的科学论文文本进行整体理解。
个人和敏感信息
我们不知道数据集中有任何个人或敏感信息。
许可信息
CC BY 4.0
引用信息
bibtex @article{pramanick2024spiqa, title={SPIQA: A Dataset for Multimodal Question Answering on Scientific Papers}, author={Pramanick, Shraman and Chellappa, Rama and Venugopalan, Subhashini}, journal={arXiv preprint arXiv:2407.09413}, year={2024} }
- 1SPIQA: A Dataset for Multimodal Question Answering on Scientific Papers谷歌研究院,约翰斯·霍普金斯大学 · 2024年


