mauxi-mix-persian
收藏Hugging Face2024-12-01 更新2024-12-12 收录
下载链接:
https://huggingface.co/datasets/xmanii/mauxi-mix-persian
下载链接
链接失效反馈官方服务:
资源简介:
MauxiMix是一个精心策划的波斯语对话数据集,包含1000个高质量的波斯语对话,这些对话是从SmolTalk数据集翻译而来的。该数据集专门设计用于使用监督微调(SFT)技术训练和微调大型语言模型(LLMs),有助于开发开源的波斯语语言模型。数据集的每个对话都包含消息列表、类别和难度级别。类别包括编程、数学、创意写作等,难度级别从非常简单到非常困难不等。数据集目前包含1000个对话,计划扩展到10000个对话。
创建时间:
2024-12-01
原始信息汇总
MauxiMix: High-Quality Persian Conversations Dataset
描述
MauxiMix 是一个精心策划的包含 1,000 个高质量波斯语对话的数据集,这些对话是从 SmolTalk 数据集使用先进的语言模型翻译而来的。该数据集专门设计用于训练和微调大型语言模型(LLMs),采用监督微调(SFT)技术,有助于开发开源波斯语语言模型。
主要特点
- 1,000 个专业翻译的波斯语对话
- 按特定主题和难度级别分类
- 基于角色的对话格式(用户/助手)
- 使用 GPT-4o-mini 进行高质量翻译
- 非常适合 LLM 训练和微调
数据集结构
每个对话遵循以下格式: json { "messages": [ {"role": "user", "content": "波斯语消息"}, {"role": "assistant", "content": "波斯语回复"} ], "category": "波斯语类别", "difficulty": "波斯语难度级别" }
类别与难度级别
类别
- برنامهنویسی (编程)
- ریاضیات (数学)
- نگارش خلاق (创意写作)
- تحلیل داده (数据分析)
- ویرایش (编辑)
- استدلال (推理)
- طوفان فکری (头脑风暴)
- برنامهریزی (规划)
- درخواست مشاوره (寻求建议)
- جستجوی اطلاعات (信息搜索)
难度级别
- خیلی آسان (非常简单)
- آسان (简单)
- متوسط (中等)
- سخت (困难)
- خیلی سخت (非常困难)
使用场景
- 训练波斯语语言模型
- 微调现有 LLMs 用于波斯语
- SFT(监督微调)训练
- 波斯语 NLP 研究
- 创建专门的波斯语 AI 助手
数据集统计
- 总对话数:1,000(扩展至 10,000)
- 按对话长度筛选:108-717 个词元
- 格式:Hugging Face 数据集
- 精心筛选的类别和难度级别
技术细节
- 源数据集:SmolTalk
- 翻译模型:GPT-4o-mini
- 质量保证:自动筛选和一致性检查
- 格式:Hugging Face 数据集
- 特征:
- messages: List[Dict]
- category: string
- difficulty: string
引用
如果您在研究中使用此数据集,请引用: bibtex @dataset{mauxitalk2024, name = {MauxiMix}, author = {Maux AI}, year = {2024}, publisher = {Hugging Face}, url = {https://huggingface.co/datasets/xmanii/mauxi-mix-persian} }
目标
MauxiMix 的主要目标是促进高质量开源波斯语语言模型的开发。通过提供这个精心策划的数据集,我们旨在:
- 提高 AI 模型对波斯语的理解
- 支持开源 AI 社区
- 实现更好的 LLMs 波斯语任务微调
- 创建更准确和文化上更敏感的波斯语 AI 助手
许可证
该数据集在 MIT 许可证下发布。
搜集汇总
数据集介绍
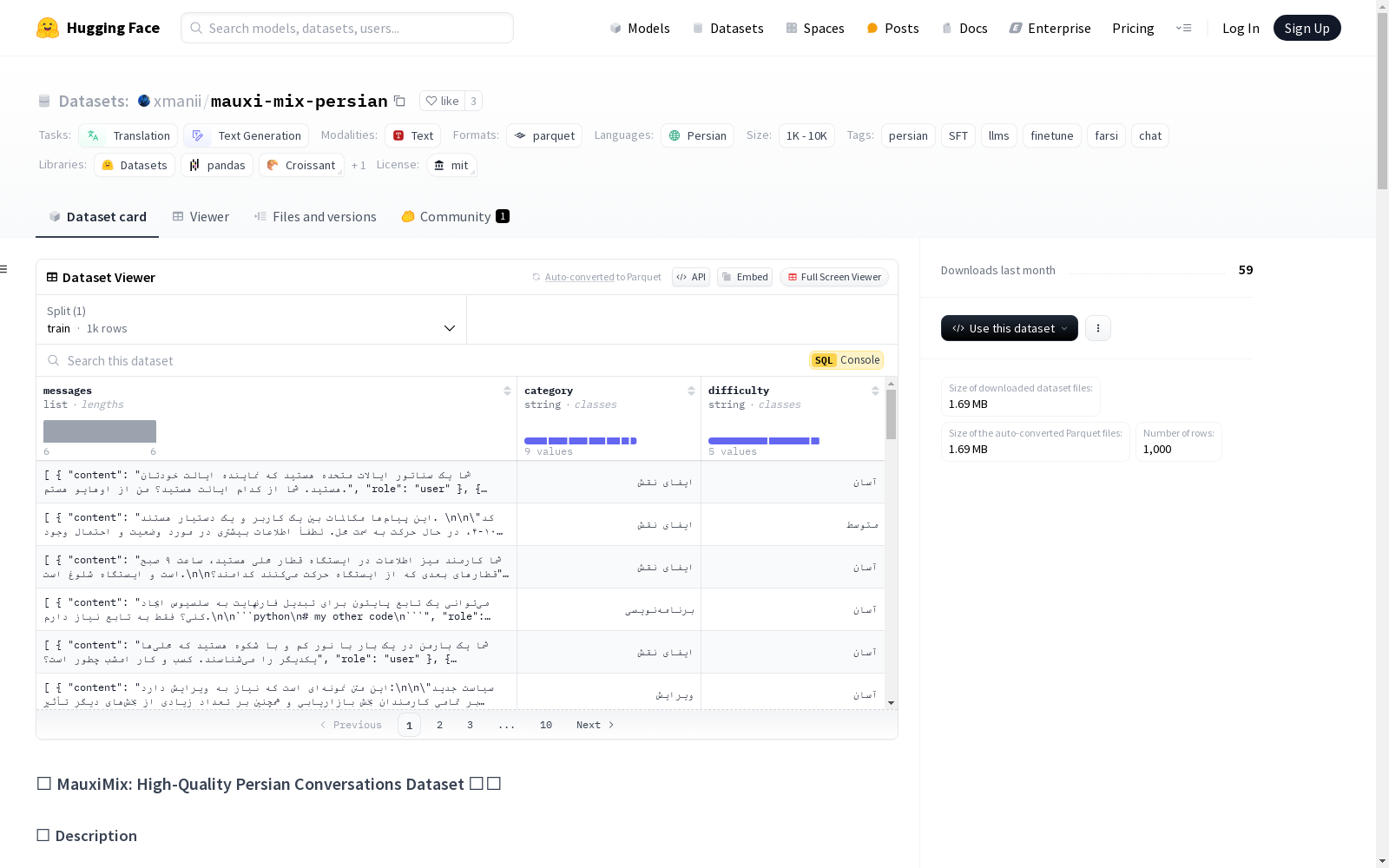
构建方式
MauxiMix数据集的构建基于SmolTalk数据集,通过先进的语言模型GPT-4o-mini进行高质量的波斯语翻译。该数据集精心挑选了1000条波斯语对话,每条对话均包含用户与助手的角色分配,并根据特定主题和难度级别进行分类。构建过程中,采用了自动化过滤和一致性检查,确保数据质量,为大规模语言模型的训练和微调提供了坚实的基础。
使用方法
MauxiMix数据集适用于多种场景,包括波斯语语言模型的训练、现有大规模语言模型的微调以及监督式微调(SFT)训练。用户可以通过Hugging Face平台轻松访问该数据集,并利用其结构化的对话格式进行模型训练。此外,该数据集还支持波斯语AI助手的开发,为波斯语社区提供了强大的语言处理工具。
背景与挑战
背景概述
MauxiMix 数据集是由 Maux AI 创建的高质量波斯语对话数据集,旨在推动波斯语自然语言处理(NLP)领域的发展。该数据集基于 SmolTalk 数据集,通过先进的语言模型(如 GPT-4o-mini)进行翻译和优化,包含 1,000 条高质量的波斯语对话,涵盖多个主题和难度级别。MauxiMix 的主要研究目标是提升波斯语在大型语言模型(LLMs)中的表现,支持监督微调(SFT)技术,并为波斯语 AI 助手的开发提供基础。该数据集的创建不仅填补了波斯语 NLP 领域的空白,还为开源社区提供了宝贵的资源,推动了波斯语语言模型的研究与应用。
当前挑战
MauxiMix 数据集在构建过程中面临多项挑战。首先,波斯语作为一种资源相对较少的语言,其语法结构和词汇的复杂性增加了翻译和质量控制的难度。其次,确保翻译的准确性和文化适应性是一个重要挑战,尤其是在处理特定主题(如编程、数学等)时,需要高度的专业知识。此外,数据集的扩展计划(从 1,000 条扩展到 10,000 条)也对数据筛选和质量保证提出了更高的要求。最后,如何在保持数据多样性的同时,确保对话的连贯性和自然性,也是该数据集面临的一大挑战。
常用场景
经典使用场景
MauxiMix数据集的经典使用场景主要集中在波斯语(Persian)自然语言处理领域,尤其是在训练和微调大型语言模型(LLMs)方面。该数据集包含了1000条高质量的波斯语对话,这些对话经过专业翻译,并按照特定主题和难度级别进行分类。通过这些对话,研究者和开发者可以有效地进行监督微调(SFT),从而提升波斯语语言模型的性能和准确性。
解决学术问题
MauxiMix数据集解决了波斯语自然语言处理领域中高质量对话数据稀缺的问题。由于波斯语在学术研究中的资源相对有限,该数据集的引入为研究者提供了一个宝贵的资源,有助于推动波斯语语言模型的研究进展。通过提供结构化的对话数据,该数据集支持了波斯语语言理解、生成和推理等多个学术研究方向,极大地丰富了波斯语NLP的研究内容。
实际应用
在实际应用中,MauxiMix数据集被广泛用于开发和优化波斯语AI助手。这些助手可以应用于多个领域,如编程、数学、数据分析等,为用户提供精准的波斯语语言支持。此外,该数据集还支持波斯语语言模型的微调,使得这些模型能够更好地适应特定任务,如信息检索、创意写作和咨询服务等,从而提升用户体验和应用效果。
数据集最近研究
最新研究方向
近年来,随着自然语言处理(NLP)技术的飞速发展,波斯语(Persian)语言模型的研究逐渐成为国际学术界关注的焦点。MauxiMix数据集的推出,为波斯语语言模型的训练与微调提供了高质量的对话数据资源。该数据集不仅包含了1000条精心翻译的波斯语对话,还通过分类和难度级别进一步细化了数据结构,使得研究者能够更精准地进行模型训练。当前,波斯语NLP领域的前沿研究主要集中在通过监督微调(SFT)技术提升语言模型的性能,尤其是在特定任务如编程、数学、数据分析等领域的应用。此外,随着数据集规模的扩展至10,000条对话,预计将进一步推动波斯语AI助手的开发,增强模型在多领域任务中的表现,并为波斯语社区的开源AI发展提供有力支持。
以上内容由遇见数据集搜集并总结生成


