pixelprose
收藏Hugging Face2024-06-18 更新2024-12-12 收录
下载链接:
https://huggingface.co/datasets/tomg-group-umd/pixelprose
下载链接
链接失效反馈官方服务:
资源简介:
PixelProse是一个包含1600万个合成生成的图像描述的综合数据集,利用Gemini 1.0 Pro Vision模型生成详细和准确的描述。数据集提供了丰富的变量,包括图像的唯一标识符、URL、描述模型、描述内容等,并支持多种下载和使用方式。
PixelProse is a comprehensive dataset containing 16 million synthetically generated image captions, which are produced in detailed and accurate form via the Gemini 1.0 Pro Vision model. The dataset provides a rich set of attributes, including unique image identifiers, URLs, captioning models, caption contents, and more, and supports multiple download and usage methods.
创建时间:
2024-06-14
原始信息汇总
PixelProse 数据集概述
数据集基本信息
- 许可证: cc-by-4.0
- 任务类别:
- 图像到文本
- 文本到图像
- 视觉问答
- 语言: 英语
- 标签: croissant
- 名称: PixelProse
- 大小类别: 10M<n<100M
数据集配置
- 默认配置:
- 训练集: data/vlm_captions_*.parquet
- CC12M: data/vlm_captions_cc12m_*.parquet
- CommonPool: data/vlm_captions_common-pool_*.parquet
- RedCaps: data/vlm_captions_redcaps_*.parquet
数据集详细信息
- 总图像-文本对数: 16,896,214 (16.9M)
- CommonPool: 6,538,898 (6.5M)
- CC12M: 9,066,455 (9.1M)
- RedCaps: 1,290,861 (1.3M)
数据下载
- Parquet 文件下载:
-
通过 Git LFS: bash git lfs install git clone https://huggingface.co/datasets/tomg-group-umd/pixelprose
-
通过 Huggingface API: python from datasets import load_dataset ds = load_dataset("tomg-group-umd/pixelprose")
-
通过直接链接: 访问 data 目录下载所需文件。
-
变量列
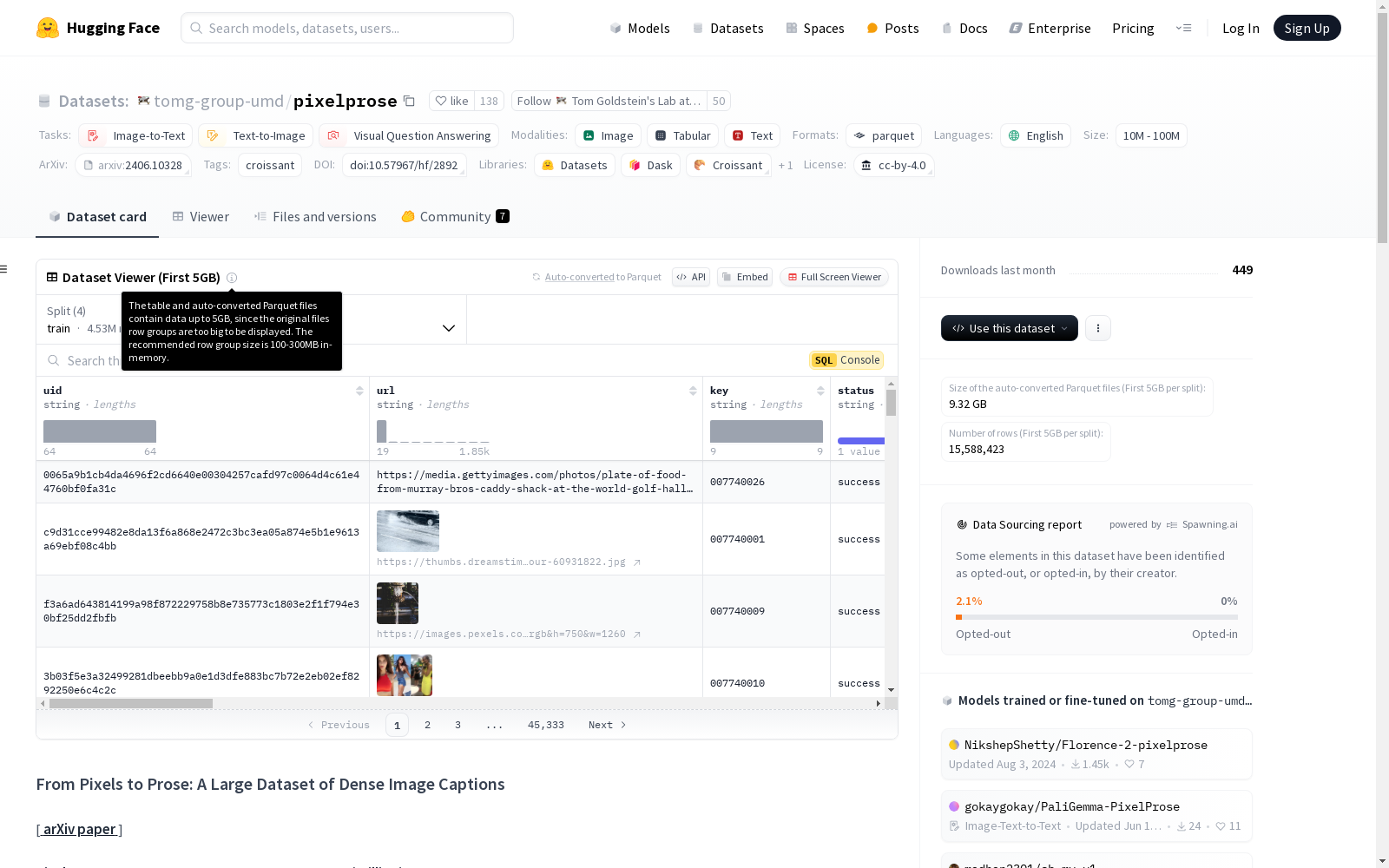
uid: 图像唯一标识符url: 图像URLkey: 图像关联键status:vlm_model返回的状态original_caption: 源继承的描述vlm_model: 用于描述图像的模型vlm_caption: PixelProse的密集描述toxicity: 一般有害行为的评分severe_toxicity: 极其有害和辱骂性语言的评分obscene: 使用淫秽或不当语言的评分identity_attack: 针对基于身份的个人或群体的语言评分insult: 旨在侮辱或贬低的语言评分threat: 传达威胁伤害的语言评分sexual_explicit: 包含性显式内容的语言评分watermark_class_id: 水印分类 (0= 带水印的图像,1= 无水印的图像,2= 无水印但有文本的图像)watermark_class_score: 每个水印类的预测分数,范围从[0, 1]aesthetic_score: 美学评分,范围从[0, 10]error_message:vlm_model返回的错误消息width / height: 下载并用于运行vlm_model的图像尺寸original_width / original_height: 图像的原始尺寸exif: 图像文件的EXIF信息sha256: 图像文件的SHA256哈希image_id,author,subreddit,score: 继承自RedCaps的属性,CC12M和CommonPool中不可用
搜集汇总
数据集介绍
构建方式
PixelProse数据集通过先进的视觉-语言模型(如Gemini 1.0 Pro Vision)生成超过1600万条密集图像描述,涵盖了CommonPool、CC12M和RedCaps等多个数据源的图像-描述对。这些描述通过模型自动生成,确保了描述的详细性和准确性。数据集的构建过程包括从多个公开数据集中提取图像,并利用视觉-语言模型生成对应的密集描述,最终形成包含丰富元数据的Parquet文件。
使用方法
使用PixelProse数据集时,首先需要通过Git LFS、Huggingface API或直接链接下载Parquet文件。这些文件包含了图像的URL、描述以及各种元数据。研究者可以通过Huggingface API加载特定数据分割,如CommonPool、CC12M或RedCaps。下载图像时,可以使用img2dataset等工具。数据集的多变量列提供了丰富的分析维度,研究者可以根据需要提取和使用这些变量进行模型训练或评估。
背景与挑战
背景概述
PixelProse数据集由马里兰大学的研究团队于2024年发布,旨在推动视觉语言模型(VLM)在图像描述生成领域的发展。该数据集包含超过1600万条由先进视觉语言模型(如Gemini 1.0 Pro Vision)生成的密集图像描述,涵盖了CommonPool、CC12M和RedCaps等多个子集。PixelProse的创建不仅为图像到文本、文本到图像以及视觉问答等任务提供了丰富的数据支持,还通过引入毒性评分、美学评分等多元变量,进一步拓展了数据集的应用场景。该数据集的发布为视觉语言模型的研究提供了新的基准,推动了多模态人工智能的发展。
当前挑战
PixelProse数据集在构建过程中面临多重挑战。首先,生成高质量的密集图像描述需要依赖先进的视觉语言模型,而这些模型的训练和优化本身具有较高的技术门槛。其次,数据集中的图像来源多样,涵盖了不同场景和风格,如何确保生成的描述在多样性和准确性之间取得平衡是一个关键问题。此外,数据集中引入了毒性评分、美学评分等复杂变量,这些变量的标注和评估需要大量的人工干预和算法支持,增加了数据集的构建难度。最后,数据集的规模庞大,如何高效地存储、管理和分发这些数据也是一个不容忽视的技术挑战。
常用场景
经典使用场景
PixelProse数据集在图像到文本生成领域具有广泛的应用,尤其是在视觉语言模型(VLM)的训练和评估中。该数据集通过提供超过1600万条高质量的图像-文本对,为研究人员提供了丰富的素材,用于训练模型生成精确且详细的图像描述。这些描述不仅涵盖了图像的基本内容,还深入到了细节层面,使得模型能够更好地理解图像的复杂结构和语义信息。
解决学术问题
PixelProse数据集解决了视觉语言模型在生成图像描述时面临的诸多挑战,如描述的准确性和多样性问题。通过使用先进的视觉语言模型(如Gemini 1.0 Pro Vision),该数据集生成了大量高质量的图像描述,显著提升了模型在图像理解与文本生成任务中的表现。此外,数据集中的毒性评分和美学评分等变量,也为研究图像内容的安全性和审美价值提供了新的视角。
实际应用
在实际应用中,PixelProse数据集被广泛用于开发智能图像标注系统、视觉问答系统以及内容审核工具。例如,社交媒体平台可以利用该数据集训练模型,自动生成图像描述并检测不当内容,从而提升用户体验和平台安全性。此外,该数据集还可用于教育领域,帮助开发辅助教学工具,为学生提供更直观的学习材料。
数据集最近研究
最新研究方向
在视觉-语言模型(VLM)领域,PixelProse数据集以其超过1600万条合成生成的密集图像描述,成为当前研究的热点之一。该数据集通过结合前沿的Gemini 1.0 Pro Vision模型,提供了高度精确的图像描述,推动了图像到文本、文本到图像以及视觉问答任务的发展。近年来,随着多模态学习的兴起,PixelProse在生成式AI、图像理解与生成、以及跨模态检索等方向展现出巨大潜力。其丰富的变量信息,如毒性评分、美学评分等,也为内容安全与质量评估提供了新的研究视角。该数据集的发布不仅填补了大规模密集图像描述数据的空白,还为视觉-语言模型的训练与评估提供了重要资源,进一步推动了多模态AI技术的创新与应用。
以上内容由遇见数据集搜集并总结生成


