SURD
收藏Hugging Face2025-09-04 更新2025-09-05 收录
下载链接:
https://huggingface.co/datasets/zhongshsh/SURD
下载链接
链接失效反馈官方服务:
资源简介:
SURD数据集是一种为文本到图像生成构建高质量文本语义表示的适配器,名为Semantic Understanding and Reasoning (SUR-adapter)。该数据集通过从大型语言模型中获取强大的语义理解和推理能力,用于预训练的扩散模型。数据集经过筛选,去除了不适合工作场所的内容,保留了中性内容和绘画,共有26121个样本。
创建时间:
2025-09-04
原始信息汇总
SURD 数据集概述
数据集简介
SURD 数据集是实现论文《SUR-adapter: Enhancing Text-to-Image Pre-trained Diffusion Models with Large Language Models》的数据集。该论文已被第31届ACM国际多媒体会议(ACM MM 2023,口头报告)接受。
数据集声明
非NSFW版本
原始SURD数据集包含部分性暴露图像及其他不适宜传播的内容,因此使用nsfw工具包进行过滤。nsfw将图像分为五类:porn、hentai、sexy、neutral和drawings。仅保留标记为neutral和drawings的图像,确保内容适合工作环境,形成工作适用版本的SURD(共26121个样本)。
数据集更新
用户可尝试从互联网收集更多最新数据。已提供Civitai的数据抓取代码,需将数据集准备为SURD格式。
许可与警告
数据集采用MIT许可证。数据集内容收集自Lexica、Civitai和Stable Diffusion Online。许可指出若将数据集用于商业用途可能存在法律风险,如需商业使用请联系相关网站或作者获取授权。
搜集汇总
数据集介绍
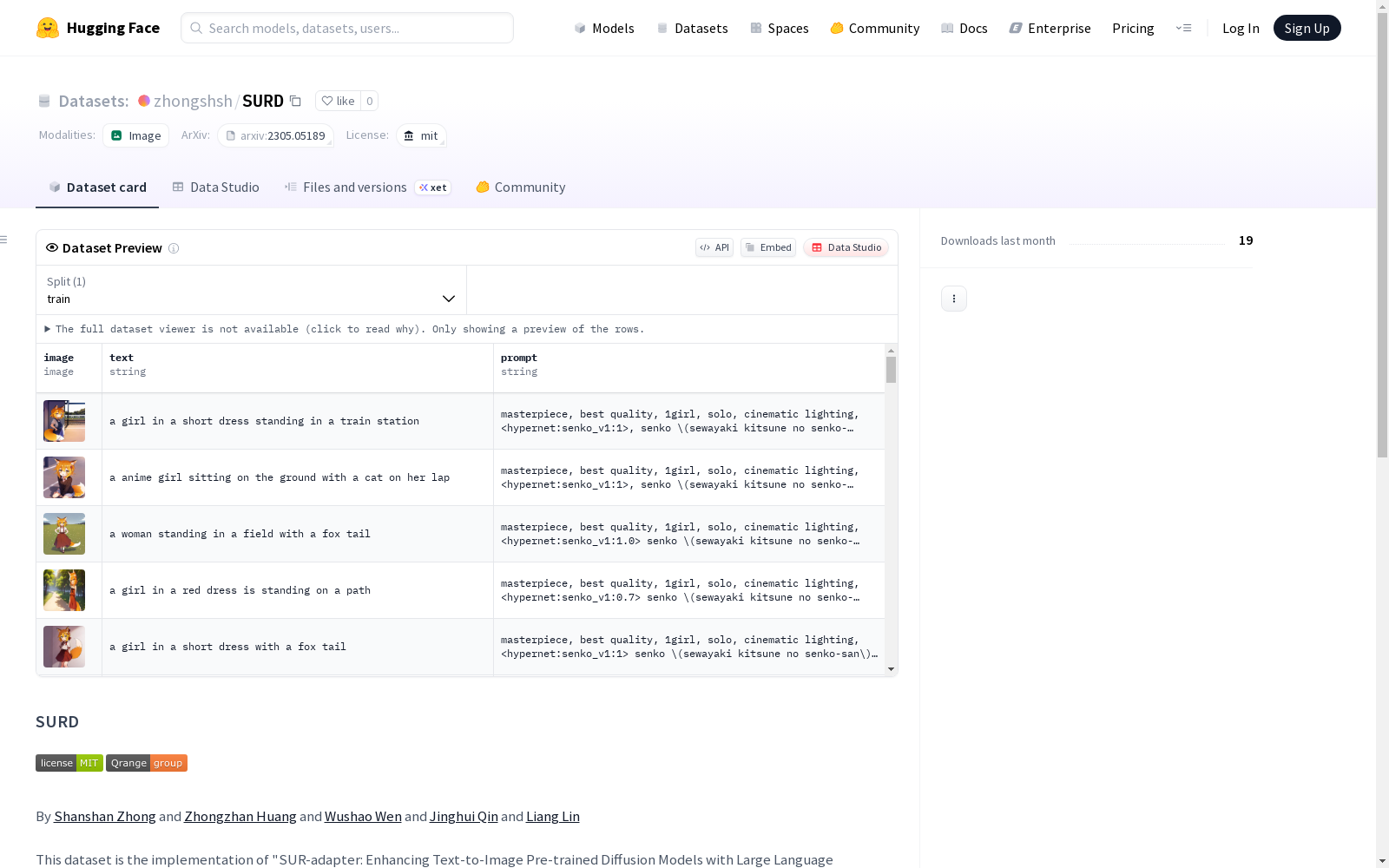
构建方式
在人工智能生成内容领域,SURD数据集的构建体现了多源异构数据的整合策略。该数据集源自Lexica、Civitai和Stable Diffusion Online三大平台的公开资源,通过自动化爬取技术获取初始图像-文本对。为确保内容安全性,研究团队采用nsfw分类器对原始数据进行严格过滤,仅保留被标记为neutral和drawings的职场安全样本,最终形成包含26121个样本的洁净版本。数据标注过程充分遵循各平台的许可协议,并针对商业用途提供了明确的法律风险提示。
使用方法
该数据集主要用于增强扩散模型的语义理解与推理能力。研究人员可按照标准数据加载流程,将图像-文本对输入到预训练扩散模型中实施微调。使用前需通过官方提供的预处理脚本转换数据格式,确保与模型架构兼容。为保障合规使用,建议非商业研究场景优先采用经过过滤的洁净版本,若需扩展数据集规模可参照开源的数据采集代码自行构建,但必须严格遵守各数据源平台的许可协议条款。
背景与挑战
背景概述
SURD数据集由广东大学群体于2023年构建,核心研究人员包括钟珊珊、黄忠展等,旨在支撑文本到图像生成领域的前沿研究。该数据集作为SUR-adapter技术框架的实践基础,致力于融合大语言模型的语义理解能力与预训练扩散模型的生成效能,推动多媒体内容生成技术的智能化发展。其构建契合了生成式人工智能在多模态交互中的迫切需求,为ACM国际多媒体会议认可的高质量研究提供了数据支撑。
当前挑战
SURD数据集首要解决文本到图像生成中语义对齐与推理的复杂性问题,需克服多源异构数据整合与高质量语义标注的挑战。构建过程中面临非适宜内容的严格过滤,依托nsfw工具识别并剔除敏感图像,仅保留符合安全标准的样本。此外,数据源自Lexica、Civitai等平台,涉及多重许可协议,商业应用需规避法律风险,需通过授权协商解决版权问题。
常用场景
经典使用场景
在文本到图像生成的跨模态研究领域,SURD数据集作为语义理解与推理任务的基准数据集,被广泛用于评估扩散模型对复杂文本描述的视觉表达能力。研究者通过该数据集训练模型解析包含多对象关系、抽象概念和场景逻辑的文本提示,生成符合语义约束的高质量图像,尤其在测试模型对长文本和隐含语义的视觉化能力方面具有重要价值。
解决学术问题
SURD数据集有效解决了文本到图像生成中语义对齐与细粒度控制的学术难题。通过提供大规模文本-图像对及其语义标注,它支持模型学习语言与视觉之间的深层映射关系,显著提升了生成图像与文本语义的一致性。该数据集推动了对扩散模型中语义注入机制的研究,为多模态表示学习提供了关键数据支撑。
实际应用
在实际应用中,SURD数据集为创意设计、教育媒体和娱乐产业提供了技术基础。基于该数据集训练的模型能够根据用户输入的描述性文本自动生成概念图、插画或视觉原型,显著降低艺术创作的门槛和时间成本。此外,它在虚拟场景构建、广告设计辅助以及个性化内容生成等领域展现出广泛的应用潜力。
数据集最近研究
最新研究方向
SURD数据集作为多模态生成领域的重要资源,正推动文本到图像生成模型的语义理解与推理能力研究。当前前沿工作聚焦于融合大型语言模型与预训练扩散模型,通过语义适配器架构突破传统提示工程的局限性。该方向与生成式人工智能的可靠性与安全性研究热点紧密关联,尤其在内容过滤机制和伦理规范构建方面具有显著影响。其技术路径为构建高质量语义表示提供了新范式,对跨模态创造性任务的可持续发展具有深远意义。
以上内容由遇见数据集搜集并总结生成


