arxiv-funding-entity-extractions
收藏Hugging Face2026-05-02 更新2026-05-03 收录
下载链接:
https://huggingface.co/datasets/cometadata/arxiv-funding-entity-extractions
下载链接
链接失效反馈官方服务:
资源简介:
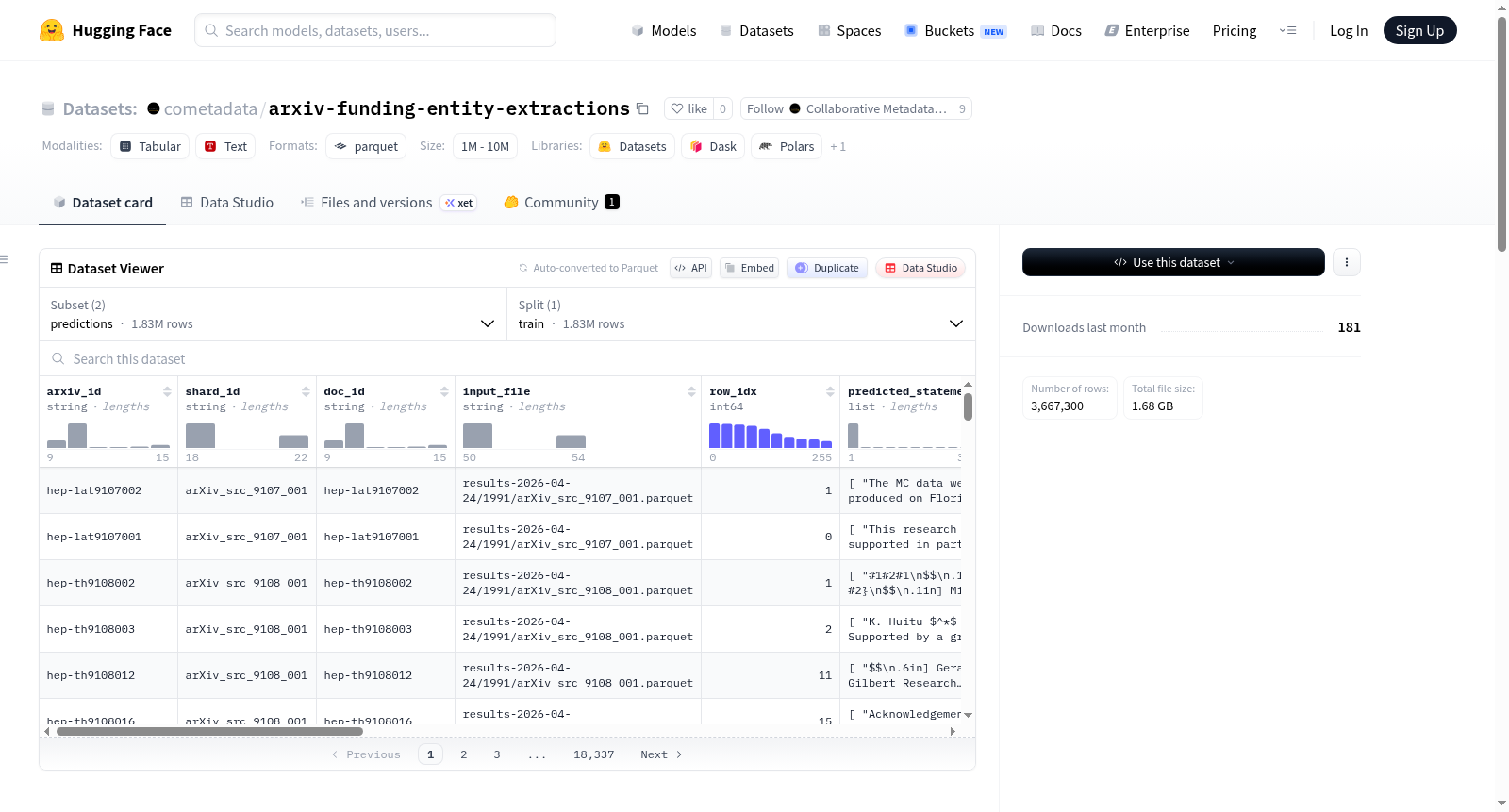
arxiv-funding-entity-extractions数据集包含从cometadata/arxiv-funding-statements中提取的资助者/奖励实体信息。数据集使用基于vLLM + LoRA技术的funding-entity-extractor进行提取,基础模型为meta-llama/Llama-3.1-8B-Instruct,LoRA模型为cometadata/funding-extraction-llama-3.1-8b-instruct-artifact-data-mix-grpo-mixed-reward,在A100-large bf16硬件上运行,并发数为256。数据集总行数为1,823,650,提供两种配置:predictions(原始提取结果,不含ROR信息)和predictions_with_ror(相同行数,但每个资助者附加了ROR ID)。每行数据包含原始数据集的所有列(如arxiv_id、shard_id等)以及四个提取相关列:extracted_funders(提取的资助者信息,包括资助者名称和奖励详情)、extraction_raw(模型原始输出)、extraction_error(提取错误信息)和extraction_latency_ms(提取延迟时间)。predictions_with_ror配置额外包含ror_id(匹配的ROR URL)和match_confidence(匹配置信度)字段。ROR匹配过程包括使用marple匹配服务进行自动匹配和人工策划的分配层,最终覆盖了66.07%的资助者出现次数。
The arxiv-funding-entity-extractions dataset contains funder/award entity information extracted from cometadata/arxiv-funding-statements. The dataset was extracted using funding-entity-extractor (based on vLLM + LoRA technology), with the base model being meta-llama/Llama-3.1-8B-Instruct and the LoRA model being cometadata/funding-extraction-llama-3.1-8b-instruct-artifact-data-mix-grpo-mixed-reward, running on A100-large bf16 hardware with a concurrency of 256. The total number of rows in the dataset is 1,823,650. The dataset provides two configurations: predictions (raw extraction results without ROR information) and predictions_with_ror (same number of rows but with ROR IDs attached to each funder). Each row of data contains all columns from the original dataset (such as arxiv_id, shard_id, etc.) and four extraction-related columns: extracted_funders (extracted funder information, including funder name and award details), extraction_raw (raw model output), extraction_error (extraction error information), and extraction_latency_ms (extraction latency time). The predictions_with_ror configuration additionally includes the ror_id (matched ROR URL) and match_confidence (match confidence) fields. The ROR matching process includes automatic matching using the marple matching service and a manually curated assignment layer, ultimately covering 66.07% of funder occurrences.
创建时间:
2026-04-26
原始信息汇总
数据集概览
数据集名称:arxiv-funding-entity-extractions
数据集地址:https://huggingface.co/datasets/cometadata/arxiv-funding-entity-extractions
该数据集是基于 cometadata/arxiv-funding-statements 的资助机构及奖项实体提取结果,共包含 1,823,650 行数据。
提取方式
- 提取器:
funding-entity-extractor(基于 vLLM + LoRA) - 基座模型:
meta-llama/Llama-3.1-8B-Instruct - LoRA 适配器:
cometadata/funding-extraction-llama-3.1-8b-instruct-artifact-data-mix-grpo-mixed-reward - 硬件:A100-large bf16,并发数 256
数据集配置(Configs)
| 配置名称 | 说明 | 默认 |
|---|---|---|
predictions |
原始提取结果,未经过 ROR 丰富 | 是 |
predictions_with_ror |
相同行数据,额外为每个资助机构附加 ROR ID | 否 |
数据模式(Schema)
每条记录包含来自 cometadata/arxiv-funding-statements 的所有输入列(如 arxiv_id、shard_id、doc_id、input_file、row_idx、predicted_statements、predicted_details、text_length、latency_ms、error),此外新增四个提取列:
extracted_funders:list<list<struct{funder_name, awards: list<struct{award_ids, funding_scheme, award_title}>}>>
外层列表与predicted_statements平行,内层列表为该语句中发现的资助机构(解析失败时为null)。extraction_raw:list<string>— 模型对每条语句的原始输出文本。extraction_error:list<string>— 成功时为null,失败时包含"ParseError: ..."或"HTTPError: ..."。extraction_latency_ms:list<float64>— 每条语句的处理耗时(毫秒)。
ROR 丰富(ROR Enrichment)
在 predictions_with_ror 配置中,每个资助机构结构体(位于 extracted_funders 内)增加了两个字段:
ror_id:可空字符串 — 匹配的 ROR URL(如https://ror.org/<id>),未匹配时为null。match_confidence:可空双精度浮点数 — 匹配服务的置信度分数,人工分配的条目为null。
丰富后的结构体形状为:
struct{ funder_name: string, awards: list<struct{award_ids, funding_scheme, award_title}>, ror_id: string?, match_confidence: double? }
处理流程
- 从
predictions/*.parquet提取唯一的资助机构名称。 - 使用 marple 匹配服务(基于 Jason Portenoy 开发的资助机构策略)进行匹配。
- 人工分配层补充了 97 个高频资助机构名称(如
NSF、NIH、DOE等三字母缩写及常见全名变体),这些条目的match_confidence设为null以便与匹配服务结果区分。 - 匹配结果按分片回连到原始 Parquet 文件,其他所有列保持不变。
覆盖情况
- 整个语料库中的资助机构出现次数总计:4,827,173
- 仅通过 marple 服务匹配:2,035,930(42.18%)
- 通过 marple + 人工分配匹配:3,189,332(66.07%)
搜集汇总
数据集介绍
构建方式
该数据集基于大规模学术文献资助声明数据集`cometadata/arxiv-funding-statements`构建,利用`funding-entity-extractor`提取器,以`meta-llama/Llama-3.1-8B-Instruct`为基座模型,并通过`cometadata/funding-extraction-llama-3.1-8b-instruct-artifact-data-mix-grpo-mixed-reward`的LoRA微调技术进行优化。在A100-large bf16硬件支持下,以256并发度高效处理了共计1,823,650条数据,生成了资助实体与奖项信息的结构化抽取结果。
特点
数据集提供两种配置:默认的`predictions`包含原始抽取结果,而`predictions_with_ror`则额外融入了ROR标识符的富化信息。通过`marple`匹配服务与人工策划的分配层,为高频资助方(如NSF、NIH等)补充了机构标识符,使匹配覆盖率从42.18%提升至66.07%。每条记录详细记录了抽取的资助方名称、奖项列表、原始模型输出、错误信息及延迟数据,数据结构清晰且易于分析。
使用方法
用户可通过HuggingFace加载数据集的`predictions`或`predictions_with_ror`配置,直接使用Parquet文件进行数据处理。对于需要机构识别符的科研计量分析,推荐使用`predictions_with_ror`配置,其中每个资助方条目均包含可空的`ror_id`字段和匹配置信度。数据集适用于学术资助趋势分析、科研资金网络研究以及自然语言处理中的实体抽取任务评估,可通过Python的`datasets`库加载并进行下游分析。
背景与挑战
背景概述
在科研资助信息自动提取领域,从学术文献中精准识别资助实体与奖项信息是构建开放科学基础设施的关键一环。由Cometadata团队于2024年基于arXiv平台发布的arxiv-funding-entity-extractions数据集,以大规模科研资助声明库`cometadata/arxiv-funding-statements`为基础,通过基于Llama-3.1-8B-Instruct模型的微调与强化学习策略,实现了对超过180万条资助声明的实体级抽取。该数据集的核心研究问题在于如何运用大语言模型(LLM)高效解析非结构化文本中的资助机构名称、奖项编号及资助方案,其发布显著推动了学术信息抽取领域的标准化进程,为后续研究资助网络分析、跨机构合作评估等任务提供了高质量语料支撑。
当前挑战
该数据集主要解决了非结构化科研资助文本中实体细粒度识别的领域挑战,包括从长尾分布、缩写歧义(如NSF、NIH等三字母缩写)的文本中提取结构化的机构-奖项关系。在构建过程中,数据集面临两大技术瓶颈:其一,基础模型在初始预测中遇到大量解析错误(ParseError)与HTTP错误,需通过强化学习调优降低错误率;其二,ROR(Research Organization Registry)匹配环节面临高覆盖需求,原始匹配服务仅覆盖42.18%的资助机构出现频次,最终通过引入97个人工策展的高频机构映射层(如处理模糊四字母缩写及全称变体)将覆盖率提升至66.07%,同时保留匹配置信度标记以区分自动匹配与人工赋值结果。
常用场景
经典使用场景
在科研经费信息挖掘领域,arxiv-funding-entity-extractions数据集为从海量学术文献中提取资助实体与奖项信息提供了关键支撑。该数据集基于arXiv论文中的资助声明,利用大语言模型结合LoRA微调技术,实现了对资助机构名称、奖项编号、资助方案及奖项标题等结构化信息的精准抽取。经典使用场景聚焦于构建端到端的科研资助信息提取流水线,研究者和工程师可借助此数据集训练或评估命名实体识别模型,尤其适用于处理非结构化学术文本中的复杂资金关系,助力科研管理决策与学术影响力分析。
衍生相关工作
基于该数据集衍生的经典工作包括资助实体抽取模型的迭代优化、跨模态信息融合方法的发展,以及科研知识图谱的构建研究。其中,利用GRPO混合奖励策略增强LoRA微调效果的方案,展示了强化学习在领域特定信息提取中的潜力。后续工作进一步探索了将资助实体与论文全文、作者网络、专利数据联动的联合实体关系抽取框架。此外,以marple匹配服务为基础开发的机构名称消歧算法,成为开放研究信息标准化的重要工具。这些衍生成果不仅拓展了科研数据挖掘的技术边界,也为实现联合国可持续发展目标下的科研公平性分析提供了可复用的方法论基础。
数据集最近研究
最新研究方向
该数据集聚焦于利用大语言模型(LLM)从arXiv论文中提取资助实体信息,代表了学术资助信息自动抽取领域的前沿方向。其采用Llama-3.1-8B-Instruct模型结合LoRA微调与GRPO强化学习策略,实现了对182万条资助声明的结构化解析,并创新性地引入ROR标识符(Research Organization Registry)进行资助机构消歧,通过Marple匹配服务与人工策展层将机构识别覆盖率从42.18%提升至66.07%。这一工作与当前科研诚信与资助透明度热点事件紧密关联,为大规模分析全球科研资助格局、检测资助声明错误、追踪经费流向提供了可复用的基准数据集,对推动开放科学基础设施建设和学术出版标准化具有里程碑意义。
以上内容由遇见数据集搜集并总结生成


