HoneyBee
收藏Hugging Face2025-10-22 更新2025-10-22 收录
下载链接:
https://huggingface.co/datasets/facebook/HoneyBee
下载链接
链接失效反馈官方服务:
资源简介:
HoneyBee是一个大规模、高质量的CoT推理数据集,包含大约2.5M个示例,由350K个图像问题对组成。这个数据集是为了研究和提高视觉语言模型在推理任务上的性能而构建的。数据集包括了来自OpenThought3的问题、ViRL的图像和问题,以及Llama-4 Scout生成的Chain-of-Thought解答。
提供机构:
AI at Meta
创建时间:
2025-10-16
原始信息汇总
HoneyBee数据集概述
数据集基本信息
- 许可证: CC-BY-NC-4.0
- 任务类别: 文本生成
- 语言: 英语
- 标签: 推理、视觉语言、数据、LLama4
- 规模: 100万到1000万样本之间
数据集描述
HoneyBee是一个大规模、高质量的思维链推理数据集,包含250万个样本,由35万个图像-问题对组成。该数据集专门用于提升视觉语言模型的推理能力。
数据组成
数据集包含三个组成部分:
- 来自OpenThought3的问题和Llama-4 Scout生成的思维链
- 来自ViRL的图像和问题,以及Llama-4 Scout生成的思维链
- 来自ViRL的图像,以及Llama-4 Scout生成的新问题和思维链
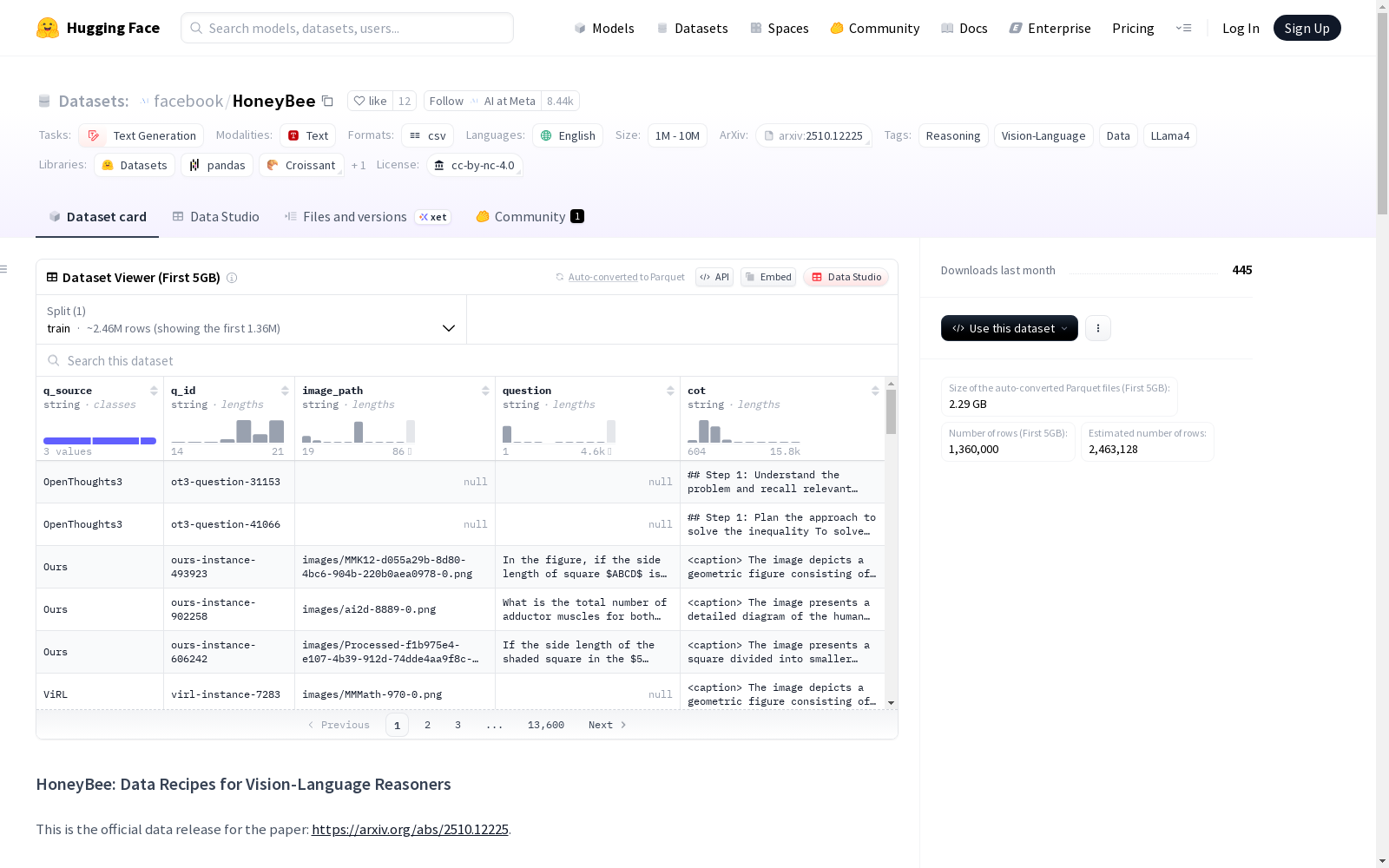
数据字段说明
q_source: 问题来源q_id: 唯一标识符,用于从原始来源填充问题image_path: ViRL数据发布中的图像路径question: 来自OT3、ViRL或Llama-4 Scout生成的问题cot: Llama-4 Scout生成的思维链,包含图像描述(在<caption>标签内)和问题解决方案,最终答案包含在\boxed{}中
性能表现
使用HoneyBee训练的视觉语言模型在不同模型规模上均优于最先进模型。例如:
- 3B参数的HoneyBee训练VLM在MathVerse上比SOTA模型和基础模型分别高出7.8%和24.8%
- 提出的测试时扩展策略可将解码成本降低73%而不牺牲准确性
相关资源
- 论文地址:https://arxiv.org/abs/2510.12225
- GitHub仓库:https://github.com/facebookresearch/HoneyBee_VLM
- ViRL数据集图像下载:https://huggingface.co/datasets/TIGER-Lab/ViRL39K/blob/main/images.zip
- 数据合并脚本:https://huggingface.co/datasets/facebook/HoneyBee/blob/main/full_data.py
许可证信息
数据以CC-BY-NC许可证发布。数据包含Llama 4的输出,受Llama 4许可证约束。使用该数据创建、训练或改进AI模型时,应在模型名称前包含"Llama"。
引用格式
bibtex @article{bansal2025honeybee, title={HoneyBee: Data Recipes for Vision-Language Reasoners}, author={Bansal, Hritik and Sachan, Devandra Singh and Chang, Kai-Wei and Grover, Aditya and Ghosh, Gargi and Yih, Wen-tau and Pasunuru, Ramakanth}, journal={arXiv preprint arXiv:2510.12225}, year={2025} }
搜集汇总
数据集介绍
构建方式
在视觉语言推理领域,HoneyBee数据集的构建采用了多源融合策略,整合了OpenThought3的问题、ViRL数据集的图像及问题,以及Llama-4 Scout生成的链式思维推理内容。通过精心设计的数据干预措施,如引入图像标题作为辅助信号和融入纯文本推理元素,显著提升了数据质量。该数据集包含250万条实例,涵盖35万对图像与问题组合,确保了数据在规模与多样性上的平衡。
特点
HoneyBee数据集以其大规模和高品质的链式思维推理标注脱颖而出,每个实例均包含详细的图像描述与逐步解题过程,答案以标准化格式封装。数据覆盖广泛的视觉语言任务,支持模型在数学推理等多领域性能评估。其独特之处在于通过多维度扩展策略,包括增加每图像的独特问题数量和每问题对的推理路径,有效强化了模型的泛化能力与逻辑一致性。
使用方法
使用HoneyBee数据集时,需先下载ViRL数据集的图像文件,并运行官方提供的Python脚本以整合原始问题与链式思维标注。数据以结构化字段存储,包括问题来源、唯一标识符、图像路径及推理内容,便于直接应用于视觉语言模型的训练与微调。该数据集专为提升模型推理能力设计,可结合论文中的测试时扩展策略,显著降低解码成本而不损失精度。
背景与挑战
背景概述
视觉语言推理作为多模态人工智能的核心研究方向,其发展依赖于高质量数据集的构建。2025年,Meta研究院团队发布了HoneyBee数据集,旨在系统探索视觉语言模型推理能力的训练数据构建原则。该数据集包含250万条链式思维推理样本,覆盖35万组图像-问题对,通过整合OpenThought3、ViRL等权威数据源,并引入Llama-4 Scout生成的推理链,显著提升了模型在数学推理等复杂任务上的表现。该研究揭示了数据维度扩展与干预策略对模型性能的深层影响,为多模态推理研究提供了重要基准。
当前挑战
视觉语言推理领域长期面临数据质量与多样性的双重挑战:传统数据集在问题复杂度与推理深度方面存在局限,难以支撑复杂逻辑推理任务的训练需求。在构建过程中,研究团队需攻克多源数据融合的技术壁垒,包括跨数据集的知识对齐、图像-问题对的语义一致性维护,以及大规模链式思维标注的质量控制。此外,在遵守版权协议的前提下,协调不同数据源的授权许可与分发机制,也成为确保数据集合规性的关键难题。
常用场景
经典使用场景
在视觉语言推理领域,HoneyBee数据集凭借其精心设计的250万条链式思维样本,为多模态模型训练提供了标准化范本。该数据集通过整合图像描述与问题解答的协同机制,显著提升了模型在复杂视觉场景中的逻辑推演能力,尤其在数学推理和科学问答任务中展现出卓越性能。
衍生相关工作
基于HoneyBee的数据构建方法论,研究界衍生出多尺度推理增强技术,如动态思维链蒸馏框架与跨模态注意力优化模型。这些工作进一步拓展了在医疗影像分析、自动驾驶决策等垂直领域的应用深度,形成了以数据质量为驱动的视觉推理研究新范式。
数据集最近研究
最新研究方向
在视觉语言推理领域,HoneyBee数据集通过系统化数据构建策略推动前沿研究。该工作深入探索了上下文来源策略对模型性能的影响,结合图像描述辅助信号与纯文本推理的干预方法,显著提升了视觉语言模型的推理能力。研究进一步揭示了多维度数据扩展的价值,包括每幅图像生成独特问题及每个图像-问题对生成多样化思维链,这种规模化方法使3B参数模型在MathVerse基准上超越现有最优模型7.8%。同时提出的测试时扩展策略在保持精度的前提下将解码成本降低73%,为高效视觉语言推理系统的开发提供了重要范式。
以上内容由遇见数据集搜集并总结生成


