oak
收藏Hugging Face2024-07-14 更新2024-12-12 收录
下载链接:
https://huggingface.co/datasets/tabularisai/oak
下载链接
链接失效反馈官方服务:
资源简介:
Open Artificial Knowledge (OAK) 数据集是一个大规模的合成数据集,包含535,998,787个令牌,旨在为大型语言模型(LLMs)提供高质量、多样化和伦理来源的训练数据。该数据集利用多种先进的LLMs生成跨多个领域的文本,遵循维基百科的主要分类,具有广泛的知识覆盖、保持连贯性和事实准确性,旨在促进更强大和一致的语言模型的发展。
Open Artificial Knowledge (OAK) dataset is a large-scale synthetic dataset containing 535,998,787 tokens, which aims to provide high-quality, diverse, and ethically sourced training data for large language models (LLMs). This dataset leverages multiple advanced LLMs to generate text across multiple domains, adhering to the main classification taxonomy of Wikipedia. It features extensive knowledge coverage, maintains textual coherence and factual accuracy, and is designed to advance the development of more robust and consistent language models.
创建时间:
2024-07-07
原始信息汇总
Open Artificial Knowledge (OAK) Dataset
概述
Open Artificial Knowledge (OAK) 数据集是一个大规模资源,包含超过 5 亿个令牌,旨在解决为大型语言模型 (LLMs) 获取高质量、多样化和伦理上合理的训练数据的挑战。OAK 利用一系列最先进的 LLMs 生成跨多个领域的高质量文本,这些文本由维基百科的主要类别指导。
关键特性
- 535,998,787 个令牌的合成数据
- 使用 GPT4o, LLaMa3-70B, LLaMa3-8B, Mixtral-8x7B, Gemma-7B, 和 Gemma-2-9B 生成
- 广泛的知识覆盖
- 旨在促进更强大和一致的语言模型的发展
数据集创建过程
- 主题提取:从维基百科中提取高级主题。
- 子主题扩展:使用 GPT-4o 等高级语言模型将主题扩展为详细的子主题。
- 提示生成:使用编程提示工程和元提示技术创建提示。
- 文本生成:使用各种开源 LLMs 生成内容。
未来工作
- 增加数据集的容量
- 添加更多语言
- 整合更多先进和多样化的模型
- 改进数据集在代码相关任务中的应用
- 促进社区贡献
引用
bib @misc{borisov2024open, title={Open Artificial Knowledge}, author={Vadim Borisov and Richard H. Schreiber}, year={2024}, eprint={2407.14371}, archivePrefix={arXiv}, primaryClass={cs.CL}, url={https://arxiv.org/abs/2407.14371}, }
免责声明
用户必须遵守伦理指南,尊重隐私考虑,并注意合成数据中可能存在的偏见。OAK 数据集仅用于研究目的。
联系
如有问题或需要更多数据,请联系:info@tabularis.ai
搜集汇总
数据集介绍
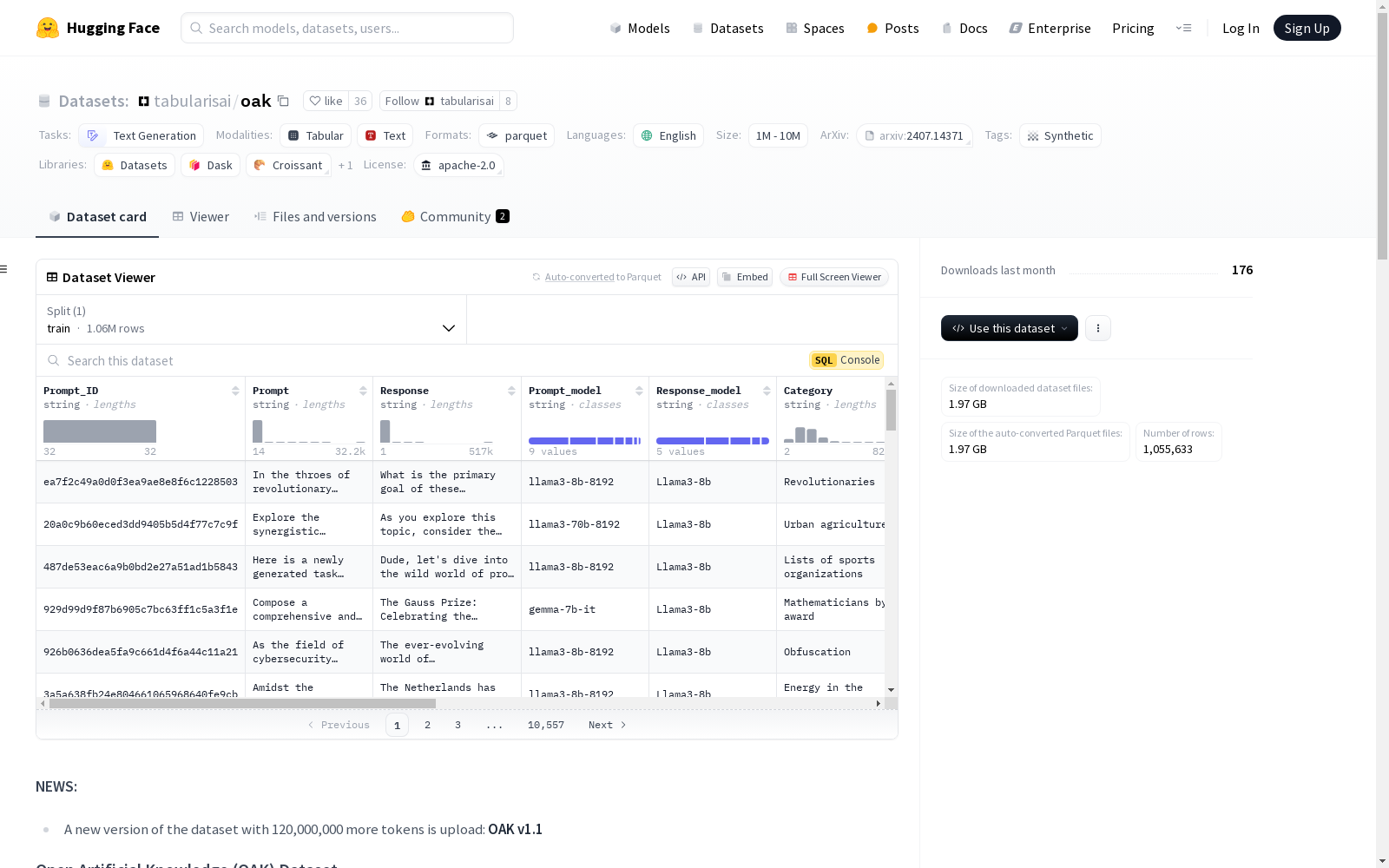
构建方式
OAK数据集的构建过程采用了多阶段的合成数据生成策略。首先,从维基百科中提取高层次的主题,随后利用GPT-4o等先进语言模型将这些主题扩展为详细的子主题。接着,通过编程提示工程和元提示技术生成提示,最后使用多种开源大型语言模型(如GPT4o、LLaMa3-70B等)生成高质量的文本内容。这一过程确保了数据的多样性和高质量。
特点
OAK数据集包含了超过6.53亿个高质量合成令牌,覆盖了广泛的知识领域。数据集通过集成多种先进的语言模型生成,如GPT4o、LLaMa3-70B等,确保了内容的多样性和深度。此外,数据集的设计旨在促进更强大、更对齐的语言模型的发展,特别适用于文本生成任务。
使用方法
OAK数据集的使用方法简便,用户可以通过Hugging Face的`datasets`库直接加载数据集。使用`load_dataset`函数并指定数据集名称和分割(如`train`),即可轻松访问数据集中的内容。数据集的结构清晰,包含多个特征字段,如`Prompt_ID`、`Prompt`、`Response`等,便于用户进行进一步的分析和应用。
背景与挑战
背景概述
Open Artificial Knowledge (OAK) 数据集由Vadim Borisov和Richard H. Schreiber于2024年创建,旨在为大语言模型(LLMs)提供高质量、多样化且符合伦理的合成训练数据。该数据集通过整合GPT4o、LLaMa3-70B、LLaMa3-8B、Mixtral-8x7B、Gemma-7B和Gemma-2-9B等先进模型,生成了超过6.5亿个标记的文本,覆盖广泛的领域知识。OAK的构建过程包括主题提取、子主题扩展、提示生成和文本生成等步骤,其目标是为开发更强大且对齐的语言模型提供支持。该数据集在自然语言处理领域具有重要影响力,特别是在提升模型生成能力和知识覆盖范围方面。
当前挑战
OAK数据集在构建过程中面临多重挑战。首先,生成高质量且多样化的合成数据需要平衡模型的多样性与生成内容的一致性,这对模型选择和提示工程提出了较高要求。其次,确保数据的伦理性和避免偏见是另一大挑战,尤其是在涉及敏感话题时。此外,数据集的规模扩展和多语言支持也增加了技术复杂性,特别是在保持数据质量的同时实现高效生成。最后,如何将数据集有效应用于代码相关任务,仍需进一步探索和优化。这些挑战不仅影响了数据集的构建过程,也对其在研究和应用中的广泛使用提出了更高的要求。
常用场景
经典使用场景
OAK数据集在自然语言处理领域中被广泛应用于训练和评估大规模语言模型(LLMs)。其高质量、多样化的合成数据为模型提供了丰富的知识覆盖,特别是在文本生成任务中,OAK数据集能够帮助模型生成更加连贯、多样且符合上下文的文本。通过使用多个先进的LLMs生成数据,OAK确保了数据的多样性和质量,使其成为研究者和开发者在模型训练中的理想选择。
实际应用
在实际应用中,OAK数据集被广泛用于开发智能助手、自动文本生成系统和知识问答系统。其多样化的数据来源和高质量的内容使得这些系统能够更好地理解和生成自然语言,从而提升用户体验。例如,在智能客服领域,OAK数据集可以帮助模型生成更加自然和准确的回复,减少人工干预的需求。此外,OAK数据集还被用于教育领域,帮助开发智能教学系统,提供个性化的学习内容。
衍生相关工作
OAK数据集的发布催生了一系列相关研究和工作。例如,基于OAK数据集的研究者开发了更加高效和准确的文本生成模型,这些模型在多个自然语言处理任务中取得了显著的性能提升。此外,OAK数据集还被用于研究模型对齐和伦理问题,推动了语言模型在生成内容时的安全性和可控性研究。这些工作不仅扩展了OAK数据集的应用范围,还为其未来的改进和扩展提供了宝贵的经验。
以上内容由遇见数据集搜集并总结生成


