Usenet-Corpus-1980-2013
收藏Hugging Face2026-04-24 更新2026-04-25 收录
下载链接:
https://huggingface.co/datasets/OwnedByDanes/Usenet-Corpus-1980-2013
下载链接
链接失效反馈官方服务:
资源简介:
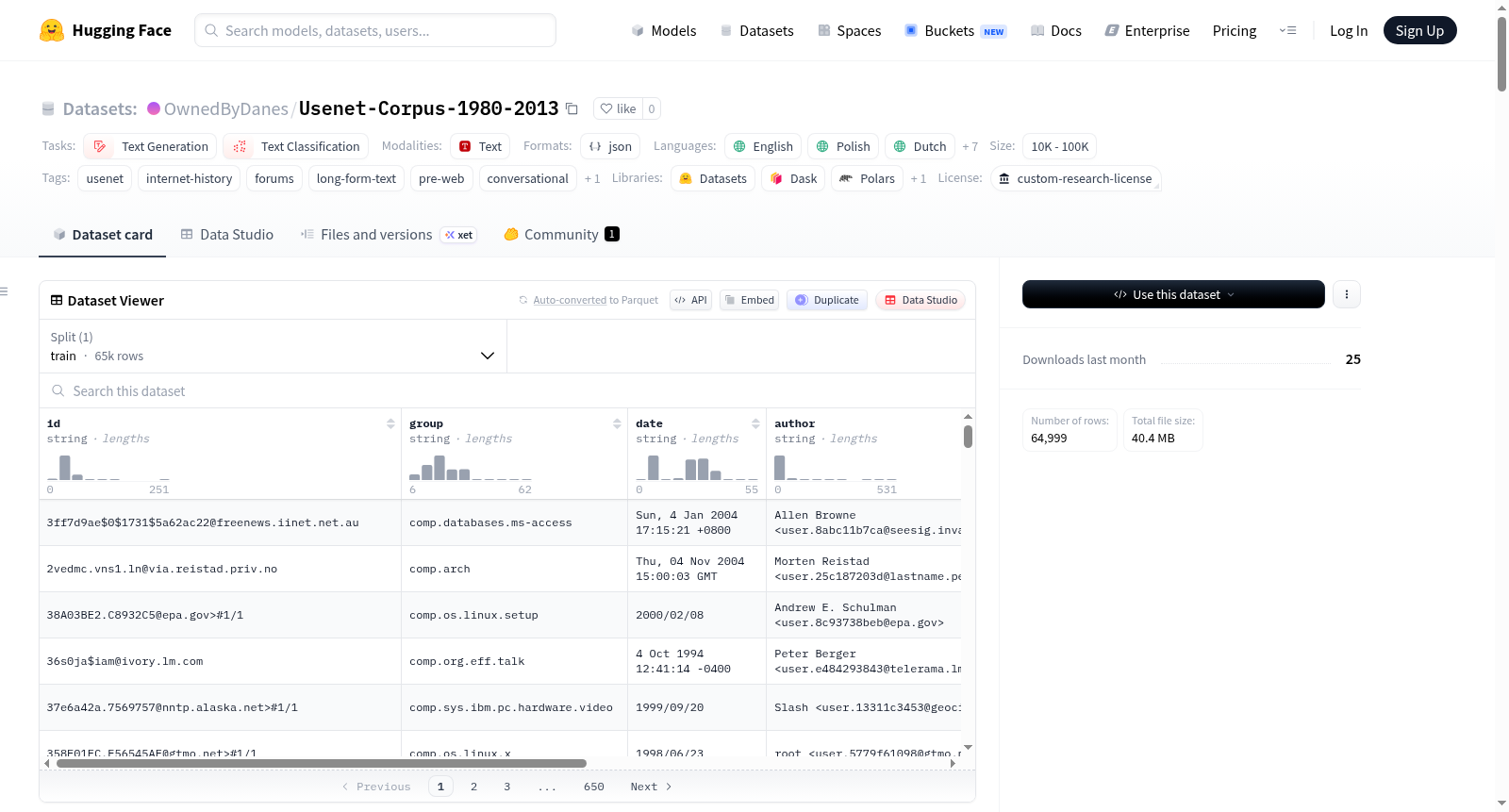
Usenet Corpus 1980–2013 是一个大型的去重和清理过的 Usenet 帖子数据集,涵盖了从1980年到2013年的内容。数据集包含来自数千个新闻组的帖子,覆盖了几乎所有主要层级(如 `talk.*`、`sci.*`、`comp.*` 等),记录了社交媒体前互联网讨论的完整历程。数据集总共有1031亿个标记,408,236,288条记录,18,347个新闻组。数据以JSONL格式存储,经过gzip压缩,压缩后大小约为141GB。数据集主要用于语言模型预训练、领域适应、语言学研究以及检索和搜索系统开发。数据集经过严格的清理过程,包括去重、二进制内容移除、个人身份信息(PII)脱敏等。数据集访问受限,需申请许可,适用于学术和非商业研究,商业AI训练需额外许可。
The Usenet Corpus 1980–2013 is a large-scale deduplicated and cleaned dataset of Usenet posts, covering content from 1980 to 2013. The dataset includes posts from thousands of newsgroups, spanning nearly all major hierarchies (e.g., `talk.*`, `sci.*`, `comp.*`, etc.), documenting the complete history of pre-social media internet discussions. The dataset contains a total of 103.1 billion tokens, 408,236,288 records, and 18,347 newsgroups. The data is stored in JSONL format, compressed with gzip, and the compressed size is approximately 141GB. The dataset is primarily used for language model pre-training, domain adaptation, linguistic research, and the development of retrieval and search systems. The dataset has undergone rigorous cleaning processes, including deduplication, removal of binary content, and anonymization of personally identifiable information (PII). Access to the dataset is restricted and requires permission, suitable for academic and non-commercial research, with additional licensing required for commercial AI training.
创建时间:
2026-04-16
原始信息汇总
Usenet Corpus 1980–2013 数据集概述
基本信息
- 数据集名称:Usenet Corpus 1980–2013
- 许可证:自定义研究和商业许可证(需要申请才能访问)
- 任务类型:文本生成、文本分类、问答
- 主要语言:英语(96.6%),另包含100多种语言
- 数据集规模:100B - 1T tokens
- 数据格式:JSONL,gzip压缩(
.jsonl.gz)
数据集规模统计
| 指标 | 数值 |
|---|---|
| 总Token数 | 103,104,873,384(103.1B,cl100k_base) |
| 总记录数 | 408,236,288 |
| 新闻组数量 | 18,347 |
| 时间范围 | 1980 – 2013 |
| 压缩后大小 | ~141 GB |
数据集特点
- 纯人类生成内容:所有帖子均来自LLM时代之前,无AI污染
- 时间跨度长:超过30年的连续对话记录,可追踪语言、文化、技术术语和社会规范的演变
- 主题广泛:涵盖从天体物理到宗教哲学、Unix系统管理到食谱交换等数千个领域
- 对话结构丰富:线程化讨论、回复和辩论提供了多轮推理、论证和澄清的丰富样例
- 人口多样性:从早期学术和技术用户到1990年代全球英语用户
新闻组层级结构
| 层级 | 记录数 | 新闻组数 | Token数 | 平均Token/帖 | 英语占比 |
|---|---|---|---|---|---|
alt.* |
228,761,734 | 15,288 | 58.8B | 257 | 95.8% |
rec.* |
77,233,777 | 919 | 16.5B | 214 | 99.7% |
comp.* |
49,990,816 | 1,205 | 10.3B | 206 | 99.7% |
soc.* |
22,386,509 | 341 | 8.2B | 367 | 82.8% |
sci.* |
11,996,714 | 237 | 3.3B | 276 | 99.4% |
misc.* |
10,866,446 | 242 | 2.7B | 249 | 99.7% |
news.* |
2,065,102 | 60 | 1.7B | 828 | 98.8% |
talk.* |
4,308,542 | 47 | 1.3B | 313 | 99.1% |
humanities.* |
626,648 | 8 | 0.2B | 352 | 99.6% |
| 总计 | 408,236,288 | 18,347 | 103.1B | 253 | 96.6% |
语言分布
| 语言 | 记录数 | 占比 |
|---|---|---|
| 英语 | 394,350,819 | 96.60% |
| 波兰语 | 3,719,737 | 0.91% |
| 荷兰语 | 2,596,453 | 0.64% |
| 西班牙语 | 2,124,609 | 0.52% |
| 法语 | 1,669,450 | 0.41% |
| 意大利语 | 743,411 | 0.18% |
| 德语 | 638,250 | 0.16% |
| 俄语 | 366,240 | 0.09% |
| 日语 | 268,684 | 0.07% |
| 其他80+语言 | ~200,000 | <0.01%(每种) |
数据模式
每条记录为一个JSON对象,包含以下字段:
| 字段 | 类型 | 描述 |
|---|---|---|
text |
string | 完整帖子正文,邮箱地址替换为[email] |
group |
string | 新闻组名称(如comp.lang.python) |
date |
string | 帖子日期,ISO 8601格式 |
subject |
string | 主题行 |
author |
string | 显示名称,邮箱地址已移除或替换为[redacted] |
id |
string | 匿名化Message-ID(SHA-256哈希为msg-<hex32>) |
数据清洗流程
第一阶段——层级排除
- 移除
alt.binaries.*层级(UU编码/Base64二进制附件) - 移除成人内容新闻组
第二阶段——记录级清洗
- 去重:移除相同Message-ID的帖子
- 二进制移除:删除包含UUencode或Base64二进制的帖子
- PII脱敏:作者字段中移除邮箱地址,正文中邮箱地址替换为
[email] - Message-ID匿名化:SHA-256哈希处理
- 敏感内容移除:删除包含SSN、信用卡号、护照号等的帖子
- 引用文本保留:保留Usenet回复引用(
>前缀行)
清洗结果
| 层级 | 输入记录数 | 输出记录数 | 丢弃数 | 丢弃率 |
|---|---|---|---|---|
alt.* |
229,089,954 | 228,761,734 | 328,220 | 0.143% |
| 其他层级 | 179,597,324 | 179,474,554 | 122,770 | 0.068% |
| 总计 | 408,687,278 | 408,236,288 | 450,990 | 0.110% |
验证结果
- 15,139/15,288个文件(99%)完全清洁,零邮箱或PII违规
预期用途
适用场景
- 大语言模型的预训练和持续预训练
- 面向对话、技术或历史互联网文本的领域自适应
- 英语在互联网时代演变的语言学研究
- 基于历史文本的检索和搜索系统开发
禁止用途
- 重新识别个人身份或重建联系信息
- 对帖子中提到的人员进行自动画像或定位
- 用于生成垃圾邮件、骚扰或虚假信息
访问与许可
- 访问需申请:需获得批准后才能下载
- 学术和非商业研究:经批准后可免费使用
- 商业AI训练:需联系所有方讨论许可条款
- 禁止未经书面同意重新分发或转授权原始数据
引用格式
@dataset{usenet_corpus_1980_2013, author = {OwnedByDanes}, title = {Usenet Corpus 1980–2013}, year = {2025}, publisher = {HuggingFace}, url = {https://huggingface.co/datasets/OwnedByDanes/Usenet-Corpus-1980-2013} }
搜集汇总
数据集介绍
构建方式
Usenet-Corpus-1980-2013的构建基于一个规模庞大的私有Usenet存档,覆盖了1980年至2013年间超过18,000个新闻组。数据处理遵循两阶段清洗流水线:第一阶段在层级层面排除了alt.binaries.*及成人内容新闻组,移除了绝大部分二进制和不当内容;第二阶段对每条记录执行去重、二进制识别与删除、敏感内容过滤,并对个人可识别信息(如电子邮件地址和消息ID)进行了脱敏处理。最终获得了超过4.08亿条记录,总计约1,031亿个token,数据以gzip压缩的JSONL格式存储,确保了内容的高质量与可用性。
特点
该数据集的核心特点在于其历史深度与内容多样性。语料完全生成于大语言模型时代之前,确保了纯粹的人类文本,无AI污染,为研究语言、文化及技术术语在三十余年间的演变提供了独一无二的纵向资料。涵盖了从astrophysics到Unix系统管理的广泛话题,自然形成了数以千计的主题结构。尤为珍贵的是其对话式结构,通过线程化讨论、回复与辩论,为多轮推理与论证提供了丰富范例。语种以英语为主,同时覆盖超过100种语言,展现了早期互联网用户群体的多元化面貌。
使用方法
该数据集适用于多种自然语言处理任务。在模型预训练或持续预训练中,可用于增强模型对对话、技术及历史互联网文本的理解能力。支持文本生成、文本分类及问答等任务,其结构性字段(如新闻组、日期、主题、作者)使得对语料进行精细筛选成为可能。使用者可依据新闻组层级(如sci.*、comp.*)进行子集提取,也可根据日期范围或语言进行二次过滤。此外,保留的引用文本(>前缀行)为研究者提供了对话上下文,而按需求移除引用文本亦简单可行。数据访问需通过门控申请,学术与非商业研究用途在许可范围内。
背景与挑战
背景概述
Usenet-Corpus-1980-2013是一个由研究者OwnedByDanes于2025年发布的、经精心清洗的大型Usenet语料库,收录了1980年至2013年间超过408亿条帖子,总计约1031亿Token,覆盖18,347个新闻组。该数据集源自私人珍藏的Usenet存档,系统性地捕捉了社交媒体时代之前互联网话语的完整演变轨迹——从1980年代早期的学术与技术讨论,到1990年代与2000年代Usenet的消费黄金期。作为目前公开可获取的最大规模人工生成文本语料之一,它对自然语言处理领域产生了深远影响,为语言模型预训练、对话系统开发以及互联网语言历时研究提供了无法替代的数据基础,同时也为探究技术术语、社会规范与文化的长期演化开辟了新途径。
当前挑战
该数据集所解决的核心领域问题在于,现有大规模文本语料多被AI生成内容污染,或缺乏覆盖数十年的结构性对话数据,而Usenet独有的前网络时代、人类创作特性恰好填补了这一空白。然而,构建过程面临多重挑战:首先,原始Usenet数据中充斥着大量二进制编码附件(如UUencode与base64),需要设计全新的层级过滤与记录级检测管线来剔除噪声;其次,隐私保护要求极高,必须通过哈希匿名化Message-ID、全覆盖正则替换脱敏电子邮件地址、移除敏感内容(如社会安全号码与信用卡号)等手段确保合规;此外,跨年代、跨主题的复杂引用结构(如>前缀回复)以及超100种语言的混杂状态,进一步增加了清洗与验证的难度,最终实现了仅0.11%的丢弃率与99%文件的零隐私泄露验证通过率。
常用场景
经典使用场景
Usenet-Corpus-1980-2013作为横跨三十余年互联网历史的巨型语料库,其最经典的使用场景在于大规模语言模型的预训练与持续预训练。该数据集收录了1980年至2013年间来自超过一万八千个新闻组的四亿余条帖子,涵盖了从早期学术讨论到消费级互联网巅峰时期的多元对话形式。研究者可借助这一浩如烟海的人类自然语言文本,为模型注入跨越时代的语言演变轨迹、社会文化变迁脉络以及技术术语的更迭历程,从而夯实语言模型对历史语境的深刻理解能力。
实际应用
在实际应用层面,该数据集展现出多元而深刻的价值。技术企业可将其用于领域自适应训练,使语言模型更好地理解技术讨论、学术争辩及历史互联网文化语境,从而提升在问答系统、技术支持对话及历史文本分析等场景中的表现。图书馆与数字人文机构能够借助该语料构建面向互联网历史的检索与知识挖掘工具,帮助研究者回溯特定议题在数十年间的讨论脉络。此外,安全与内容审核领域的从业者可运用其中的对话范例来训练辩论检测与论证结构识别系统,赋能信息治理与言论分析实践。
衍生相关工作
基于Usenet-Corpus-1980-2013,学界已催生了一系列富有影响力的衍生工作。研究者利用其时间戳属性构建了时间敏感型语言模型,实现了对特定历史时期语言风格的动态捕捉与建模。新闻组类别的层级结构激发了面向对话主题分类与层次化事理图谱构建的研究,使得自动归纳科技、人文、娱乐等领域的知识演化成为可能。该数据集还驱动了长篇对话生成、多轮推理能力评估以及跨年代语用分析等方向的前沿探索,为后续基于历史互联网语料的语言学研究与技术开发提供了先行范式与可复现的基准。
以上内容由遇见数据集搜集并总结生成


