OpenMedical/m1-medbench
收藏Hugging Face2025-03-13 更新2025-04-12 收录
下载链接:
https://hf-mirror.com/datasets/OpenMedical/m1-medbench
下载链接
链接失效反馈官方服务:
资源简介:
这是一个医学问题数据集,包含了由原始医学选择题扩展而来的多种类型的问题。每个问题都有正确的选项和答案,并且标注了问题的类型、难度以及所属的医学领域。
This is a medical question dataset that includes various types of questions expanded from original medical multiple-choice questions (MCQs). Each question has a correct option and answer, and is labeled with the type of question, difficulty level, and medical domain.
提供机构:
OpenMedical
搜集汇总
数据集介绍
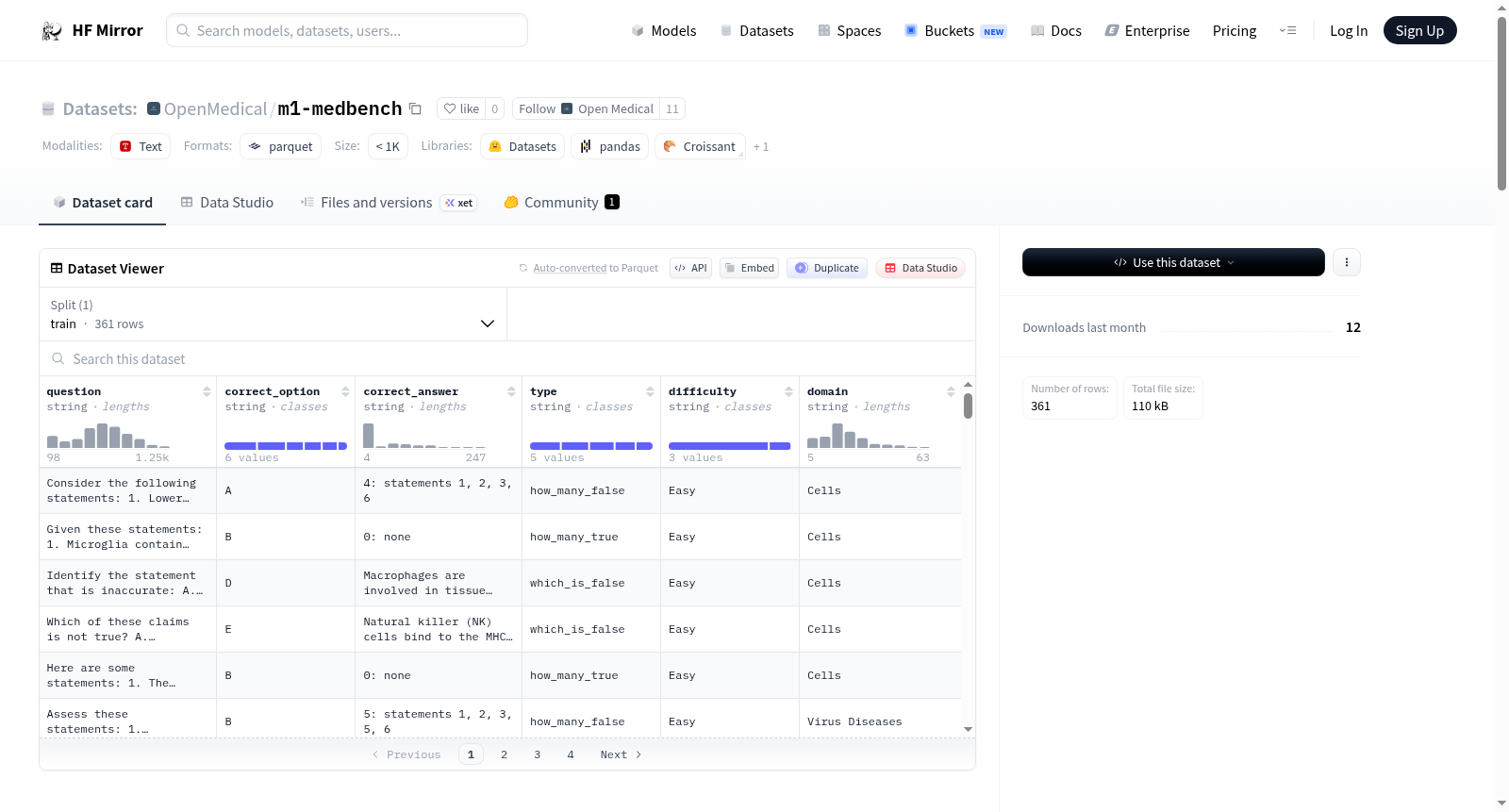
构建方式
该数据集以OpenMedical/medical-data中的医学多选题为原始素材,这些题目源自MedQA、MedMCQA、Med-HALT、MedBullets、MedExQA等多个权威医学考试资源。构建过程首先利用Qwen 2.5 Instruct 72B模型为每道题目生成MeSH分类标签,以标准化医学内容索引。随后进行严格筛选,仅保留单字母正确答案的题目,剔除“全选”类、临床案例描述类及长度超过350字符的题目。核心转换步骤是将每道选择题拆解为独立的陈述句,即题干与各选项组合,并标注正确与否。接着,借助同一语言模型将组合语句改写为清晰、自然的医学表述。最终,依据原始题目和医学领域对陈述进行分组,生成多样化的题目类型,包括判断真伪、识别正确或错误陈述、以及统计正确或错误陈述数量等,从而构建出结构化且富有挑战性的医学问答数据集。
特点
该数据集最显著的特点在于其独特的题目生成机制,将传统选择题转化为多种高阶推理题型,如“多少为真”、“哪个为假”等,有效评估对医学知识的深层理解而非简单记忆。数据集保留了原始题目的难度等级和医学领域标签,便于进行分层评估和领域特异性分析。所有题目均经过MeSH分类,增强了在特定医学子领域中的检索与应用价值。通过严格的过滤条件,数据集确保了高质量与一致性,仅包含单答案、非临床案例的题目,并统一了表述风格。此外,数据集规模适中,训练集包含361个样本,覆盖多个医学学科,为中等规模模型微调和基准测试提供了理想平衡。
使用方法
该数据集可直接通过Hugging Face的datasets库加载,默认配置为'train'分割,无需额外预处理。用户可通过dataset['train']访问数据,每条记录包含'question'(题目文本)、'correct_option'(正确选项字母)、'correct_answer'(正确选项内容)、'type'(题目类型)、'difficulty'(难度)和'domain'(医学领域)字段。适用于医学语言模型的评估与微调,尤其适合检验模型在真伪判断、多项选择推理等复杂任务上的能力。研究者可根据'type'字段筛选特定题型进行针对性测试,或按'domain'字段聚焦于某一医学领域。由于题目已转换为陈述式,也可直接用于文本蕴含或事实性判断任务的训练与评估。
背景与挑战
背景概述
在医学人工智能领域,高质量基准数据集是评估大语言模型临床知识掌握程度的核心工具。OpenMedical/m1-medbench数据集由国际开放医学社区于2023年创建,旨在通过多源医学多选题构建标准化评测体系。该数据集整合了MedQA、MedMCQA、Med-HALT等知名来源,覆盖内科学、外科学、药理学等核心临床学科,其独特之处在于将传统单选题转化为真值判断、数量推理等多样化题型。借助Qwen 2.5 Instruct 72B大模型进行MeSH分类与语义改写,该数据集不仅提升了内容组织规范性,更推动了医学自然语言处理从简单问答向复杂推理评估的范式转变,成为检验大模型医学素养的重要标尺。
当前挑战
当前数据集面临的核心挑战集中于知识边界界定与评估公平性。首先,医学领域的专业术语歧义性导致模型难以区分相似症状或治疗方案,例如心绞痛与心肌梗死的鉴别诊断需要高度临床推理能力。其次,构建过程中对原始多选题的过滤标准(如剔除含‘select all that apply’的题目)可能损失部分高阶认知评估维度,而基于大模型生成的改写语句存在潜在语义漂移风险。此外,不同医学考试来源的难度标定不一致(如美国执业医师考试与中国医学考试),使得跨地域通用性受限。最后,真值判断类题型的选项随机组合可能引入逻辑陷阱,需警惕模型通过统计模式而非真实医学知识作答的隐患。
常用场景
经典使用场景
M1-MedBench数据集的核心经典应用场景在于评估和提升大型语言模型在医学领域的知识掌握与推理能力。通过将传统的医学多项选择题(MCQ)转化为多样化的问答形式,如“多少为真”、“哪个为假”及“对或错”等,该数据集为模型提供了超越简单选项匹配的挑战。研究者常利用此数据集对预训练模型进行微调,以增强其在临床知识、病理机制、药理学等细分医学领域的理解力,从而检验模型能否像医学生一样,在复杂医学陈述中精确辨别真伪。这一过程不仅要求模型具备广泛的术语记忆,更需具备逻辑推断与语义整合的深层能力。
实际应用
实际应用中,M1-MedBench可被部署于智能医学教育辅助系统与临床决策支持工具的底层验证环节。例如,在医学生自主复习场景下,该数据集可驱动生成式AI生成动态、多变的医学知识测验,帮助学生从不同角度巩固对疾病诊断、治疗方案的理解。此外,在临床辅助系统中,经过此数据集微调的模型能够更可靠地筛选电子病历中的矛盾陈述或核实用药指导的准确性,降低因信息误读导致的医疗风险。其多样化的题型设计,使得模型在应对实际医疗咨询中非结构化、多义性的问题时,展现出更强的鲁棒性与适应性。
衍生相关工作
该数据集的诞生已衍生出一系列富有启发性的经典工作。一方面,研究者基于其陈述改写的思路,开发出更为细粒度的医学知识图谱构建方法,利用模型生成的“真/假”陈述对来补全实体关系。另一方面,M1-MedBench的“多少为真”与“哪个为假”题型设计,启发了针对模型置信度校准的研究,催生了如MedConformal等旨在提升医学预测可靠性的系列工作。此外,其MeSH分类与难度标签的结合,被后续工作用于探索不同医学子领域对模型能力的差异化要求,推动了如MedPrompt等面向特定科室的提示工程范式的出现,进一步丰富了医学大模型评估与优化的生态。
以上内容由遇见数据集搜集并总结生成


