all_data.csv
收藏github2025-03-08 更新2025-03-08 收录
下载链接:
https://github.com/amr-mohamedd/LLM-as-a-Broken-Telephone
下载链接
链接失效反馈官方服务:
资源简介:
用于实验的数据集,包含了实验所需的所有数据。
This experimental dataset includes all the data required for the experiments.
创建时间:
2025-02-28
原始信息汇总
LLM as a Broken Telephone: Iterative Generation Distorts Information
数据集概述
-
数据集名称:LLM as a Broken Telephone
-
数据集描述:此数据集用于研究大语言模型(LLM)在迭代处理任务(如翻译和改写)时如何扭曲信息,模拟了“电话游戏”中信息通过重复传递逐渐失真的效果。
-
数据集结构:
Datasets/:包含用于实验的数据集和FActScore的知识源。Results/:存储实验结果、推理输出和可视化。Scripts/:包含运行实验、评估结果和生成可视化的Python脚本。requirements.txt:列出运行代码所需的Python包。
-
数据集内容:
all_data.csv:包含实验所需的全部数据。
-
实验模型:代码设计为使用Hugging Face Transformers模型,包括Llama-3.1-8B-Instruct、Mistral-7B-Instruct-v0.2和Gemma-2-9B-it。
-
实验流程:
- 配置
config.py:设置实验参数,如num_translations、default_file_path和hf_auth_token。 - 运行
translate.py:执行迭代生成。 - 评估结果:使用
Scripts/Evaluation/full_eval/中的脚本计算评估指标(BLEU、ROUGE、CHR-F、METEOR、BERTScore、FActScore)。 - 可视化结果:使用
Scripts/Visualization/中的脚本生成与论文中类似的图表。
- 配置
-
示例代码:
- Bilingual Self-loop:使用Llama-3在news2024数据集上执行英语到法语再回到英语的翻译。
- Bilingual Two-player:使用Llama-3和Mistral在booksum数据集上执行英语到法语再回到英语的翻译。
- Multilingual Multiplayer:使用Llama-3、Mistral和Gemma在scriptbase数据集上从英语翻译到法语、德语、泰语和中文,再回到英语。
-
引用信息:
@article{mohamed2025llm, title={LLM as a Broken Telephone: Iterative Generation Distorts Information}, author={Mohamed, Amr and Geng, Mingmeng and Vazirgiannis, Michalis and Shang, Guokan}, journal={arXiv preprint arXiv:2502.20258}, year={2025} }
搜集汇总
数据集介绍
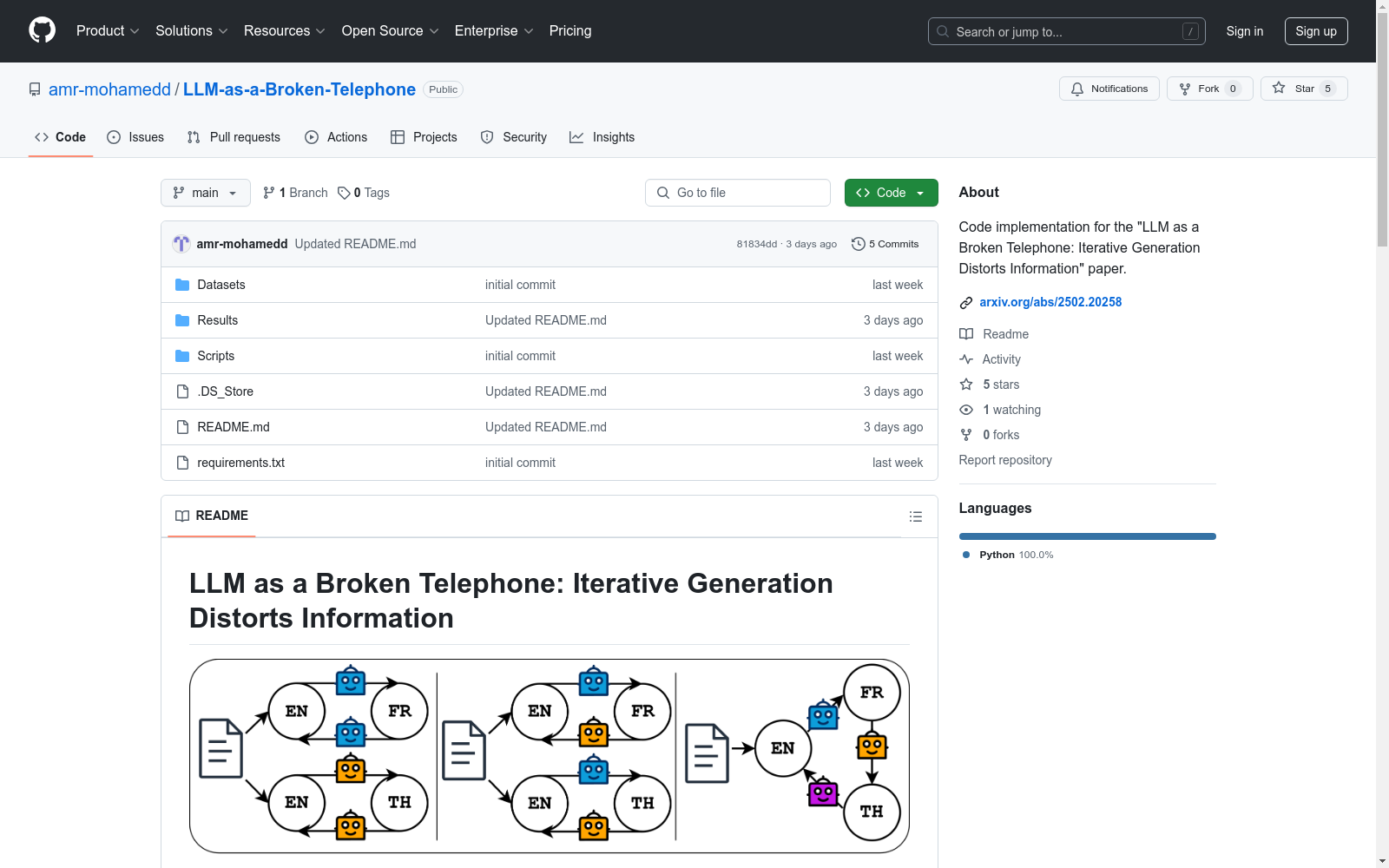
构建方式
该数据集的构建围绕大型语言模型在迭代处理任务中的信息扭曲现象,通过模拟不同复杂度的机器翻译链和改写任务,收集了翻译过程中的输出数据。数据集包含了多种语言之间的翻译数据,以及用于评估真实性的知识来源,构建过程中运用了BLEU、ROUGE、CHR-F、METEOR、BERTScore等文本相关性指标,以及FActScore事实性评估指标,以确保数据的多样性和评估的全面性。
特点
数据集的特点在于其模拟了迭代生成过程中的信息扭曲现象,包含了多种语言对之间的翻译数据,支持了不同模型的评估和对比。此外,数据集的结构化设计使得研究者能够方便地选取子集进行各种实验,其评估指标全面,涵盖了文本相关性和事实性两方面的评估,为深入研究大型语言模型在迭代任务中的表现提供了重要基础。
使用方法
使用该数据集时,研究者首先需要克隆仓库并安装所需的依赖项,包括PyTorch和Hugging Face Transformers等。然后,根据实验需求在`config.py`中配置实验参数,如翻译次数、数据文件路径和HuggingFace API密钥等。之后,执行`translate.py`脚本来执行迭代生成任务,并使用`Scripts/Evaluation/full_eval/`目录下的脚本计算评估指标。最后,可以通过`Scripts/Visualization/`中的脚本生成实验结果的可视化图形。
背景与挑战
背景概述
该数据集名为all_data.csv,是伴随论文“LLM as a Broken Telephone: Iterative Generation Distorts Information”的研究项目所使用的代码与数据集。该研究由Amr Mohamed、Mingmeng Geng、Michalis Vazirgiannis和Guokan Shang等研究人员开展,旨在探讨大型语言模型(LLM)在迭代处理任务如翻译和改写时,如何引入并累积错误,从而导致原始输入信息的意义和事实准确性的逐渐偏离。此数据集及相关研究对理解LLM在迭代处理中的信息扭曲现象具有重要价值,为后续研究提供了基础。
当前挑战
数据集面临的核心挑战包括:如何在迭代翻译和改写任务中,准确量化大型语言模型引入的错误及其对原始信息的影响。构建过程中,研究团队需要解决的技术挑战包括:1)设计有效的实验来模拟“破损电话”效应;2)采用多种文本相关性指标和事实性评估方法,以全面衡量信息扭曲的程度;3)确保实验的可重复性,提供详尽的代码和配置说明。
常用场景
经典使用场景
该数据集主要被用于研究大型语言模型(LLM)在迭代处理任务,如翻译和改写时,如何扭曲信息。其经典使用场景在于模拟并量化了LLM在处理自身输出时的累积误差,以及这种误差如何导致原始输入意义和事实准确性的逐渐偏差。
实际应用
在实际应用中,该数据集可以帮助开发者评估和改进LLM模型在迭代任务中的性能,从而提高翻译、改写等任务的准确性和稳定性。这对于需要高精度翻译服务的行业,如国际事务、外交交流、多语言内容管理等,具有显著的实际价值。
衍生相关工作
该数据集催生了一系列相关研究工作,如对不同LLM模型的比较研究,迭代生成过程中的错误分析,以及针对特定语言对的优化策略等。这些研究进一步扩展了该数据集的应用范围,并推动了LLM领域的发展。
以上内容由遇见数据集搜集并总结生成


