PixLore
收藏arXiv2023-12-09 更新2024-06-21 收录
下载链接:
https://diegobonilla98.github.io/PixLore/
下载链接
链接失效反馈官方服务:
资源简介:
PixLore数据集是由高知特瓦伦西亚的研究人员Diego Bonilla Salvador创建,包含100,000张来自COCO数据集的图像。该数据集通过结合多种计算机视觉模型和ChatGPT的增强,生成了详细且丰富的图像描述。创建过程中,每张图像都经过多个先进的计算机视觉模型的处理,最终通过ChatGPT生成文本描述。PixLore数据集主要用于图像描述任务,旨在通过小规模模型实现复杂的图像理解,解决现有模型在描述细节和上下文方面的不足。
The PixLore dataset was created by researcher Diego Bonilla Salvador from Cognizant Valencia, and includes 100,000 images sourced from the COCO dataset. It generates detailed and rich image captions by integrating multiple computer vision models with ChatGPT-powered enhancements. During its development, each image was processed by several state-of-the-art computer vision models, before final textual descriptions were generated via ChatGPT. Primarily intended for image captioning tasks, the PixLore dataset aims to enable complex image understanding using small-scale models, and addresses the limitations of existing models in describing image details and contextual information.
提供机构:
高知特瓦伦西亚
创建时间:
2023-12-09
搜集汇总
数据集介绍
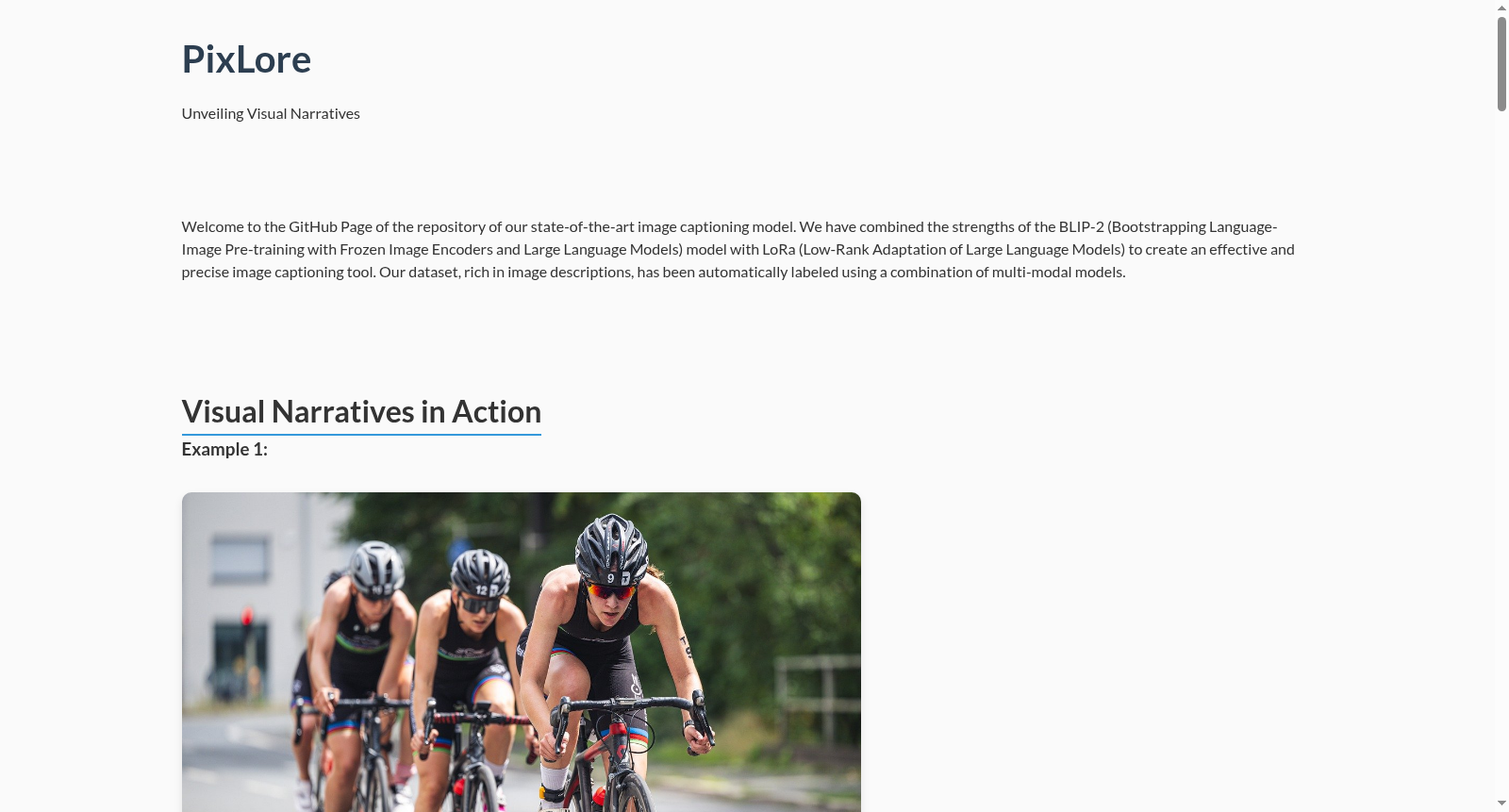
构建方式
在视觉语言融合领域,PixLore数据集的构建采用了多模型协同的集成策略。该数据集从COCO数据集中随机选取十万张图像作为基础素材,每张图像均经过一系列前沿计算机视觉模型的系统处理,包括DETR、Recognize Anything、OwLViT、Tag2Text及BLIP-2。这些模型分别执行物体检测、图像标注、开放词汇检测及描述生成等任务,其输出被统一转换为文本字符串。随后,通过精心设计的提示模板,利用ChatGPT对这些多源文本信息进行融合与增强,生成蕴含丰富细节和上下文语义的段落式描述,从而构建出一个兼具广度与深度的图像描述数据集。
特点
PixLore数据集的核心特点在于其描述文本的丰富性与生成过程的创新性。区别于传统图像描述数据集通常提供的简短句子,PixLore为每张图像生成了详尽、连贯的段落式描述,在细节刻画和语境渲染上更接近人类语言风格。其构建过程本质上是将多种计算机视觉模型的专长输出,通过大型语言模型的强大整合与语言生成能力进行间接知识蒸馏,形成了一种数据驱动的增强范式。这使得数据集不仅包含了基础的视觉元素识别,还融入了对场景氛围、物体关系及潜在叙事的深度解读,为训练模型生成更具表现力和信息量的描述提供了高质量素材。
使用方法
PixLore数据集主要用于微调视觉语言模型以提升其生成丰富图像描述的能力。具体而言,研究团队以BLIP-2模型为基础架构,采用参数高效的LoRa方法,在标准商用GPU上对模型进行了微调。在微调过程中,模型利用PixLore数据集中图像与其对应增强描述进行训练,学习将视觉特征映射到更为复杂和细致的文本序列。经过微调的模型——PixLore-2.7B,能够接收图像输入并直接生成类似数据集中风格的详细段落描述。该数据集及其衍生的模型为图像描述研究提供了一个新的基准,展示了通过精心策划的数据集,即使参数量较小的模型也能在描述丰富性上取得竞争力的表现。
背景与挑战
背景概述
在视觉与语言融合的研究领域,生成富含细节的图像描述长期以来面临高质量标注数据稀缺的挑战。PixLore数据集由Diego Bonilla Salvador及其团队于2023年提出,旨在通过精心构建的数据驱动方法,探索如何利用较小规模模型实现复杂的图像理解。该数据集基于COCO图像库,通过集成多种前沿计算机视觉模型的输出,并借助ChatGPT进行文本合成,生成了十万张图像对应的丰富描述段落。PixLore不仅推动了图像描述生成技术的发展,更凸显了优质数据集在提升轻量模型性能中的关键作用,为后续多模态研究提供了重要的数据基础。
当前挑战
PixLore致力于解决图像描述生成任务中模型对细节与上下文把握不足的挑战,尤其在生成人类化、语境恰当且详尽的描述方面存在显著难度。构建过程中的挑战主要体现在多模型输出融合的复杂性上,需协调目标检测、图像标注与描述生成等异构模型的输出,并将其转化为连贯的文本表示。此外,依赖ChatGPT进行文本合成时,需设计有效的提示策略以确保生成描述的准确性与丰富性,同时避免引入偏差或冗余信息,这对数据集的质控与一致性提出了较高要求。
常用场景
经典使用场景
在视觉-语言融合领域,PixLore数据集通过整合多种先进计算机视觉模型的输出,并借助ChatGPT生成丰富细致的图像描述,为图像字幕生成任务提供了高质量的标注数据。该数据集的核心应用场景在于训练和评估能够生成人类化、上下文感知的详细图像字幕的模型,特别是在资源受限环境下,通过精细调优较小规模模型(如BLIP-2)以实现与大型模型相媲美的性能。
实际应用
在实际应用中,PixLore数据集支持的图像字幕技术可广泛应用于辅助视觉障碍人士理解视觉内容、提升搜索引擎的图像检索能力,以及增强数字平台的内容可发现性。其生成的详细描述能够为实时场景分析、增强现实系统提供语义支持,并在自动驾驶、智能监控等需要精细环境解读的领域发挥潜在作用,实现从视觉感知到自然语言描述的顺畅转换。
衍生相关工作
PixLore数据集衍生的相关经典工作包括基于其丰富标注的CLIP等图像-文本模型的预训练,以及扩展令牌上下文窗口以捕获更复杂场景关系的研究。此外,该数据集启发了对文本到图像模型的精细调优,推动从长描述生成细节图像的技术发展,并在MiniGPT-4、Caption Anything等模型中展示了多模态控制与分割结合的应用潜力,进一步拓展了视觉-语言理解的边界。
以上内容由遇见数据集搜集并总结生成


