pubmed-ocr
收藏Hugging Face2026-01-21 更新2026-01-22 收录
下载链接:
https://huggingface.co/datasets/rootsautomation/pubmed-ocr
下载链接
链接失效反馈官方服务:
资源简介:
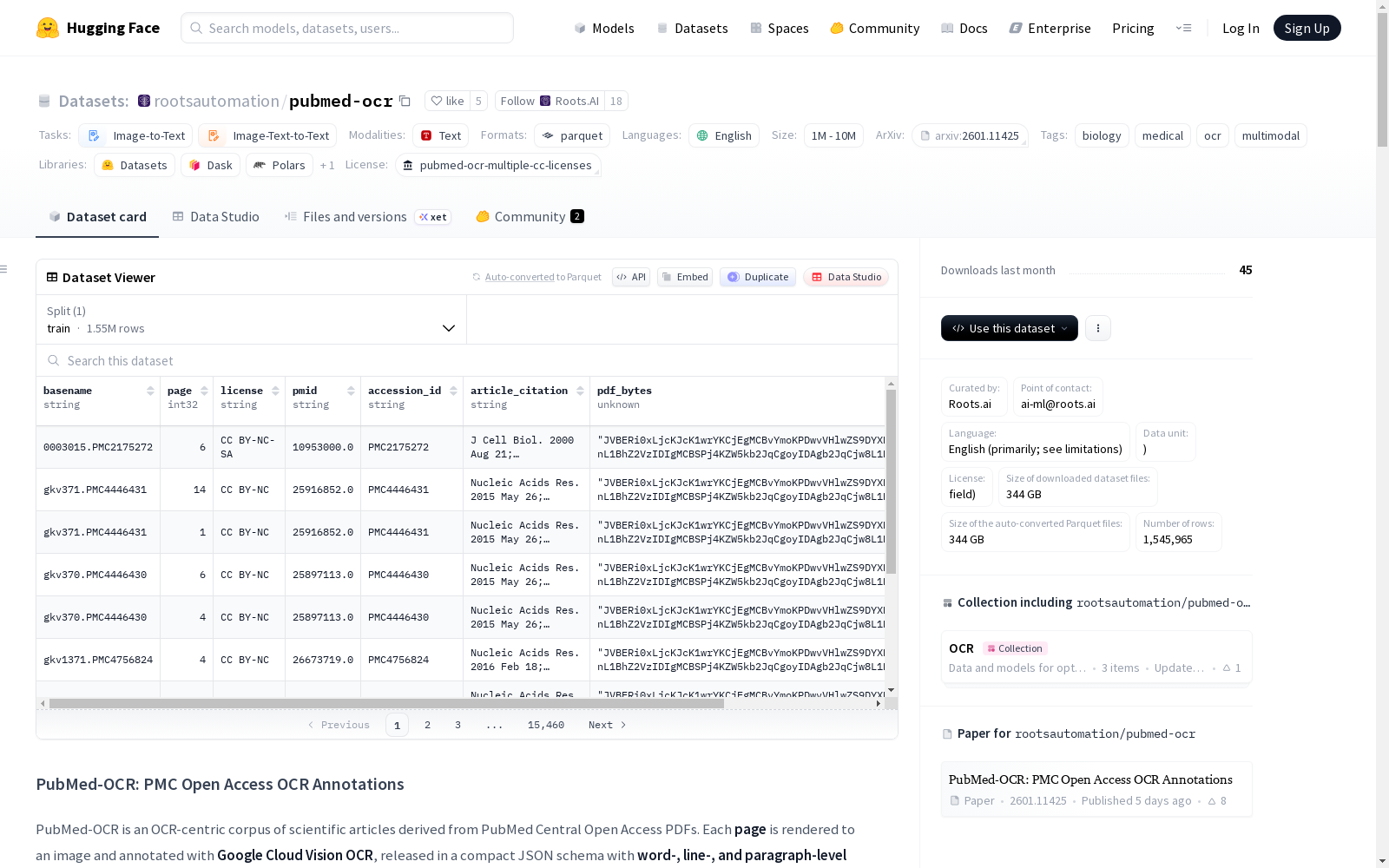
PubMed-OCR是一个基于PubMed Central开放获取PDF的科学文章OCR语料库。每页被渲染为图像,并使用Google Cloud Vision OCR进行标注,以紧凑的JSON格式发布,包含单词、行和段落级别的边界框。该数据集旨在支持布局感知建模、基于坐标的问答以及科学文档上OCR依赖管线的评估。数据集包含20.95万篇文章,约150万页,约13亿个单词(OCR标记)。
创建时间:
2026-01-16
原始信息汇总
PubMed-OCR 数据集概述
数据集基本信息
- 数据集名称:PubMed-OCR
- 官方描述:PubMed-OCR 是一个源自 PubMed Central Open Access PDF 的科学文章 OCR 中心语料库。每个页面都被渲染为图像,并使用 Google Cloud Vision OCR 进行标注,以紧凑的 JSON 模式发布,包含单词级、行级和段落级的边界框。
- 语言:英语(主要)
- 许可证:源自文章的多种许可证(每行
license字段记录) - 数据规模:
- 文章数量:209.5K
- 页面数量:约 1.5M
- OCR 词汇数量:约 13 亿
数据集结构与内容
- 数据单元:1 行 = 1 个 PDF 页面(由
{basename, page}唯一标识) - 数据字段:
basename(string):文章/页面组标识符。page(int32):PDF/文章内的页面索引。license(string):源文章的许可证(例如cc-by-4.0,cc-by-nc-4.0)。pmid(string):PubMed ID(如果可用)。accession_id(string):收录标识符(例如 PMCID 或内部 ID)。article_citation(string):源文章的引用字符串。pdf_bytes(binary):原始 PDF 字节(在允许重新分发的情况下提供);否则可能为空/空值。ocr_json(string):OCR 输出 JSON,包含像素坐标下的边界框。
- 数据格式:数据以 Parquet 文件格式提供。
- 数据划分:本版本作为单个
train划分提供,主要是一个语料库。建议为基准测试构建评估划分以减少泄漏。
数据集来源与创建
- 来源语料库:PubMed Central Open Access (PMCOA)
- 创建方:Roots.ai
- 联系人:ai-ml@roots.ai
- 创建过程:
- 下载 PMCOA PDF 并筛选允许重新分发衍生作品的许可证。
- 均匀采样 209.5K 篇文档。
- 以 150 DPI 渲染每个页面。
- 在页面图像上运行 Google Cloud Vision
document_text_detection。 - 提取单词级和段落级多边形,并规范化为轴对齐边界框
[x1, y1, x3, y3]。 - 通过聚类具有相似垂直对齐的单词(启发式方法)重建行边界框。
- 每页输出一行,包含
ocr_json(以及在允许的情况下包含pdf_bytes)。
- 标注过程:标注由 Google Cloud Vision OCR 机器生成。单词和段落由 OCR 引擎提供,行是根据单词框启发式重建的。
预期用途
- 训练/评估 OCR 感知或布局感知的文档模型。
- 测试依赖 OCR 的流程(解析、检索、提取)的鲁棒性。
- 构建需要坐标基础证据的任务(例如,引用和定位、区域归因)。
- 为科学 PDF(表格、公式、图注、参考文献)进行基准测试策划。
限制与注意事项
- OCR 输出非黄金文本:包含识别错误。
- 单一 OCR 引擎:输出反映了 Google Vision 的优势/弱点,可能无法推广到其他 OCR 系统。
- 启发式行重建:行分组和阅读顺序可能不完美,尤其是在多栏布局以及公式/表格周围。
- 轴对齐框:原始 OCR 多边形被简化为矩形。
- 领域偏差:PMCOA 的期刊分布呈重尾分布(高影响力期刊占主导)。
- 非文本区域:此数据集不提供表格/图形/公式的黄金结构(仅提供 OCR 输出 + 衍生的行)。
- 不适用范围:
- 不应用于临床/医疗决策。
- 不应用于在适用的许可条款之外学习受版权保护的内容。
- 不打算用作阅读顺序的真实数据集。
引用信息
如果使用 PubMed-OCR,请引用: bibtex @article{heidenreich2025pubmedocr, title={PubMed-OCR: PMC Open Access OCR Annotations}, author={Heidenreich, Hunter and Getachew, Yosheb and Dinica, Olivia and Elliott, Ben}, journal={arXiv preprint arXiv:2601.11425}, year={2025} }
相关链接
- 数据集仓库:https://huggingface.co/datasets/rootsautomation/pubmed-ocr
- 论文:https://huggingface.co/papers/2601.11425
搜集汇总
数据集介绍
构建方式
在生物医学文献数字化进程中,PubMed-OCR数据集通过系统性流程构建而成。其源数据来自PubMed Central开放获取计划中的学术论文PDF文件,经过许可筛选后,对约20.95万篇文献进行统一采样。每页文献以150 DPI分辨率渲染为图像,并采用Google Cloud Vision的文档文本检测功能进行光学字符识别。识别结果进一步处理,将原始多边形标注规范化为轴对齐的边界框,同时通过垂直对齐启发式方法重建行级边界框,最终以每页为独立数据单元,整合OCR输出与元数据,形成结构化数据集。
特点
该数据集的核心特征在于其规模与细粒度标注。涵盖约150万页文献,包含近13亿个OCR识别词汇,为大规模文档分析提供坚实基础。标注信息呈现多层次结构,提供词汇、行与段落级别的边界框坐标,支持对科学文献复杂版式的深入解析。数据集保留了原文的许可信息与引用数据,并附带可再分发的原始PDF字节,增强了数据的溯源能力与可用性。其设计专注于OCR依赖与版面感知任务,为评估模型在科学文档上的鲁棒性提供了专门资源。
使用方法
数据集主要服务于需要结合文本内容与空间信息的文档智能任务。研究人员可利用其进行版面感知模型的训练与评估,或测试OCR依赖流程的稳健性。在具体应用中,可通过Hugging Face数据集库加载数据,解析每行中的OCR JSON字段以获取各层级文本及其坐标。鉴于数据规模,建议采用流式读取方式以高效处理。为保障评估的公正性,构建基准时应考虑采用期刊级别或时间级别的数据划分策略,避免数据泄露,确保模型泛化能力的可靠验证。
背景与挑战
背景概述
在生物医学信息学领域,科学文献的数字化与结构化处理是推动知识发现与技术创新的基石。PubMed-OCR数据集于2025年由Roots.ai的研究团队发布,其核心研究问题聚焦于解决科学文档,特别是PubMed Central开放获取PDF中复杂版面布局的精准识别与解析。该数据集通过集成谷歌云视觉OCR技术,对约20.9万篇学术文献、近150万页内容进行自动化标注,提供了单词、行与段落级别的坐标边界框,为布局感知建模与坐标锚定的问答系统奠定了数据基础。它的出现显著增强了文档理解模型在生物医学文本处理中的鲁棒性与可解释性,对多模态学习与科学信息检索领域产生了深远影响。
当前挑战
该数据集旨在应对科学文档图像到文本转换中的核心挑战,即如何在高密度、多栏排版、富含公式与表格的学术PDF中实现精确的版面分析与文字识别。构建过程中的挑战包括依赖单一OCR引擎可能导致识别偏差,难以泛化至其他系统;启发式的行重建方法在复杂版面中易产生错误分组与阅读顺序混乱;坐标框的轴对齐简化损失了原始多边形细节;以及数据源本身存在的期刊分布长尾效应,可能引入领域偏差。这些因素共同构成了数据集在支持高精度、布局敏感的文档理解任务时所面临的主要障碍。
常用场景
经典使用场景
在生物医学信息学领域,PubMed-OCR数据集为布局感知的文档建模提供了关键支持。其经典使用场景聚焦于训练和评估OCR感知模型,特别是在处理科学文献PDF中复杂的多栏排版、公式和表格时,该数据集通过提供像素级坐标的单词、行和段落级边界框,使得模型能够学习文档的视觉结构与文本内容的对应关系,从而提升对科学文档的解析精度。
解决学术问题
该数据集有效解决了科学文档处理中因OCR错误和布局复杂性导致的文本提取与理解难题。通过提供大规模的OCR原生标注,它支持对OCR依赖流程的鲁棒性评估,并为坐标锚定的证据检索任务奠定基础,例如引文定位和区域归因,从而推动了文档图像分析与多模态学习在学术研究中的进展。
衍生相关工作
基于PubMed-OCR,衍生了一系列经典研究工作,主要集中在文档布局分析、多模态问答和科学信息抽取领域。例如,研究者利用其坐标标注开发了视觉-语言模型,用于理解文档中的表格和公式;同时,该数据集也为基准测试的构建提供了基础,促进了OCR技术在学术文档处理中的标准化评估。
以上内容由遇见数据集搜集并总结生成


