CS-FLEURS
收藏arXiv2025-09-18 更新2025-09-19 收录
下载链接:
https://huggingface.co/datasets/byan/cs-fleurs
下载链接
链接失效反馈官方服务:
资源简介:
CS-FLEURS是一个多语言和多语言混合语音识别与翻译系统的数据集,包含52种语言和113种独特的语言混合对。数据集分为三个子集:CS-FLEURS-READ,包含14种与英语混合的语言对;CS-FLEURS-XTTS,包含17种语言与英语混合的76对;CS-FLEURS-MMS,包含45种与英语混合的语言对。该数据集旨在为模型评估和训练提供支持,并通过使用合成语音来扩大语言混合语音研究的范围。
CS-FLEURS is a dataset designed for multilingual and code-mixed speech recognition and translation systems. It covers 52 languages and 113 unique code-mixed language pairs. The dataset is divided into three subsets: CS-FLEURS-READ, which includes 14 language pairs mixed with English; CS-FLEURS-XTTS, which contains 76 pairs formed by 17 languages mixed with English; and CS-FLEURS-MMS, which encompasses 45 language pairs mixed with English. This dataset aims to support model training and evaluation, and broaden the scope of code-mixed speech research through the use of synthetic speech.
提供机构:
Carnegie Mellon University, Mohamed bin Zayed University of Artificial Intelligence, Kyoto University, Humain, University of Sheffield, University of British Columbia, Johns Hopkins University, Brno University of Technology, University of Texas at Austin
创建时间:
2025-09-18
原始信息汇总
CS-FLEURS 数据集概述
数据集简介
CS-FLEURS 是一个用于开发和评估语码转换语音识别和翻译系统的新数据集,特别关注高资源语言之外的语言。
关键特性
- 包含 113 个独特的语码转换语言对,覆盖 52 种语言
- 提供 300 小时的语音数据,包括朗读语音和合成语音
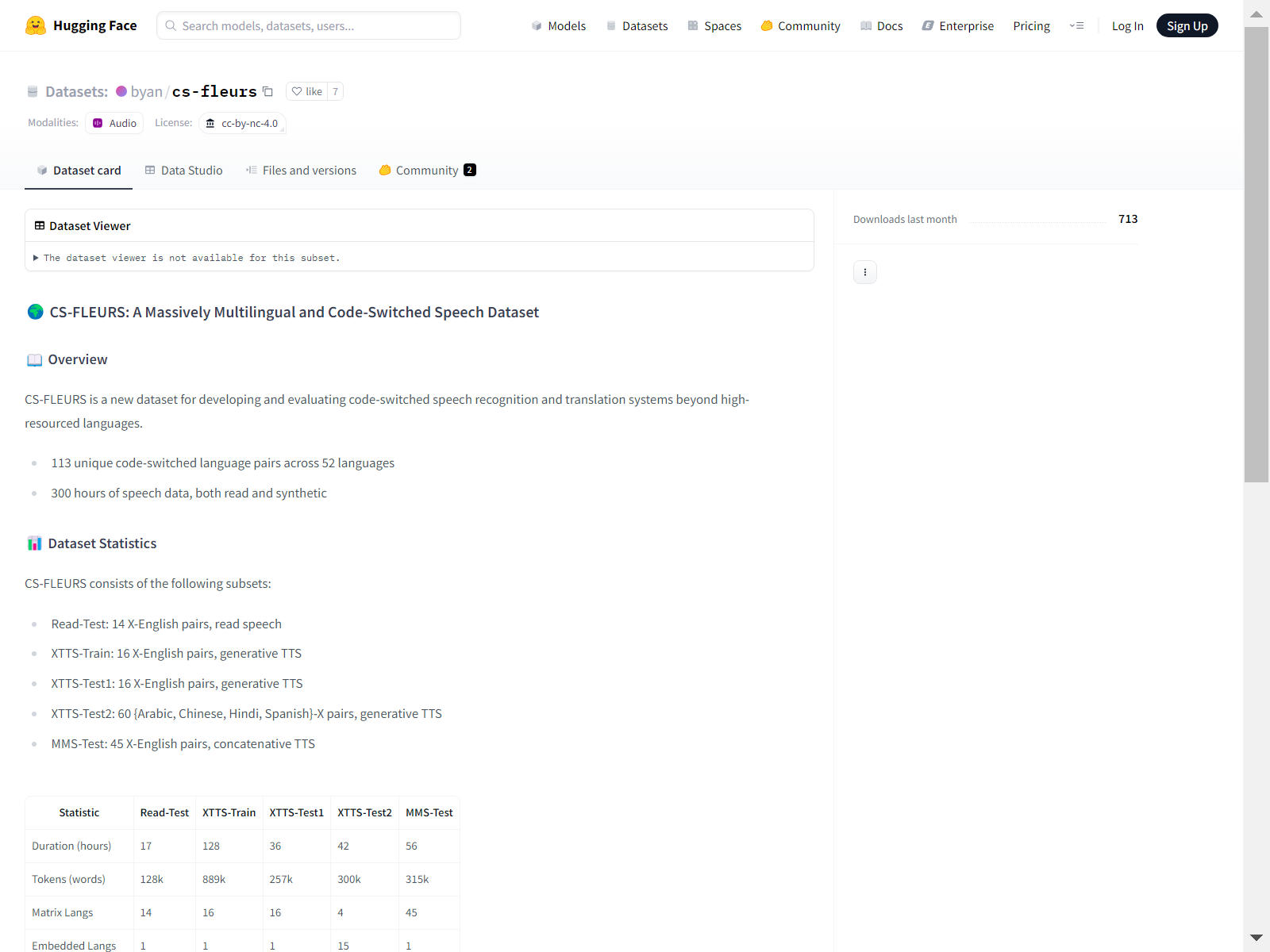
数据集子集
CS-FLEURS 包含以下子集:
- Read-Test:14 个 X-英语对,朗读语音
- XTTS-Train:16 个 X-英语对,生成式 TTS
- XTTS-Test1:16 个 X-英语对,生成式 TTS
- XTTS-Test2:60 个 {阿拉伯语、中文、印地语、西班牙语}-X 对,生成式 TTS
- MMS-Test:45 个 X-英语对,拼接式 TTS
数据集统计
| 统计指标 | Read-Test | XTTS-Train | XTTS-Test1 | XTTS-Test2 | MMS-Test |
|---|---|---|---|---|---|
| 时长(小时) | 17 | 128 | 36 | 42 | 56 |
| 词符数(单词) | 128k | 889k | 257k | 300k | 315k |
| 矩阵语言数量 | 14 | 16 | 16 | 4 | 45 |
| 嵌入语言数量 | 1 | 1 | 1 | 15 | 1 |
| 总语码转换对数 | 14 | 16 | 16 | 60 | 45 |
| 同文字对数量 | 7 | 10 | 10 | 10 | 22 |
| 异文字对数量 | 7 | 6 | 6 | 51 | 23 |
下载方式
使用 Git LFS 克隆: bash git lfs install git clone https://huggingface.co/datasets/byan/cs-fleurs
或在 🤗 Datasets 中直接加载: python from datasets import load_dataset data = load_dataset("byan/cs-fleurs")
许可证
本数据集采用 CC BY 4.0 许可证,仅限非商业用途。
引用
如使用本数据集,请引用:
@inproceedings{yan2025cs, title={CS-FLEURS: A Massively Multilingual and Code-Switched Speech Dataset}, author={Yan, Brian and Hamed, Injy and Shimizu, Shuichiro and Lodagala, Vasista and Chen, William and Iakovenko, Olga and Talafha, Bashar and Hussein, Amir and Polok, Alexander and Chang, Kalvin and others} }
搜集汇总
数据集介绍
构建方式
CS-FLEURS数据集通过混合真实朗读与合成语音技术构建,覆盖52种语言及113种语对组合。其朗读子集采用GPT-4o生成符合语法框架的代码切换文本,并由双语者录制验证;合成子集则通过XTTS-v2生成式模型与MMS-TTS拼接式模型生成语音,并利用跨语言强制对齐技术进行质量过滤。所有数据均基于FLEURS原始语料的分割标准,确保训练、验证与测试集的一致性。
特点
该数据集具备大规模多语言代码切换特性,包含真实朗读与合成语音两种模态,涵盖相同文字系统与混合文字系统的语对组合。其独特之处在于通过矩阵语言-嵌入语言框架控制代码切换模式,提供标准化文本领域与音频领域,支持跨语言语音识别与翻译任务的公平评估。数据集还提供了人类验证的流畅度评分与强制对齐质量指标,为模型鲁棒性分析提供多维参考。
使用方法
研究者可利用该数据集训练和评估多语言代码切换语音识别与翻译模型。训练时可通过合成数据增强模型对未见语对的泛化能力;评估时需区分相同文字与混合文字语对的性能差异。建议结合Whisper等基线模型进行跨语对基准测试,并利用提供的强制对齐分数过滤低质量样本以确保评估可靠性。数据集支持端到端语音处理流程,适用于零样本迁移与多任务学习场景。
背景与挑战
背景概述
CS-FLEURS数据集由卡内基梅隆大学、约翰斯·霍普金斯大学等全球多所顶尖研究机构于2025年联合推出,旨在填补语码转换语音识别与翻译领域的数据空白。该数据集基于FLEURS多语言语音语料库构建,涵盖52种语言和113种独特的语码转换对,通过合成语音与真实朗读语音的混合策略,为低资源语言场景下的语码转换研究提供了标准化评估基准。其创新性在于首次实现了跨语言脚本、跨语音生成方式的大规模语码转换数据覆盖,对推动多语言语音处理技术的公平性与包容性发展具有里程碑意义。
当前挑战
语码转换语音识别需解决跨语言语法结构混合导致的语义一致性难题,尤其在差异脚本语言对(如阿拉伯语-英语)中,模型需同步处理多种文字系统与音系规则。数据构建过程中,双语说话人稀缺性限制了真实语音采集规模,而合成语音生成需平衡语言学约束与自然度:基于LLM的文本生成存在10%的无效转换句 rejection rate,跨语言词对齐中的一词多译现象增加了嵌入词替换复杂度,TTS合成还需克服音素边界模糊与说话人身份不一致引发的声学失真问题。
常用场景
经典使用场景
在多语言语音处理研究中,CS-FLEURS数据集被广泛应用于代码切换语音识别与翻译系统的开发与评估。该数据集通过覆盖52种语言和113种独特的代码切换对,为研究者提供了标准化的测试环境,特别是在处理跨语言混合语音时展现出显著价值。其经典使用场景包括训练端到端语音识别模型,评估多语言语音系统在真实代码切换情境下的性能,以及推动低资源语言代码切换技术的研究进展。
衍生相关工作
CS-FLEURS的发布催生了一系列经典研究工作,包括基于Whisper模型的代码切换语音识别优化、跨语言语音合成技术的改进,以及低资源语言代码切换数据增强方法的发展。这些工作不仅扩展了多语言语音处理的边界,还推动了如XTTS-v2和MMS-TTS等合成语音技术在代码切换场景中的应用,为后续研究提供了重要的技术基础与评估框架。
数据集最近研究
最新研究方向
在多语言语音处理领域,CS-FLEURS数据集的推出显著推动了语码转换研究的前沿发展。该数据集通过融合朗读语音与合成语音技术,覆盖52种语言及113种独特语码对,为低资源语言的语码转换识别与翻译系统提供了标准化评估基准。当前研究热点集中于探索跨文字体系语码对的声学建模挑战,以及合成数据在提升模型泛化能力方面的有效性。Whisper等主流模型在异构文字语码转换任务中表现出的性能差距,揭示了语音识别系统在处理混合脚本时存在的固有局限性。这一数据集不仅填补了大规模语码转换数据资源的空白,更为构建真正包容性的多语言语音技术奠定了实证基础。
相关研究论文
- 1CS-FLEURS: A Massively Multilingual and Code-Switched Speech DatasetCarnegie Mellon University, Mohamed bin Zayed University of Artificial Intelligence, Kyoto University, Humain, University of Sheffield, University of British Columbia, Johns Hopkins University, Brno University of Technology, University of Texas at Austin · 2025年
以上内容由遇见数据集搜集并总结生成


