tytodd/sim-20-out-r12
收藏Hugging Face2026-04-25 更新2026-04-26 收录
下载链接:
https://hf-mirror.com/datasets/tytodd/sim-20-out-r12
下载链接
链接失效反馈官方服务:
资源简介:
---
dataset_info:
- config_name: go_emotions
features:
- name: text
dtype: string
- name: row_id
dtype: string
- name: ground_truth
list: int64
- name: messages
list:
- name: role
dtype: string
- name: content
dtype: string
- name: thinking
dtype: string
- name: reasoning
dtype: string
- name: labels
list: string
splits:
- name: val
num_bytes: 117359
num_examples: 5
- name: train
num_bytes: 126583
num_examples: 5
download_size: 273907
dataset_size: 243942
- config_name: or_bench_80k
features:
- name: prompt
dtype: string
- name: row_id
dtype: string
- name: ground_truth
dtype: string
- name: messages
list:
- name: role
dtype: string
- name: content
dtype: string
- name: thinking
dtype: string
- name: reasoning
dtype: string
- name: or_bench_category
dtype: string
splits:
- name: val
num_bytes: 85773
num_examples: 5
- name: train
num_bytes: 151763
num_examples: 5
download_size: 262374
dataset_size: 237536
configs:
- config_name: go_emotions
data_files:
- split: val
path: go_emotions/val-*
- split: train
path: go_emotions/train-*
- config_name: or_bench_80k
data_files:
- split: val
path: or_bench_80k/val-*
- split: train
path: or_bench_80k/train-*
---
提供机构:
tytodd
搜集汇总
数据集介绍
构建方式
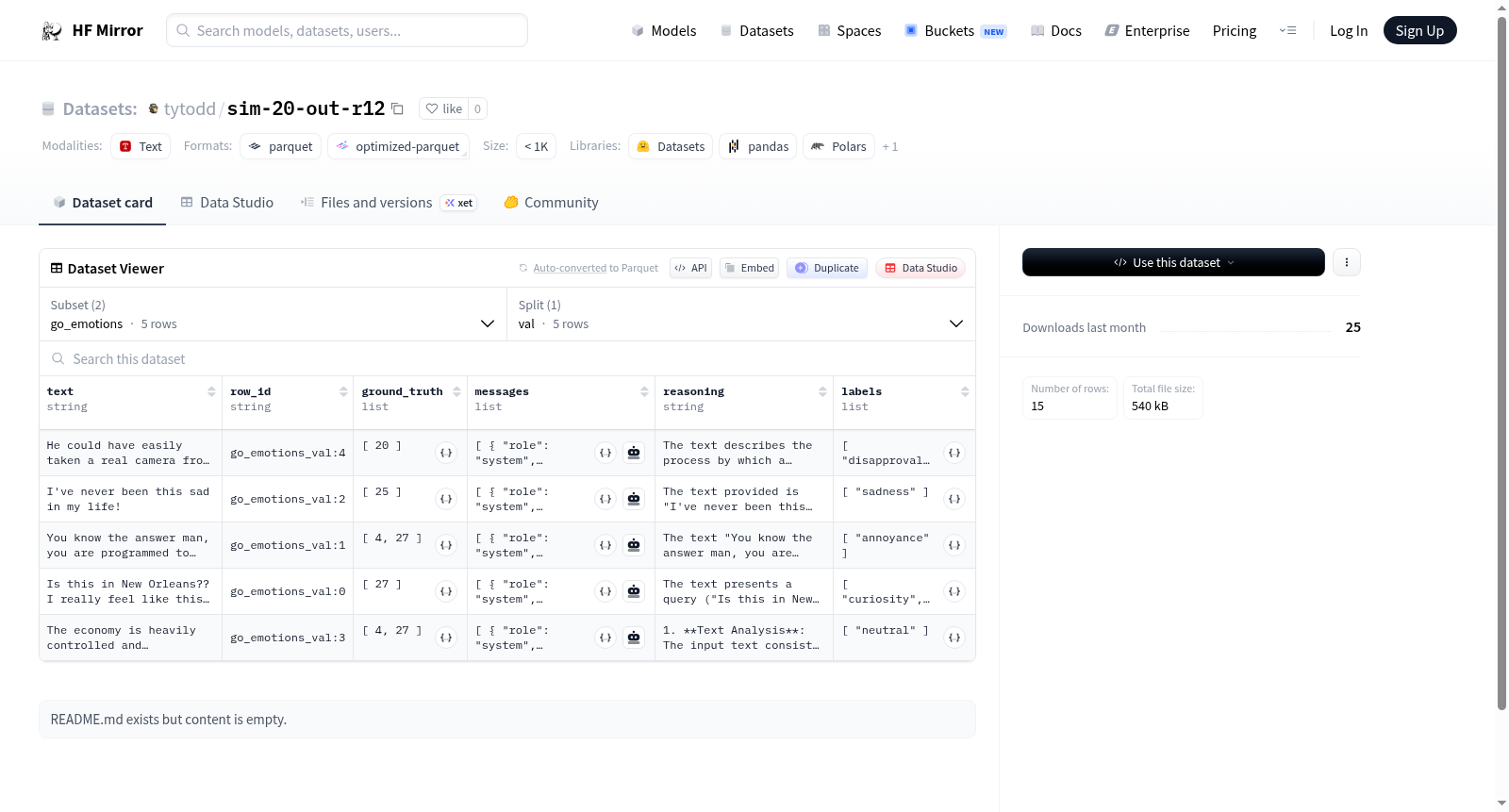
该数据集名为sim-20-out-r12,源自两个经典基准测试集go_emotions与or_bench_80k的精选子集。构建过程中,从原始数据中分别抽取了训练集和验证集各5条样本,以形成轻量化的评测集合。每条样本均保留了原始文本、行ID、真实标签等基础字段,并额外扩充了多轮对话消息结构(messages),其中包含角色、内容及思维链(thinking)信息,从而支持对模型推理过程的深度分析。
使用方法
数据集通过HuggingFace的datasets库加载,可指定config_name为'go_emotions'或'or_bench_80k'以获取对应子集。使用方法上,用户可分别调用train和val拆分进行模型的训练评估与验证。每一条样本的messages字段蕴含了完整的交互历史与思考过程,适合用于对话系统的思维链对齐实验,而labels或ground_truth字段则支持标准的分类与生成性能度量。
背景与挑战
背景概述
sim-20-out-r12数据集由研究团队在自然语言处理领域的情感计算与推理任务中创建,旨在推动对语言中细微情感和逻辑推理的理解。该数据集整合了GoEmotions和OR-Bench-80k两大子集,前者聚焦于多类别情感标注,后者则侧重开放式推理任务的评估。核心研究问题在于如何通过少样本学习或提示工程,让模型同时捕捉文本的情感倾向与推理链条。自发布以来,该数据集为情感分析、对话系统及可解释AI的研究提供了重要的基准测试资源,促进了模型在复杂语境下的语义理解能力提升。
当前挑战
该数据集面临的核心挑战包括:其一,情感与推理的联合建模难题,即如何在不牺牲各任务性能的前提下,有效融合情感识别与逻辑推理两种认知过程;其二,标注数据的稀疏性与不均衡性,由于仅包含训练和验证集各5条样本,模型难以从少量实例中泛化,易引发过拟合;其三,多标签情感分类的模糊边界,如GoEmotions中28类情感的细粒度区分常存在主观歧义;其四,构建过程中需统一不同来源数据的格式与标签体系,确保跨子集的一致性,例如兼容原始GoEmotions的文本字段与OR-Bench-80k的提示字段,增加了预处理复杂性。
常用场景
经典使用场景
在情感计算与自然语言理解的前沿交叉地带,sim-20-out-r12数据集为多层次情感识别任务提供了精细化的评估基准。该数据集以GoEmotions架构为蓝本,将文本与结构化推理路径(thinking/reasoning字段)耦合,使得研究者在情感分类之外,得以探索模型如何捕捉复杂情绪背后的认知链条。经典的微调与零样本评估场景中,研究者通过对比模型在ground_truth与推理链上的一致性,量化模型对情绪语义的深度理解能力。这种兼具标注细腻度与推理透明度的设计,尤其适合评测大规模语言模型在情感歧义消解与多标签分类中的鲁棒性。
解决学术问题
该数据集直指当前情感分析领域的两大痼疾:情感标签的粗粒度化与模型推理过程的不可解释性。传统数据集多止于六类基本情绪,难以刻画人类情感复杂的交织状态,而sim-20-out-r12通过引入20类精细情感标签(基于GoEmotions体系),解决了微观情绪区分与多标签共现的建模难题。其核心突破在于将思考过程(thinking)作为额外监督信号,为情感识别提供了可溯源的认知路径,使得学术界得以从'是什么情绪'转向'为什么这样判断',有力推动了可解释情感推理的研究范式发展。
实际应用
在产业界,该数据集的价值体现在构建具有理性判断能力的情绪交互系统。基于其推理标签,心理健康辅助机器人能够不仅识别用户的焦虑或愤怒,更能追溯情绪触发点,从而提供更具同理心的干预建议;在客户服务领域,企业可借助该数据集训练的模型区分'失望''失望且困惑'等复合情绪,实现精准的投诉分类与话术动态调整。此外,数据集中的行级标识与结构化对话格式(messages字段)天然适配会话系统的评估,使得在线教育平台能实时分析学生在解题时的挫败感与兴趣点,驱动教学策略的智能优化。
数据集最近研究
最新研究方向
该数据集融合了情感识别与开放式推理基准,为多轮对话中的思维链(Chain-of-Thought)与推理过程标注提供了结构化支持。当前前沿研究聚焦于利用其go_emotions子集进行细粒度情感分析,结合or_bench_80k子集探索模型在复杂任务中的可解释性推理能力。通过与热门的大语言模型对齐研究相交织,该数据集在验证模型情感理解与逻辑推演的一致性上展现出关键价值,推动着对话系统从表面响应向深度认知的跃迁。
以上内容由遇见数据集搜集并总结生成


