trump-speech-dataset-tts
收藏官方服务:
资源简介:
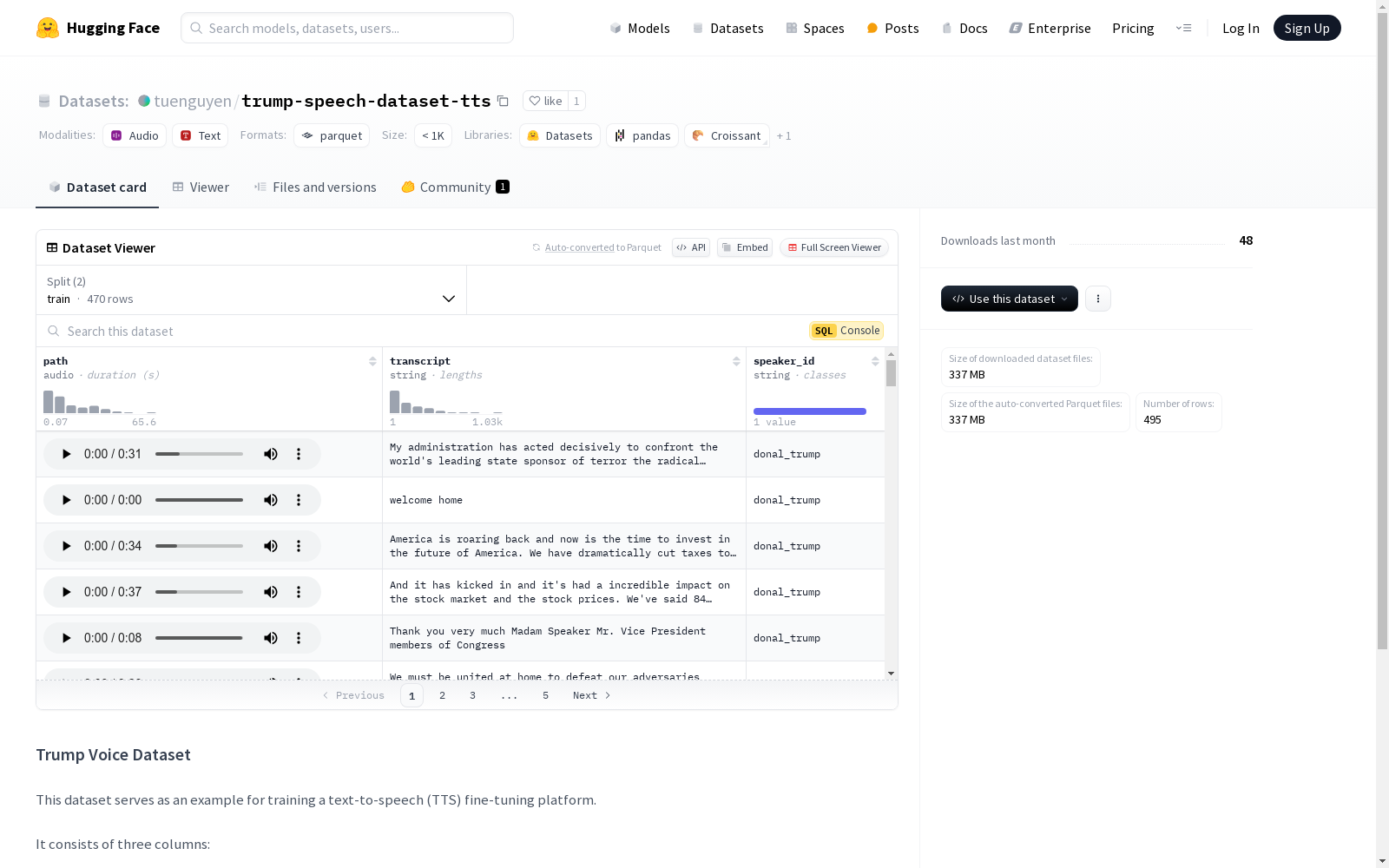
该数据集用作训练文本到语音(TTS)微调平台的示例。它包含三个列:path(音频文件路径)、transcript(音频的文本转录)和speaker_id(说话者的唯一标识符)。如果未提供转录文本,将使用Whisper-large v3模型自动生成。
This dataset serves as examples for training a text-to-speech (TTS) fine-tuning platform. It includes three columns: path (audio file path), transcript (text transcription of the audio), and speaker_id (unique identifier of the speaker). If no transcript is provided, the Whisper-large v3 model will be used to automatically generate it.
创建时间:
2025-01-09
搜集汇总
数据集介绍
构建方式
trump-speech-dataset-tts数据集的构建基于文本到语音(TTS)技术的需求,旨在为TTS模型的微调提供高质量的语音数据。该数据集通过收集前美国总统唐纳德·特朗普的公开演讲录音,并结合自动转录技术生成对应的文本转录。对于未提供转录的音频,数据集利用Whisper-large v3模型进行自动转录,确保数据的完整性和可用性。数据集的构建过程注重语音与文本的精确对齐,以满足TTS模型训练的高标准要求。
特点
该数据集的特点在于其专注于单一说话者的语音数据,即唐纳德·特朗普的演讲录音,这为研究特定说话者的语音特征提供了独特资源。数据集包含音频文件路径、文本转录以及说话者标识符三个主要字段,其中文本转录字段为可选,未提供转录的音频将通过Whisper-large v3模型自动生成。数据集的训练集和测试集分别包含470和25个样本,确保了模型训练和评估的充分性。
使用方法
trump-speech-dataset-tts数据集的使用方法主要围绕TTS模型的微调展开。用户可以通过加载数据集中的音频文件及其对应的文本转录,直接用于TTS模型的训练。对于未提供转录的音频,用户可以选择使用Whisper-large v3模型进行自动转录,或根据需求手动标注。数据集的训练集和测试集划分明确,用户可分别用于模型训练和性能评估,确保模型在实际应用中的泛化能力。
背景与挑战
背景概述
trump-speech-dataset-tts数据集是一个专门用于文本到语音(TTS)微调平台的示例数据集,主要聚焦于前美国总统唐纳德·特朗普的语音数据。该数据集由音频文件路径、文本转录和说话者标识三部分组成,旨在为TTS模型的训练提供高质量的语音样本。尽管数据集的具体创建时间和主要研究人员未在README中明确提及,但其设计显然是为了支持语音合成领域的研究与应用,尤其是在个性化语音生成方面。该数据集的发布为语音合成技术的发展提供了重要的数据资源,推动了TTS模型在特定人物语音模拟上的进步。
当前挑战
trump-speech-dataset-tts数据集在解决语音合成领域的挑战中面临多重问题。首先,语音数据的采集与标注需要高精度,以确保转录文本与音频内容的高度一致性,这对数据质量提出了严格要求。其次,个性化语音合成的核心在于捕捉特定说话者的语音特征,这要求数据集包含足够多样化的语音样本以覆盖不同的语音模式和情感表达。此外,数据集的构建过程中还面临自动转录技术的局限性,尽管使用了Whisper-large v3模型生成转录文本,但自动生成的转录可能存在误差,需要进一步的人工校对与修正。这些挑战共同构成了该数据集在语音合成领域应用中的关键难点。
常用场景
经典使用场景
在语音合成领域,trump-speech-dataset-tts数据集被广泛用于训练和优化文本到语音(TTS)模型。该数据集包含了前美国总统特朗普的语音样本及其对应的文本转录,为研究人员提供了一个高质量的语音数据源,用于探索语音合成的精细调优和个性化语音生成。
衍生相关工作
基于trump-speech-dataset-tts数据集,许多经典研究工作得以展开。例如,研究人员开发了基于深度学习的个性化TTS模型,能够生成高度逼真的特朗普语音。此外,该数据集还推动了语音风格迁移和跨语言语音合成的研究,为语音合成技术的多样化应用提供了新的可能性。
数据集最近研究
最新研究方向
在语音合成领域,trump-speech-dataset-tts数据集为文本到语音(TTS)模型的微调提供了重要资源。该数据集包含前美国总统特朗普的演讲音频及其文本转录,为研究个性化语音合成提供了丰富的素材。近年来,随着深度学习技术的进步,个性化TTS模型的研究成为热点,尤其是在政治人物、名人等特定人物的语音合成方面。该数据集的应用不仅推动了TTS技术的个性化发展,还为语音生成的真实性和自然度提供了新的研究方向。此外,结合Whisper-large v3模型自动生成转录的功能,进一步提升了数据集的可用性和研究价值,为语音合成领域的模型优化和跨语言应用提供了新的可能性。
以上内容由遇见数据集搜集并总结生成


