reddit_dataset_197
收藏Hugging Face2025-03-28 更新2025-03-29 收录
下载链接:
https://huggingface.co/datasets/immortalizzy/reddit_dataset_197
下载链接
链接失效反馈官方服务:
资源简介:
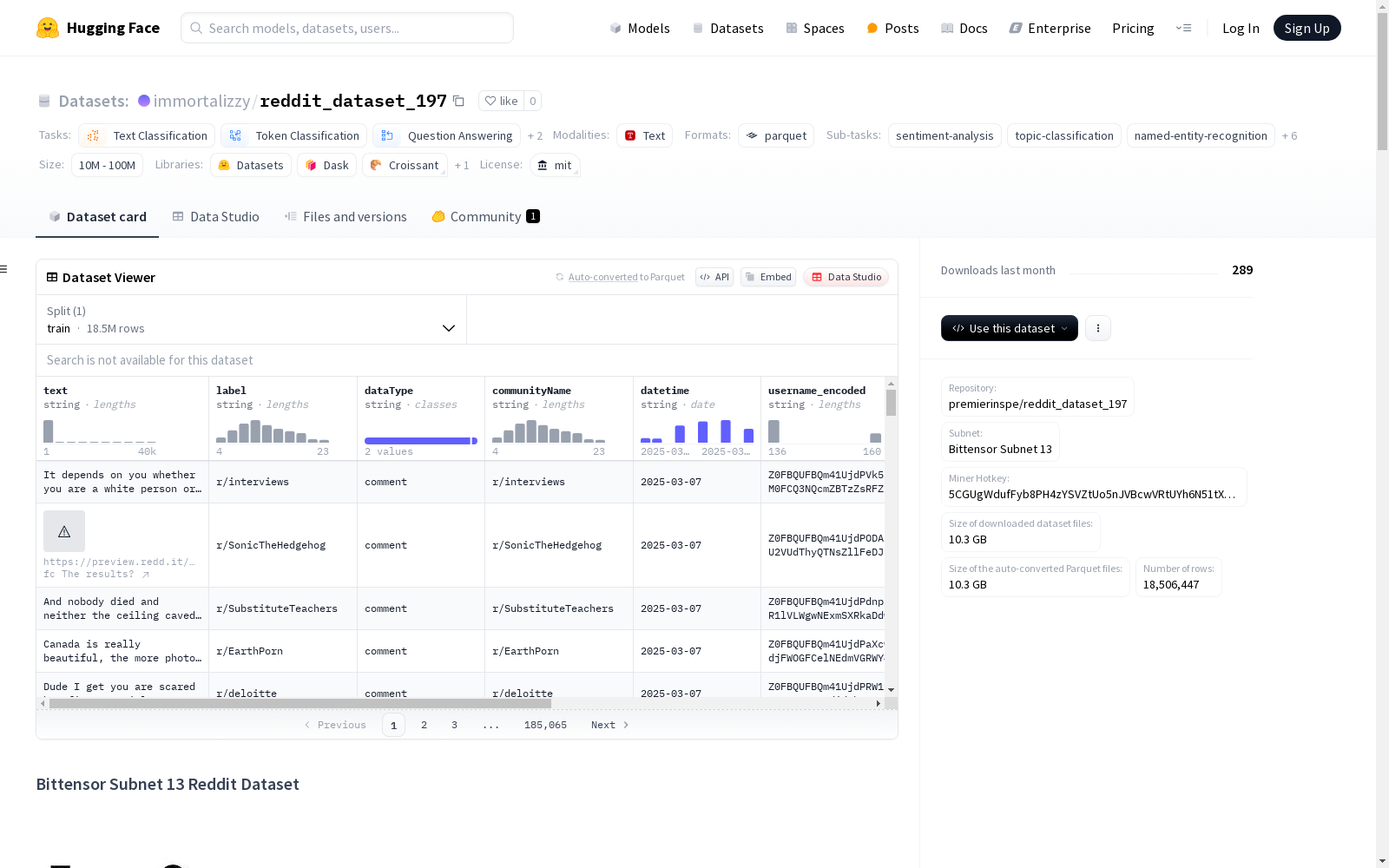
Bittensor Subnet 13 Reddit数据集是Bittensor Subnet 13去中心化网络的一部分,包含了预处理后的Reddit数据。这个数据集不断更新,提供实时的Reddit内容流,用于各种分析和机器学习任务。数据集以英文为主,也可能包含其他语言。数据集支持情感分析、主题建模、社区分析、内容分类等多种NLP任务。每个数据实例代表一个Reddit帖子或评论,包括文本内容、标签、数据类型、社区名称、时间戳、编码的用户名和URL等字段。
创建时间:
2025-03-27
搜集汇总
数据集介绍
构建方式
在社交媒体分析领域,reddit_dataset_197数据集通过Bittensor Subnet 13去中心化网络构建,采用实时更新的方式采集Reddit平台的公开帖文与评论数据。数据采集严格遵循平台服务条款与API使用规范,所有用户名和URL均经过编码处理以保护用户隐私,确保数据来源的合规性与匿名性。数据集通过分布式矿工节点持续更新,形成动态演化的社交语料库。
特点
该数据集呈现多维度特征,包含1850万条实例的庞大规模,时间跨度集中于2025年3月的动态数据。数据结构涵盖文本内容、情感标签、社区归属等七个字段,其中评论占比高达93.44%,真实反映Reddit社区互动生态。数据具有典型社交媒体的长尾分布特征,头部社区如r/AskReddit占比2.07%,同时包含多语言内容,为研究网络社群行为提供丰富素材。
使用方法
研究者可利用该数据集开展文本分类、实体识别等多元任务,建议根据时间戳自定义数据划分方案。使用前需注意数据存在的时空局限性,建议结合去偏差技术处理社群固有偏见。典型应用场景包括:通过dataType字段区分主帖与评论进行对话分析,利用communityName字段研究亚文化传播,或基于datetime字段构建时间序列模型。所有应用需遵守MIT许可协议及Reddit平台条款。
背景与挑战
背景概述
reddit_dataset_197是由Bittensor Subnet 13去中心化网络构建的社交媒体数据集,专注于收集和预处理Reddit平台的公开帖文与评论。该数据集由premierinspe等研究人员于2025年发布,依托于宏宇宙数据生态系统(macrocosm-os),旨在为自然语言处理任务提供实时、多样化的社交文本资源。其核心研究问题聚焦于社交媒体动态分析,涵盖情感识别、话题建模、社区行为挖掘等方向,通过去中心化矿工节点持续更新数据流,为社交计算和舆情分析领域提供了高时效性的基准数据。数据集采用多任务标注体系,支持文本分类、实体识别、摘要生成等十余种NLP任务,体现了Web 3.0时代分布式数据采集的创新范式。
当前挑战
该数据集面临三方面核心挑战:在领域问题层面,社交媒体的噪声数据与隐式语义增加了情感分析和话题建模的难度,非结构化文本中的讽刺、多义现象导致传统NLP模型性能下降;数据构建过程中,去中心化采集机制虽然保障了实时性,但各节点数据质量的不一致性需要复杂的清洗流程,且编码后的用户信息可能损失部分社交关系特征。此外,平台内容固有的选择偏差使得数据难以覆盖小众社区,而实时更新机制带来的概念漂移现象对模型持续学习提出更高要求。隐私保护与数据效用之间的平衡也是重要挑战,严格的匿名化处理可能削弱用户行为分析的深度。
常用场景
经典使用场景
在社交媒体分析领域,reddit_dataset_197数据集以其海量的Reddit帖子和评论内容,为研究者提供了丰富的文本分析素材。该数据集特别适用于自然语言处理任务,如情感分析和主题建模,能够帮助研究者深入理解网络社区的讨论动态和用户行为模式。通过分析不同子版块的内容,可以揭示特定话题的舆论倾向和社区文化特征。
实际应用
商业机构可利用该数据集进行品牌舆情监测,通过分析消费者在相关子版块的讨论内容,及时掌握产品反馈和市场趋势。政府部门则能借助这些数据识别突发公共事件中的民众情绪波动,为危机公关决策提供依据。教育研究者也可从中挖掘网络学习社区的知识构建过程,优化在线教育平台的设计。
衍生相关工作
基于该数据集的经典研究包括开发新型的跨社区情感迁移学习模型,以及构建面向Reddit语境的领域自适应预训练语言模型。在信息检索领域,有学者利用其层级化的社区结构,提出了改进的对话系统回复生成算法。近期工作还探索了结合时间序列分析的舆论预测框架,这些创新都得益于数据集提供的多维元信息。
以上内容由遇见数据集搜集并总结生成


