har1/MTS_Dialogue-Clinical_Note
收藏Hugging Face2024-04-01 更新2024-06-11 收录
下载链接:
https://hf-mirror.com/datasets/har1/MTS_Dialogue-Clinical_Note
下载链接
链接失效反馈官方服务:
资源简介:
---
license: mit
task_categories:
- text2text-generation
- feature-extraction
- summarization
language:
- en
tags:
- medical
pretty_name: clinical-note-generator
---
## MTS Dialogue (Clinical Note Summarisation)
Main Dataset
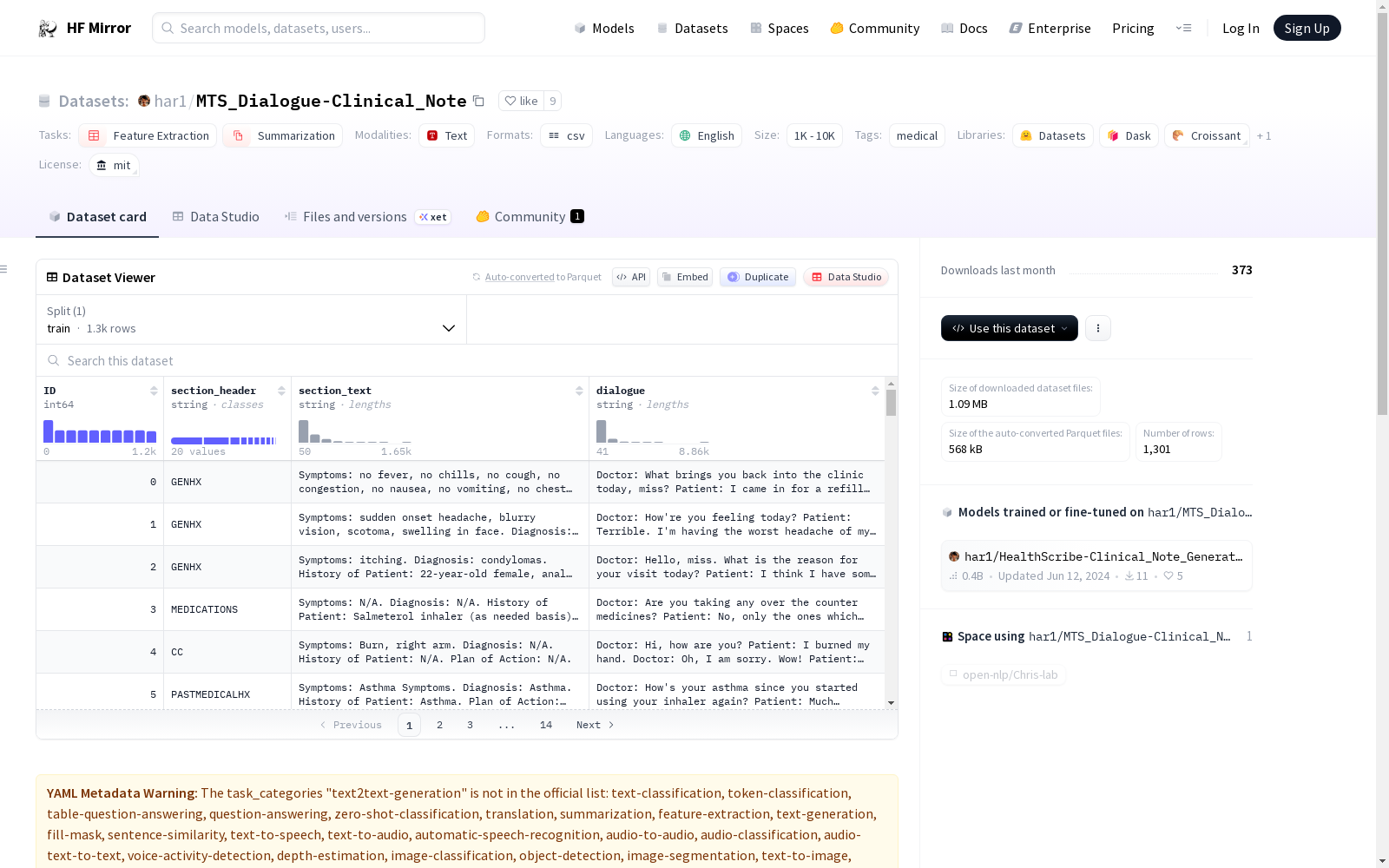
The MTS-Dialog dataset is a new collection of 1.7k short doctor-patient conversations and corresponding summaries (section headers and contents).
The training set consists of 1,201 pairs of conversations and associated summaries.
The validation set consists of 100 pairs of conversations and their summaries.
The "dialogue" column contain Doctor-Patient conversation. The "section_text" column contains the Clinical Note of the Doctor-Patient conversation. This clinical note is of the format :
* Symptoms:
* Diagnosis:
* History of Patient:
* Plan of Action:
*** N/A is given if no information is found for each of the sections.
This dataset is a modified version of the [MTS-Dialog dataset](https://github.com/abachaa/MTS-Dialog).
The dataset was modified to satisfy the needs of the [har1/HealthScribe-Clinical_Note_Generator](https://huggingface.co/har1/HealthScribe-Clinical_Note_Generator) model. This is a fine-tuned version of [facebook/bart-large-cnn](https://huggingface.co/facebook/bart-large-cnn).
The main contributors of this dataset i.e. the modified version are :
* [Aleena Patani](https://www.linkedin.com/in/aleena-patani-47aa69267/),
* [Amigashabnam F](https://www.linkedin.com/in/amigashabnamf/),
* [Harikrishnan K C](https://www.linkedin.com/in/harikrishnan-kc-a0a0441b9/),
* [Sreeja S](https://www.linkedin.com/in/sreeja-s-9b3b43287/),
* [Sujith Jayaprakash](https://www.linkedin.com/in/sujith-jayaprakash-291453288/).
license: MIT许可证
task_categories:
- 文本到文本生成
- 特征提取
- 摘要生成
language:
- 英语
tags:
- 医疗
pretty_name: 临床笔记生成器
---
## MTS对话(临床笔记摘要)主数据集
MTS-Dialog数据集是包含1700组医患对话及对应摘要(含章节标题与内容)的全新合集。
训练集包含1201组对话与关联摘要对。
验证集包含100组对话与摘要对。
其中"dialogue"列存储医患对话内容,"section_text"列存储对应医患对话的临床笔记,该临床笔记格式如下:
* 症状:
* 诊断:
* 患者病史:
* 行动方案:
*** 若某一章节无相关信息,则标注为"N/A"。
本数据集是[MTS-Dialog数据集](https://github.com/abachaa/MTS-Dialog)的修改版本。
本次修改是为适配[har1/HealthScribe-Clinical_Note_Generator](https://huggingface.co/har1/HealthScribe-Clinical_Note_Generator)模型的需求,该模型是[facebook/bart-large-cnn](https://huggingface.co/facebook/bart-large-cnn)的微调版本。
本修改版数据集的主要贡献者为:
* [Aleena Patani](https://www.linkedin.com/in/aleena-patani-47aa69267/)
* [Amigashabnam F](https://www.linkedin.com/in/amigashabnamf/)
* [Harikrishnan K C](https://www.linkedin.com/in/harikrishnan-kc-a0a0441b9/)
* [Sreeja S](https://www.linkedin.com/in/sreeja-s-9b3b43287/)
* [Sujith Jayaprakash](https://www.linkedin.com/in/sujith-jayaprakash-291453288/)
提供机构:
har1
原始信息汇总
数据集概述
基本信息
- 许可证: MIT
- 任务类别:
- 文本生成
- 特征提取
- 摘要生成
- 语言: 英语
- 标签: 医疗
- 名称: clinical-note-generator
数据集详情
- 名称: MTS Dialogue (Clinical Note Summarisation)
- 描述: 包含1.7k对医生与患者对话及其对应摘要(章节标题和内容)的数据集。
- 训练集: 包含1,201对对话及其摘要。
- 验证集: 包含100对对话及其摘要。
- 数据结构:
- 对话列: 包含医生与患者的对话。
- 章节文本列: 包含医生与患者对话的临床笔记,格式为:
- 症状
- 诊断
- 患者病史
- 行动计划
- *** 若无信息,则标记为N/A。
数据集来源与修改
- 原始数据集: MTS-Dialog dataset
- 修改目的: 满足har1/HealthScribe-Clinical_Note_Generator模型的需求。
- 模型基础: facebook/bart-large-cnn的微调版本。
主要贡献者
搜集汇总
数据集介绍
构建方式
在临床医学信息处理领域,MTS Dialogue-Clinical Note数据集通过系统化采集与标注构建而成。该数据集源自MTS-Dialog原始资源,经过针对性修改以满足特定临床笔记生成模型的需求。构建过程涉及筛选并整理1700组医患对话及其对应的临床笔记摘要,其中训练集包含1201组对话-摘要对,验证集则涵盖100组。每份临床笔记均按照症状、诊断、患者病史及行动计划等结构化字段进行组织,缺失信息以“N/A”标注,确保了数据的规范性与完整性。
特点
该数据集的核心特点在于其高度结构化的临床笔记格式与医患对话的精准对应。笔记内容严格遵循症状、诊断、病史及行动计划等医学记录标准字段,为自然语言处理任务提供了清晰的语义框架。数据集规模适中,涵盖多样化的临床对话场景,兼具专业性与实用性。作为MTS-Dialog的修改版本,它特别适配于基于BART架构的临床笔记生成模型,为医疗文本摘要与特征提取研究提供了高质量的基准资源。
使用方法
在医疗自然语言处理应用中,该数据集主要用于文本到文本生成、特征提取及摘要任务。研究人员可借助训练集微调预训练模型,如BART-large-CNN,以学习从医患对话到结构化临床笔记的映射关系。验证集则用于评估模型在笔记生成准确性、信息完整性方面的性能。使用时应严格遵循数据划分,注意临床笔记中“N/A”字段的处理,确保模型能够合理识别并处理信息缺失情况,从而支持自动化临床文档生成系统的开发与优化。
背景与挑战
背景概述
在医疗信息学领域,临床记录的自动化生成是提升诊疗效率与准确性的关键研究方向。MTS Dialogue-Clinical Note数据集由Aleena Patani、Harikrishnan K C等研究人员于近期构建,基于原始MTS-Dialog数据集进行优化,专门服务于临床笔记生成任务。该数据集收录了约1.7千条医患对话及其对应的结构化临床笔记,涵盖症状、诊断、病史与行动计划等核心模块,旨在通过自然语言处理技术,将非结构化的对话内容转化为标准化的医疗文档。这一资源的出现,为医疗文本生成模型提供了高质量的监督数据,推动了临床辅助系统在自动化记录与信息整合方面的发展。
当前挑战
该数据集致力于解决医患对话到临床笔记的自动生成问题,其核心挑战在于对话中医疗术语的歧义性、信息冗余与隐含逻辑的提取。构建过程中,研究人员需克服原始对话与标准临床笔记之间的格式差异,确保各章节(如症状、诊断)内容的准确对应与完整性标注,并在缺乏明确信息时以“N/A”进行合理填充。此外,数据规模的有限性(仅1.7千条样本)与医疗领域的专业性要求,对模型的泛化能力与领域适应提出了更高层次的考验。
常用场景
经典使用场景
在临床医学信息处理领域,MTS_Dialogue-Clinical_Note数据集为医生与患者对话的自动摘要生成提供了关键支持。该数据集包含约1.7千条医患对话及其对应的结构化临床笔记,涵盖症状、诊断、病史与行动计划等核心部分。经典使用场景聚焦于自然语言处理模型训练,特别是文本到文本生成任务,通过对话内容自动提炼出标准化的临床记录,有效模拟真实医疗文档撰写流程,为医疗人工智能应用奠定数据基础。
解决学术问题
该数据集主要解决了医疗文本自动摘要中的领域适应性问题。传统摘要模型在通用领域表现良好,但面对专业医学术语和对话结构时往往效果受限。通过提供标注规范的医患对话-临床笔记对,研究者能够开发专门针对医疗场景的序列到序列模型,提升临床信息提取的准确性与完整性。这不仅推动了医疗自然语言处理技术的发展,也为减轻临床文档负担提供了学术探索路径。
衍生相关工作
基于该数据集衍生的经典工作包括har1/HealthScribe-Clinical_Note_Generator模型,这是对facebook/bart-large-cnn模型在医疗领域的精调成果。相关研究聚焦于跨领域迁移学习,探索预训练语言模型在专业医疗文本生成中的适应性改进。此外,该数据集的原始版本MTS-Dialog也被广泛应用于医疗对话理解、多模态临床信息整合等研究方向,催生了系列关于医疗文本摘要质量评估与领域特定优化策略的学术论文。
以上内容由遇见数据集搜集并总结生成


