XNLIvar
收藏arXiv2025-06-18 更新2025-06-22 收录
下载链接:
https://huggingface.co/datasets/HiTZ/XNLIvar
下载链接
链接失效反馈官方服务:
资源简介:
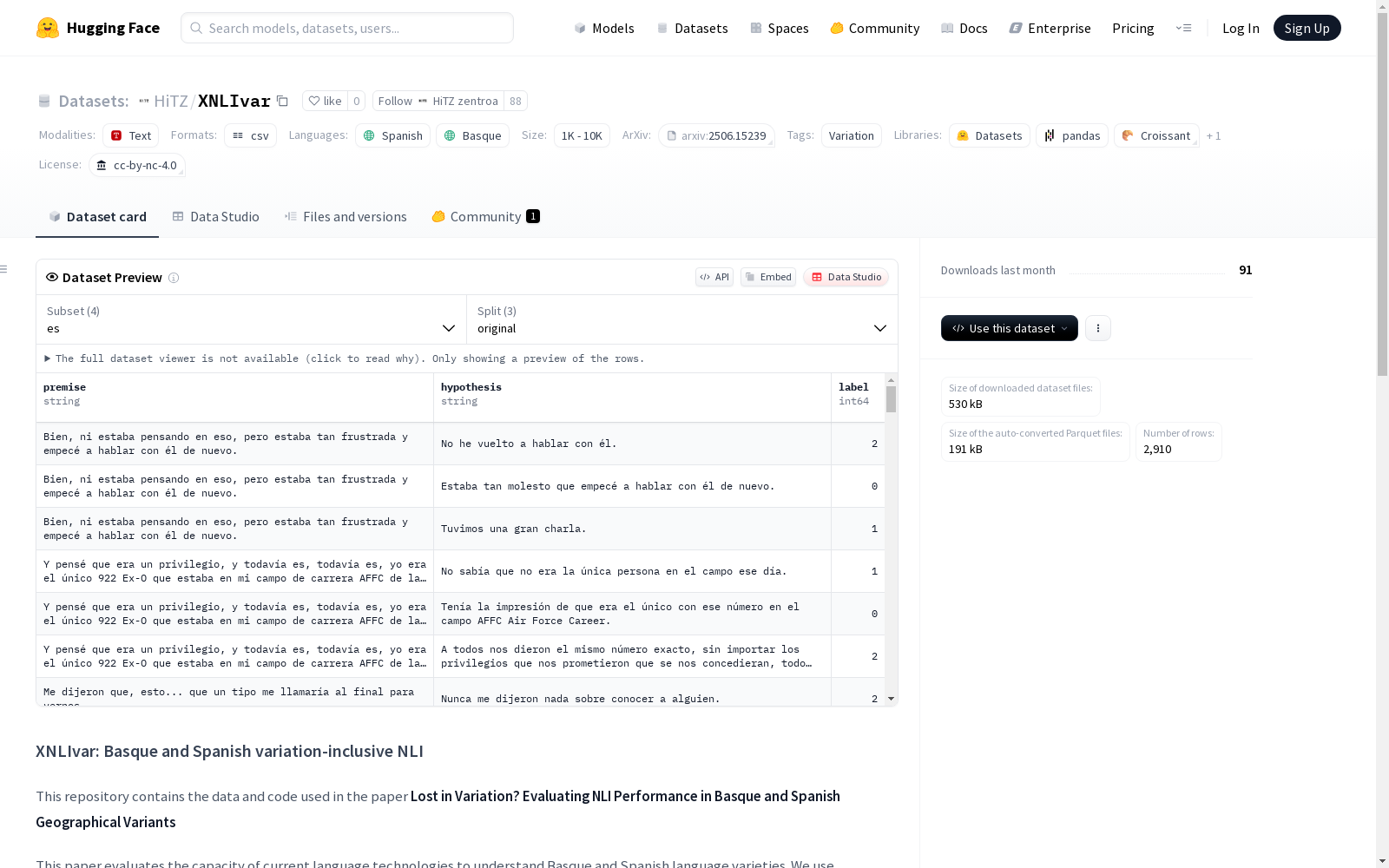
XNLIvar数据集是首个公开的手工整理的NLI数据集,用于评估自然语言处理技术对巴斯克语和西班牙语地区语言变体的理解能力。该数据集由HiTZ中心与巴塞罗那大学合作开发,包含了巴斯克语和西班牙语的多种地区语言变体,旨在帮助NLP系统更好地处理不同地区的语言变体。数据集由12位巴斯克语母语者和6位西班牙语母语者参与创建,涵盖了巴斯克语和西班牙语的多个地区变体,包括西部、中部和纳瓦拉地区。数据集共包含1550条数据,其中巴斯克语变体数据894条,西班牙语变体数据666条。该数据集可用于训练和评估自然语言理解模型,以解决跨地区语言变体带来的挑战。
提供机构:
HiTZ Center - Ixa, University of the Basque Country UPV/EHU
创建时间:
2025-06-18
原始信息汇总
XNLIvar数据集概述
基本信息
- 许可证: CC-BY-NC-4.0
- 语言: 西班牙语(es)、巴斯克语(eu)
- 标签: Variation
- 数据集名称: xnli_var
数据集结构
配置(configs)
-
eu配置
- original: eu/xnli-eu-original.tsv
- native: eu/xnli-eu-native.tsv
- variation: eu/xnli-eu-var.tsv
-
es配置
- original: es/xnli-es-original.tsv
- native: es/xnli-eu2es-native.tsv
- variation: es/xnli-es-var.tsv
-
other_ablation配置
- Basque_no_repetition: ablation-eu/xnli-native-var-eu-NO-REPETITION.tsv
- Basque_less_western: ablation-eu/xnli-native-var-eu-less-biz.tsv
- Basque_less_central: ablation-eu/xnli-native-var-eu-less-gip.tsv
- Spanish_no_repetition: ablation-es/xnli-native-var-es-no-rep.tsv
-
translations配置
- translations_Basque_native: translations/xnli-eu2en-native.tsv
- translations_Basque_variation: translations/xnli-eu2en-var.tsv
- translation_Spanish_native: translations/xnli-es2en-native.tsv
- translation_Spanish_variation: translations/xnli-es2en-var.tsv
数据集描述
- 来源: 衍生自XNLI数据集,采用相同许可证
- 特点: 手工整理的巴斯克语和西班牙语变体包容性NLI数据集
- 用途: 评估语言技术对巴斯克语和西班牙语变体的理解能力
文件夹结构
- eu: 包含原始XNLI测试数据、原生和变体包容性数据集
- es: 包含原始XNLI测试数据、巴斯克原生数据翻译成西班牙语版本及变体包容性数据
- Translations: 提供原生和变体包容性数据集的自动英语翻译
- ablation-eu: 巴斯克语消融实验数据集
- ablation-es: 西班牙语消融实验数据集
相关资源
- GitHub仓库: https://github.com/hitz-zentroa/XNLIvar
- 论文链接: https://arxiv.org/abs/2506.15239
引用格式
bibtex @inproceedings{bengoetxea-et-al-2025,, title = "Lost in Variation? Evaluating NLI Performance in Basque and Spanish Geographical Variants", author = "Bengoetxea, Jaione and Gonzalez-Dios, Itziar and Agerri, Rodrigo", year = "2025", url = "https://arxiv.org/abs/2506.15239" }
搜集汇总
数据集介绍
构建方式
XNLIvar数据集的构建过程采用了严格的人工标注方法,以确保数据的高质量和多样性。首先,研究团队以XNLIeunative数据集为基础,通过招募来自不同地理区域的母语人士进行方言改写。对于巴斯克语,12位来自不同地区的母语者参与了标注工作,每位标注者负责改写约20个句子,涵盖了西部、中部和纳瓦拉三种主要方言变体。西班牙语部分则通过机器翻译将巴斯克语数据转化为西班牙语后,再由6位来自古巴、厄瓜多尔、西班牙和乌拉圭的母语者进行方言改写。整个标注过程遵循详细的方言改写指南,允许标注者在词汇、语法、语音和拼写等多个层面进行修改,以真实反映各地区的语言变体特征。
使用方法
XNLIvar数据集主要用于评估语言模型在处理语言变体时的性能。研究人员可以通过该数据集进行多种实验设置:1)判别式实验,包括模型迁移(使用英语MNLI训练集微调多语言编码器模型)、翻译训练(使用自动翻译的巴斯克语/西班牙语MNLI训练集)和翻译测试(将目标语言测试集翻译成英语进行评估);2)生成式实验,采用零样本、少样本和思维链(CoT)等提示方法评估大语言模型的表现。数据集还可用于错误分析,如通过计算标准形式与方言变体之间的Levenshtein距离来研究语言距离对模型性能的影响。此外,该数据集也适用于社会语言学研究中关于代际和地域语言差异的分析。
背景与挑战
背景概述
XNLIvar数据集由巴斯克大学HiTZ中心的Jaione Bengoetxea等人于2025年创建,旨在解决自然语言推理(NLI)任务中语言变体理解的难题。该数据集聚焦巴斯克语和西班牙语的地理变体,填补了低资源语言变体数据缺失的空白,为语言技术和语言学研究提供了重要资源。数据集通过专业人工标注构建,包含894个巴斯克语和666个西班牙语实例,覆盖西部、中部巴斯克方言以及古巴、厄瓜多尔等西班牙语变体,其创新性体现在首次系统性地整合了巴斯克语标准化过程中产生的方言差异。
当前挑战
该数据集面临双重挑战:在领域问题层面,需解决语言模型对非标准变体(如巴斯克语西部方言)理解能力显著下降的问题,实验显示变体数据导致模型准确率下降4-10个百分点;在构建层面,需克服低资源语言变体标注的困难,包括巴斯克语方言间形态差异显著(如西部方言与标准语字符编辑距离达70)、西班牙语正字法变异(如/s/音位删除现象)导致的标注复杂度,以及纳瓦拉方言样本不足(仅占7%)带来的数据不平衡问题。
常用场景
经典使用场景
XNLIvar数据集在自然语言推理(NLI)任务中被广泛用于评估语言模型处理巴斯克语和西班牙语地理变体的能力。该数据集通过提供标准语言及其变体的平行语料,为研究语言变异对模型性能的影响提供了重要基准。特别是在跨语言和上下文学习实验中,XNLIvar成为衡量编码器-解码器大语言模型(LLMs)在方言理解方面表现的关键工具。
解决学术问题
XNLIvar解决了语言技术在处理低资源语言(如巴斯克语)及其方言时的性能下降问题。通过实证分析,该数据集揭示了语言变异(而非词汇重叠)是导致模型性能下降的主要原因。此外,它验证了语言学理论中关于边缘方言(如西巴斯克语)与标准形式距离较远的假设,为语言变异处理提供了数据支持。
实际应用
该数据集的实际应用包括改进多语言虚拟助手、方言敏感的机器翻译系统,以及消除语言技术中的方言歧视。例如,在巴斯克地区教育科技中,XNLIvar可优化方言文本的自动评分系统;在西班牙语内容审核场景中,其非标准拼写变体数据能提升社交媒体方言内容的分类鲁棒性。
数据集最近研究
最新研究方向
近年来,XNLIvar数据集在自然语言处理领域引起了广泛关注,特别是在低资源语言和方言变体的研究方面。该数据集通过提供巴斯克语和西班牙语的地理变体,填补了现有研究中方言数据稀缺的空白。前沿研究方向主要集中在跨语言和上下文学习实验中,评估编码器-解码器大型语言模型(LLMs)在处理语言变体时的性能下降问题。研究表明,语言变体本身,而非词汇重叠,是导致性能下降的主要原因。此外,巴斯克语的西方方言由于其与标准形式的较大差异,表现出更显著的性能下降,这与语言学理论中关于外围方言的论述一致。XNLIvar数据集的发布不仅为方言处理研究提供了宝贵资源,也为开发更具语言包容性的NLP技术奠定了基础。
相关研究论文
- 1Lost in Variation? Evaluating NLI Performance in Basque and Spanish Geographical VariantsHiTZ Center - Ixa, University of the Basque Country UPV/EHU · 2025年
以上内容由遇见数据集搜集并总结生成


