biglam/on_the_books
收藏Hugging Face2026-04-30 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/biglam/on_the_books
下载链接
链接失效反馈官方服务:
资源简介:
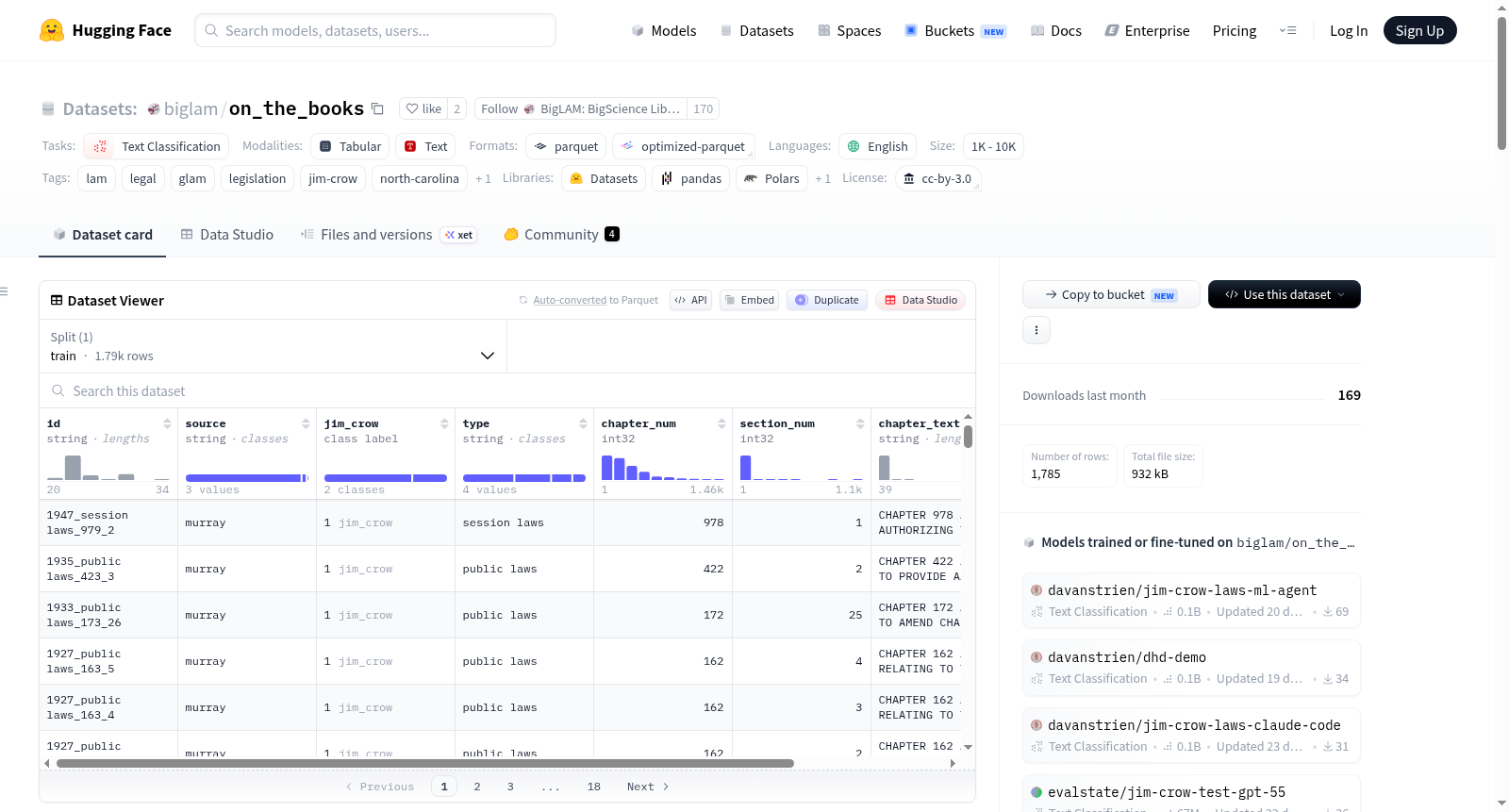
该数据集是来自北卡罗来纳大学教堂山图书馆的“On the Books”项目中的标记训练集,该项目使用机器学习识别重建时期至民权时代(1866-1967年)北卡罗来纳州会议法律中的吉姆·克劳法。每一行代表北卡罗来纳州会议法律中的一个章节/部分对,由专家标记为吉姆·克劳法或非吉姆·克劳法。该数据集用于训练监督分类器,随后应用于整个约一个世纪的法律文本。数据集包含1,785行,其中512行为正类(吉姆·克劳法),1,273行为负类。数据字段包括id、source、jim_crow标签、type、chapter_num、section_num、chapter_text和section_text。数据集的语言为英语(法律/立法文本,带有OCR产生的时期拼写)。
This dataset is the labeled training set from **On the Books**, a collections-as-data project at UNC Chapel Hill Libraries that used machine learning to identify Jim Crow laws within North Carolina session laws passed between Reconstruction and the Civil Rights era (1866–1967). Each row is a chapter/section pair from a North Carolina session law, labeled by experts as either a Jim Crow law or not. The set was used to train a supervised classifier that was then applied to the full ~century of session laws. The dataset contains 1,785 rows, with 512 positive (`jim_crow`) and 1,273 negative examples. Data fields include id, source, jim_crow label, type, chapter_num, section_num, chapter_text, and section_text. The language of the dataset is English (legal/legislative register, with period orthography from OCR).
提供机构:
biglam
原始信息汇总
数据集概述
基本信息
- 名称: On the Books Training Set
- 语言: 英语
- 许可证: CC-BY-3.0
- 大小: 1K<n<10K
- 任务类别: 文本分类
数据集特征
- id: 字符串类型
- source: 字符串类型
- jim_crow: 分类标签,包含两个类别:0: no_jim_crow, 1: jim_crow
- type: 字符串类型
- chapter_num: 整数类型(int32)
- section_num: 整数类型(int32)
- chapter_text: 字符串类型
- section_text: 字符串类型
数据集分割
- 训练集:
- 样本数量: 1785
- 数据大小: 2119395字节
- 下载大小: 944579字节
标签
- lam
- legal
配置
- 默认配置:
- 数据文件路径: data/train-*
搜集汇总
数据集介绍
构建方式
On the Books数据集源自北卡罗来纳大学教堂山分校图书馆的“On the Books”项目,旨在通过机器学习识别1866至1967年间北卡罗来纳州立法中蕴含的吉姆·克劳法。数据集建构历经四个精密步骤:首先,对来自互联网档案馆的扫描卷宗进行OCR数字化处理,采用Tesseract引擎生成文本;其次,将OCR输出细分为章节与条款结构;随后,项目专家依据穆雷和帕斯卡尔汇编的权威吉姆·克劳法列表,对法律文本进行二元标注,同时由项目团队补充大量负样本;最终,该标注集被用于训练监督分类器,并推广至整个世纪的法律语料库,以揭示隐藏的种族隔离立法。这一流程将历史文献学与计算方法深度融合,为计算法律史研究提供了坚实的实验基础。
特点
该数据集的核心特色在于其专业性与领域针对性。它包含1785条经过专家精心标注的章节-条款对,涵盖512条正样本(吉姆·克劳法)与1273条负样本,类别不平衡程度约为29%正例。数据字段丰富多元,除法律文本外,还记录法律类型(如公共法、私法)、章节编号及标注来源(项目专家、穆雷、帕斯卡尔)。尤为独特的是,正样本完全源自两位权威学者的历史汇编,保证了标签的历史准确性;而负样本则主要由项目团队依据对法律内容的详细审查确定,体现了严谨的档案学方法。数据还包含OCR时代特有的文本噪声,真实再现了历史法律文献的原始形态。
使用方法
该数据集最适宜用于训练和评估面向历史法律语言的文本分类模型,亦可在容忍OCR错误的文本分类基准测试中发挥重要作用。用户可通过Hugging Face的datasets库便捷加载,直接获取训练集及所有字段。在模型构建时,建议针对类别不平衡问题调整损失函数或采样策略,并注意标注来源字段可能泄露标签信息,不宜单独作为特征使用。由于数据仅涵盖北卡罗来纳州的特定历史时期,应用范围需限定于同质语域,跨地域或跨时期迁移时需谨慎。研究者可将其用于数字人文教学、计算法律史探索,及文化遗产领域的机器学习方法演示。
背景与挑战
背景概述
《On the Books》数据集由北卡罗来纳大学教堂山分校图书馆的研究团队于2020年左右创建,核心成员包括Frank Baumgartner、Megan Winget与Hannah Jacobs。该数据集聚焦于利用机器学习方法识别美国重建时期至民权时代(1866–1967年)北卡罗来纳州法律中的吉姆·克劳法,旨在通过计算手段揭示历史立法中的种族歧视条款,为计算法律史与数字人文研究提供了开创性资源。数据集包含1,785条经过专家标注的法律章节-条目对,其中约29%被标记为吉姆·克劳法,其发布对法律文本分类、历史语言处理及文化遗产数据科学领域产生了重要影响,成为相关研究的基准与教学范例。
当前挑战
该数据集面临的核心领域挑战在于历史法律文本的复杂分类问题:吉姆·克劳法常以隐晦或间接的歧视性措辞呈现,需结合历史语境与社会结构知识进行判别,而非简单的关键词匹配。构建过程中的挑战包括:对19世纪末至20世纪初印刷品的光学字符识别(OCR)产生的噪声干扰文本质量;专家标注来源的歧义性(如部分标签源自Pauli Murray等二手编译文献),导致负面类未必完全代表非歧视性法律;类别不平衡(正负样本比约1:2.5)及来源与标签间的混杂偏差(如帕斯卡尔来源全部为正类),需谨慎处理以规避信息泄露与模型泛化风险。
常用场景
经典使用场景
在计算法律史与数字人文学科的交汇领域,on_the_books数据集为历史法律文本的二分类任务提供了珍贵资源。该数据集以美国北卡罗来纳州1866年至1967年间通过的州议会法律为素材,聚焦于识别其中蕴含的吉姆·克劳种族隔离法规。研究人员可基于该数据集训练监督学习分类器,利用章节和条款级别的OCR文本,区分法律条文是否属于系统性种族歧视的法律体现。数据集精心标注了1785条样本,包含正负类别,为探索立法语言中的偏见模式奠定了坚实基础。其经典用途在于构建可泛化的文本分类模型,以揭示历史法律文本中隐晦或不为人知的歧视性条款。
实际应用
在实际应用中,on_the_books数据集及其衍生的分类模型已直接服务于历史档案的数字策展和公共教育领域。北卡罗来纳大学教堂山图书馆的On the Books项目利用该数据集训练的模型,对长达一个世纪的议会法律进行全景扫描,生成了机器识别的吉姆·克劳法律子集,这一成果已通过DOI形式公开发布。图书馆、档案馆和博物馆可利用此类工具自动化标引馆藏历史法律文献,提升资源可发现性。在高等教育中,该数据集被广泛用作数字人文、图书馆数据科学和文化遗产机器学习课程的教学素材。社会正义倡导者也可借助这一资源揭示系统性种族歧视的历史轨迹,为当代政策反思提供实证支撑。
衍生相关工作
on_the_books数据集催生了一系列关联性学术工作,形成了以计算法律史为核心的衍生研究生态。项目团队基于此数据集开发的开源代码库和完整训练流程已成为相关领域的基础设施。数据库专家在此基础上探索了OCR噪声环境下法律文本的鲁棒分类方法,推动了历史文档分析技术的发展。学者们进一步借鉴该数据集的标注策略,将专家编纂的歧视性法律汇编(如Pauli Murray的《各州种族与肤色法律》)转化为结构化的机器学习训练集,拓展了吉姆·克劳法律在其他州的识别研究。该数据集还促进了法律语言学与种族研究的交叉对话,启发了后续关于法律术语、修辞与种族隔离制度之间关联的计算分析,形成了数字人文学科中数据集构建与文化遗产保护相结合的重要范例。
以上内容由遇见数据集搜集并总结生成


