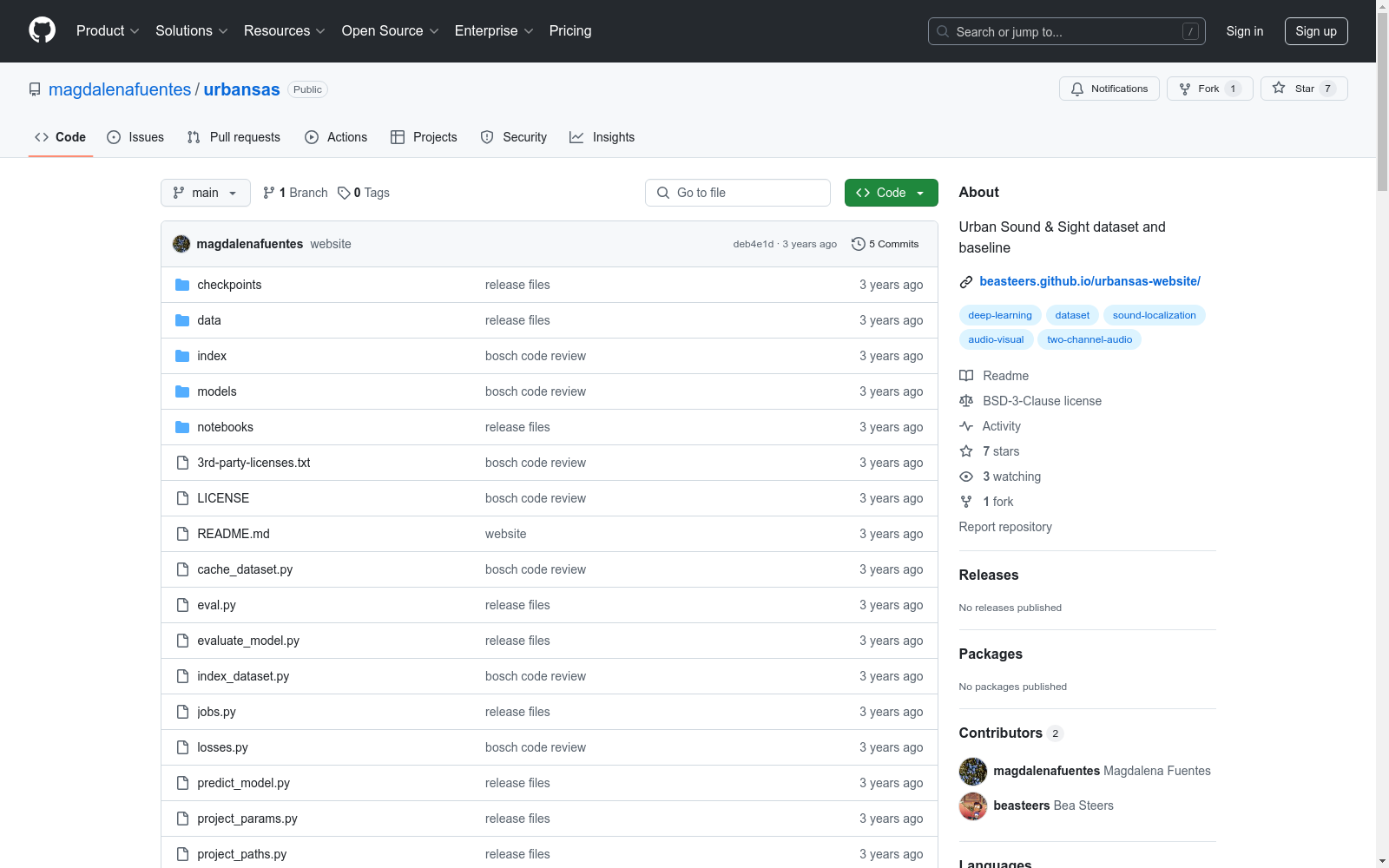
Urbansas
收藏数据集概述
数据集名称
- Urbansas Baseline
数据集下载
数据集结构
- 数据集应包含以下文件夹:
annotations/,audio/,video_2fps/。
数据集设置
-
创建数据索引:
- 使用命令
python index_dataset.py --datasets Urbansas生成包含文件及其地面实况标签的JSON文件。 - 确认
index/文件夹中存在Urbansas.json文件。
- 使用命令
-
缓存数据集:
- 运行
python cache_dataset.py以缓存用于训练的数据集格式。
- 运行
模型训练
- 使用
train_model.py脚本进行模型训练,支持点源模型和框模型。 - 示例命令: bash python train_model.py --train_dataset Urbansas --val_dataset Urbansas --train_folds 1 2 3 4 --val_folds 0 --config_name urbansas_f0_point_sources --point_sources --filter_confirmed
预测与评估
-
预测:
- 使用
predict_model.py脚本进行预测。 - 示例命令: bash python predict_model.py --config_name urbansas_f0_point_sources --folds 0 --point_sources --filter_confirmed
- 使用
-
评估:
- 使用
evaluate_model.py脚本评估模型性能。 - 示例命令: bash python evaluate_model.py --config_name urbansas_f0_point_sources --point_sources
- 使用
结果可视化
- 使用
jupyter lab notebooks/results.ipynb和jupyter lab notebooks/viz.ipynb进行结果分析和可视化。
引用信息
-
引用论文:
"Urban sound & sight: Dataset and benchmark for audio-visual urban scene understanding." Fuentes, M., Steers, B., Zinemanas, P., Rocamora, M., Bondi, L., Wilkins, J., Shi, Q., Hou, Y., Das, S., Serra, X. and Bello, J.P., in IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2022.
-
引用格式:
@inproceedings{urbansas_2022, title={Urban sound & sight: Dataset and benchmark for audio-visual urban scene understanding}, author={Fuentes, Magdalena and Steers, Bea and Zinemanas, Pablo and Rocamora, Mart{\i}n and Bondi, Luca and Wilkins, Julia and Shi, Qianyi and Hou, Yao and Das, Samarjit and Serra, Xavier and others}, booktitle={ICASSP 2022-2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP)}, pages={141--145}, year={2022}, organization={IEEE} }
-