bilingual_children_speech
收藏Hugging Face2026-05-10 更新2026-05-11 收录
下载链接:
https://huggingface.co/datasets/nimuezorro/bilingual_children_speech
下载链接
链接失效反馈官方服务:
资源简介:
双语儿童语音数据集是一个用于文本分类任务的数据集,特别关注于从儿童的英语语音模式预测其第一语言。数据集基于Kaggle的双语儿童语音语料库,提取了儿童的英语话语、第一语言(L1)、儿童ID和年龄信息,并将其整理为适合监督学习中长文本块的形式。数据集包含两种配置:原始配置仅包含来自CHILDES/Paradis语料库的原始话语;平衡配置则在原始数据基础上,为代表性不足的L1群体添加了由ChatGPT生成的合成话语。数据收集于2002年加拿大埃德蒙顿,25名以英语为第二语言的儿童参与了访谈,涵盖了多种话题。数据集包含的L1语言有:波斯语、阿拉伯语、粤语、西班牙语、普通话、韩语、乌克兰语、日语和罗马尼亚语。该数据集适用于研究和教育目的,尤其适合学术文本分类任务。
The Bilingual Child Speech Dataset is a dataset for text classification tasks, specifically focused on predicting childrens first language from their English speech patterns. Based on Kaggles Bilingual Child Speech Corpus, it extracts childrens English utterances, first language (L1), child ID, and age information, and organizes them into a format suitable for supervised learning with long text chunks. The dataset includes two configurations: the original configuration contains only raw utterances from the CHILDES/Paradis corpus, while the balanced configuration adds synthetic utterances generated by ChatGPT for underrepresented L1 groups. Data was collected in 2002 in Edmonton, Canada, with 25 children who speak English as a second language participating in interviews covering various topics. The L1 languages included are: Persian, Arabic, Cantonese, Spanish, Mandarin, Korean, Ukrainian, Japanese, and Romanian. This dataset is suitable for research and educational purposes, particularly for academic text classification tasks.
创建时间:
2026-05-07
原始信息汇总
双语儿童语音数据集概述
数据集基本信息
- 数据集名称:Bilingual Children Speech Dataset
- 语言:英语
- 任务类型:文本分类(多类分类)
- 数据规模:1,000 < n < 10,000
- 标签:儿童语言、双语、语言学、母语识别、合成数据
数据集来源
数据集来源于以下两个主要来源:
原始数据于2002年在加拿大埃德蒙顿收集,25名学习英语作为第二语言的儿童参与了访谈,话题涉及年龄、喜爱的食物、上学情况等。
数据集特征
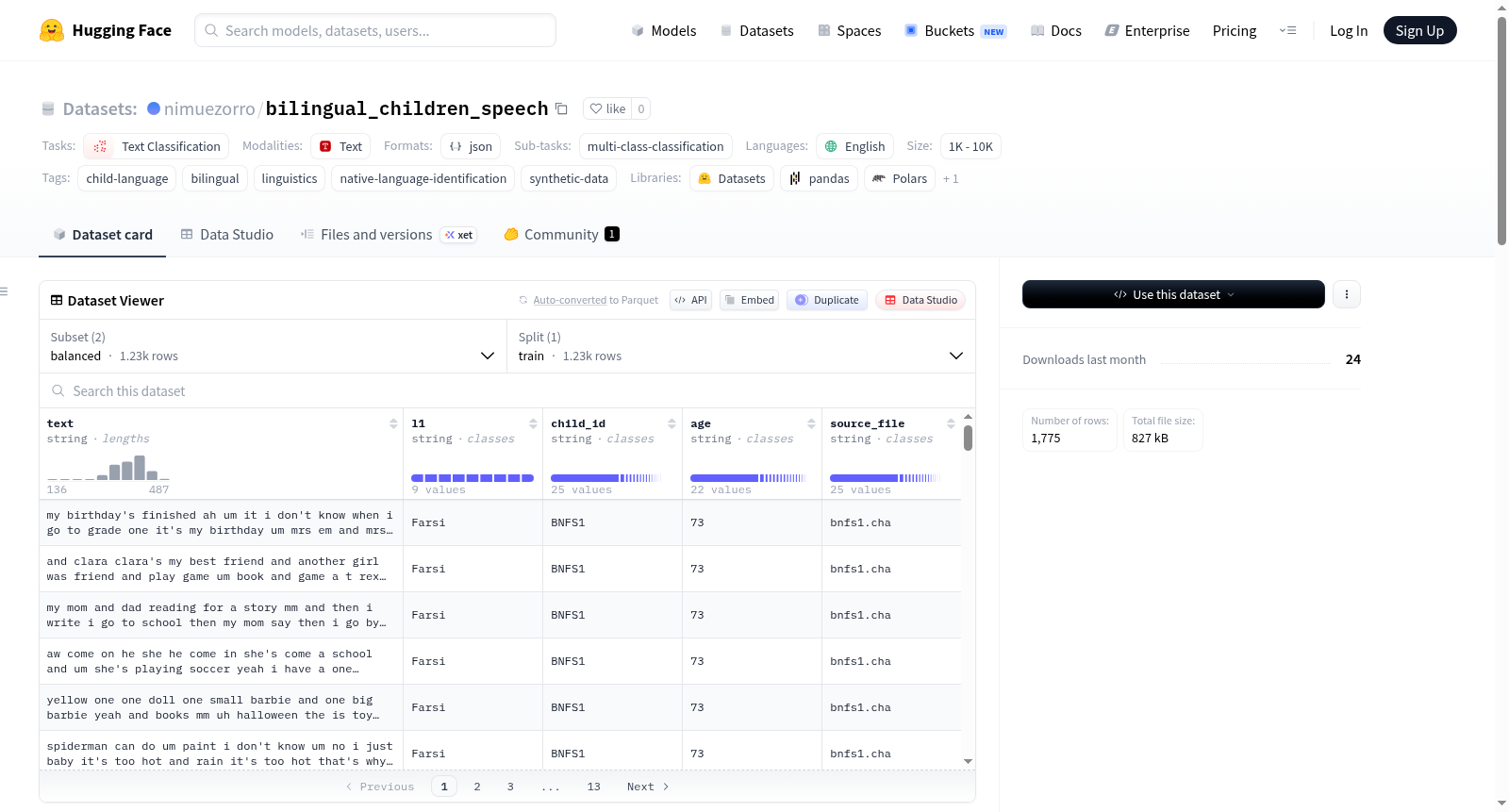
每条数据包含以下字段:
| 字段名 | 类型 | 说明 |
|---|---|---|
| text | 字符串 | 儿童英语话语文本 |
| l1 | 字符串 | 儿童的第一语言 |
| child_id | 字符串 | 儿童唯一标识 |
| age | 字符串 | 儿童年龄 |
| source_file | 字符串 | 源文件名 |
可用配置
original(原始版本)
- 数据文件:
childes_l1_dataset.jsonl - 仅包含来自原始CHILDES/Paradis语料库的话语
balanced(平衡版本)
- 数据文件:
childes_l1_dataset_balanced.jsonl - 包含原始数据以及通过ChatGPT生成的合成数据,用于平衡各L1组别的样本数量
- 合成数据的
child_id、age和source_file字段均标记为synthetic
包含的第一语言类别
- Farsi(波斯语)
- Arabic(阿拉伯语)
- Cantonese(粤语)
- Spanish(西班牙语)
- Mandarin(普通话)
- Korean(韩语)
- Ukrainian(乌克兰语)
- Japanese(日语)
- Romanian(罗马尼亚语)
数据用途
- 该数据集专为学术文本分类任务创建,目标是根据英语语音模式预测儿童的第一语言(母语识别)
- 数据集规模较小,主要用于研究和教育目的,不适合生产系统
数据示例
json { "text": "my birthdays finished ah um it i dont know when i go to grade one its my birthday um mrs em and mrs bee um two of them yes i like everything but i just i dont like blocks i dont like it everybody fight with blocks nobody giving that to me nobody giving that to her and they say doesnt want to give me blocks um paint and house and school and paint and draw", "l1": "Farsi", "child_id": "BNFS1", "age": "73", "source_file": "bnfs1.cha" }
搜集汇总
数据集介绍
构建方式
该数据集源自Kaggle上收录的双语儿童语音语料库,原始数据采集自2002年加拿大埃德蒙顿25名以英语为第二语言的儿童访谈。为适配监督学习任务,研究者通过脚本提取目标儿童的英语话语,将其重组为中等长度的文本片段,并保留母语类型、儿童标识符和年龄等关键字段。针对原始语料中不同母语群体样本分布不平衡的问题,借助ChatGPT合成少数母语类别的扩充语句,生成均衡版本的数据集,合成样本均标注'synthetic'标签以示区分。
特点
数据集包含波斯语、阿拉伯语、粤语、西班牙语、普通话、韩语、乌克兰语、日语和罗马尼亚语九种母语背景的儿童英语语料,样本规模介于千条至万条之间。每个样本由英语文本、儿童母语标签、匿名化儿童编号、年龄及来源文件标识构成。原始配置保持语料自然性,均衡配置则通过合成技术弥补数据偏斜,形成兼具真实对话与人工生成的混合语料。数据集小巧精致,专为学术文本分类任务设计,聚焦于从儿童英语话语模式预测其第一语言。
使用方法
数据集提供'original'和'balanced'两种配置,可灵活调用。原始配置适合评估模型在真实对话语料上的表现,均衡配置则适配类别平衡训练需求。数据格式为JSON Lines,每行包含text、l1、child_id、age和source_file字段。使用时需注意合成数据的局限性,避免在生成式任务中过度依赖。该数据集主要面向语言学与机器学习的交叉研究,适用于母语识别、语言习得分析等教育或学术场景,不推荐直接部署至生产系统。
背景与挑战
背景概述
双语言儿童语音数据集(Bilingual Children Speech Dataset)构建于2002年,源自加拿大埃德蒙顿的CHILDES/Paradis语料库,由Johanne Paradis等研究人员主导采集。该数据集聚焦于25名以英语为第二语言的学龄前儿童,通过访谈收集其英语自然话语,旨在探究儿童第一语言(L1)对英语语音模式的影响。其核心研究问题在于从儿童英语表达中自动识别母语背景,为语言学与计算语言学的交叉领域提供了新颖视角。该数据集不仅推动了多语言儿童语言习得的研究,还通过平衡原始不平衡数据并引入合成样本,为小样本多分类任务(如母语识别)贡献了重要资源,在学术分类实验与教育应用中展现出显著潜力。
当前挑战
该数据集面临多重挑战。在领域问题层面,母语识别任务需从有限的儿童英语话语中捕捉细微的跨语言迁移特征,而儿童语言的不稳定性与创造性表达加剧了模式提取的难度,尤其在9种不同L1间实现高精度分类充满挑战。在构建过程中,原始数据存在严重不平衡,如Farsi与Arabic样本远多于Korean或Romanian,这促使采用ChatGPT生成合成数据以增强代表性,但合成数据可能引入人工痕迹与语义偏差,需谨慎处理。此外,访谈语境的非结构化特性导致话语长度不一,数据清洗与标准化流程需兼顾自然性与机器学习适配性,确保语料真实反映儿童语言风貌而不失可用性。
常用场景
经典使用场景
在儿童语言习得与双语发展研究领域,bilingual_children_speech数据集为探究第二语言学习者母语对英语口语模式的影响提供了珍贵的语料资源。该数据集收录了25名在加拿大埃德蒙顿学习的英语作为第二语言的儿童在访谈中的自然话语,涵盖了波斯语、阿拉伯语、粤语、西班牙语等九种母语背景。最常见的应用场景是多类别文本分类任务,通过分析儿童英语话语中的句法结构、词汇选择和语序特征,训练模型识别其第一语言。该数据集因其规模适中且带有清晰标注,成为验证跨语言迁移理论、研究母语语音及语法迁移现象的经典测试基准。
解决学术问题
该数据集直面语言习得研究中一个核心难题:如何从第二语言学习者的口语输出中量化母语的影响。通过提供标准化的儿童英语话语文本及其对应的母语标签,它解决了跨语言影响研究中语料难以获取、标注不一致的痛点。学术界利用该数据集开展了母语识别任务,验证了即使在学习者早期英语表达中,母语特征也能作为显著的区分信号。这一研究推动了计算语言学与心理语言学的交叉融合,为理解双语儿童的语言认知机制提供了实证支持,并引发了关于语言迁移在不同母语群体中表现异同的深入探讨。
衍生相关工作
围绕bilingual_children_speech数据集,衍生了一系列富有影响力的研究工作。最经典的当属基于该数据进行的母语识别基准实验,其中使用支持向量机、循环神经网络及预训练语言模型进行对比,揭示了不同模型对儿童口语短文本的建模能力差异。此外,研究者利用该数据集分析了母语对语法错误类型的影响,以及与CHILDES语料库中其他语言数据集联合进行的多语种迁移学习实验。合成语料生成策略本身也成为数据增强领域的一个参考案例,启发了后续研究如何利用大语言模型为低资源语言习得任务创造高质量的标注样本。
以上内容由遇见数据集搜集并总结生成


