gim
收藏Hugging Face2026-05-19 更新2026-05-20 收录
下载链接:
https://huggingface.co/datasets/facebook/gim
下载链接
链接失效反馈官方服务:
资源简介:
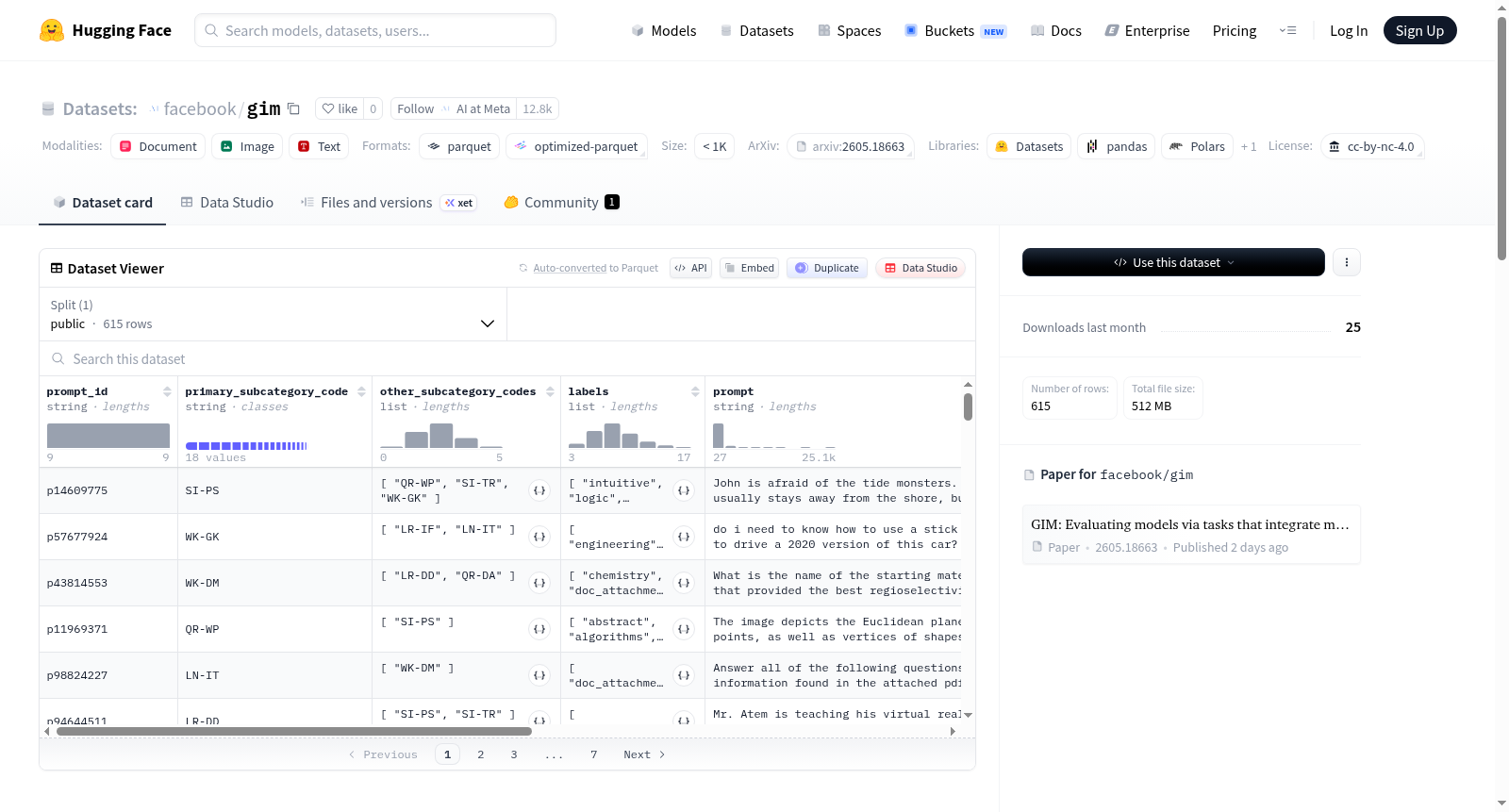
Grounded Integration Measure (GIM) 是一个用于评估大语言模型(LLMs)的基准测试数据集。它旨在克服现有基准测试的不足,如过度依赖记忆知识或完全抽象推理脱离实际。GIM通过“整合”机制提高难度,包含820个由专家撰写的原创问题(其中615个公开,205个私有),每个问题要求模型协调多种认知操作,包括约束满足、状态跟踪、认知警惕和受众校准,并基于广泛可获取(非专业领域)的知识进行推理,确保评估在现实任务背景下进行。数据集提供详细的评分规则(中位数为6个独立评判标准),采用公开-私有分割设计,并内置数据污染诊断机制。此外,研究团队基于超过20万个提示-响应对,在28个模型上校准了连续响应的2参数逻辑(2PL)项目反应理论(IRT)模型,以生成可靠的能力估计,即使在原始准确率失真时也能正确排序测试配置。该数据集用于生成涵盖22个模型和47个测试配置的综合排行榜,并研究测试计算资源(如思维令牌数量)与模型能力的权衡关系。发布内容包括完整的评估框架、校准后的IRT参数及所有公开问题。
Grounded Integration Measure (GIM) is a benchmark dataset for evaluating large language models (LLMs). It aims to address the limitations of current benchmarks, which either overly rely on memorized knowledge or engage in abstract reasoning detached from reality. GIMs core innovation lies in increasing difficulty through integration—the dataset includes 820 original, expert-written problems (615 public, 205 private), each requiring models to coordinate multiple cognitive operations (such as constraint satisfaction, state tracking, cognitive vigilance, and audience calibration) and reason based on widely accessible (rather than specialized) knowledge, keeping evaluations grounded in real-world tasks. Most problems come with detailed scoring rubrics decomposed by criteria (median of 6 independent criteria). The dataset features a public-private split design with built-in diagnostic mechanisms for detecting data contamination. For more robust ability estimation, the research team calibrated a continuous-response 2-parameter logistic (2PL) item response theory (IRT) model on over 200,000 prompt-response pairs across 28 models. This framework generates reliable ability estimates, correctly ordering different test configurations even when raw accuracy is distorted by errors or missing data. The dataset is used to produce comprehensive leaderboards covering 22 models and 47 test configurations (unique model × reasoning level pairs) and to investigate trade-offs between test-time computational resources (e.g., number of thought tokens) and model ability on fixed benchmarks. Released materials include the full evaluation framework, calibrated IRT parameters, and all public problems.
提供机构:
AI at Meta创建时间:
2026-05-05
原始信息汇总
数据集概述
- 数据集名称:Grounded Integration Measure (GIM)
- 发布方:Facebook(Meta)
- 许可证:CC-BY-NC-4.0(非商业用途)
- 数据集类型:评估大语言模型(LLM)的多领域集成推理基准测试集
核心设计理念
GIM 基准测试旨在解决现有 LLM 评测中两种常见倾向的不足:
- 一方面,避免通过增加专业知识门槛(如 GPQA、HLE)来提升难度,防止将记忆与能力混淆;
- 另一方面,不采用脱离实际情境的纯抽象推理(如 ARC-AGI),而是基于广泛可及的常识知识,要求模型在现实任务中协调多种认知操作。
难度来源于 多认知域集成(Integration),而非孤立的专业知识或抽象逻辑。
数据构成
- 总题数:820 道原创题目
- 公开集:615 道(public)
- 私有集:205 道(private)
- 评分方式:多数题目采用分项评分(rubric-decomposed scoring),中位数为 6 个独立评判标准。
- 知识范围:基于广泛可及的常识知识,不依赖特定领域专长。
评估框架
- IRT 模型:基于超过 20 万条提示-响应对,对 28 个模型进行连续响应 2 参数逻辑(2PL)IRT 模型标定,生成稳健的能力估计值。
- 抗污染设计:通过平衡的公开-私有划分,提供内建的数据污染诊断机制。
- 评测规模:
- 涵盖 22 个模型和 47 种测试配置(模型 × 思考层级的组合)
- 对 11 个模型进行 35 种配置的测试时计算量扫描(test-time compute trade-off 研究)
发布内容
- 评估框架
- 标定后的 IRT 参数
- 所有公开问题
关键发现
- 在同一模型家族内,配置选择(如思考预算、量化方式)对性能的影响与模型选择本身相当。
- 增加思考 token 的边际收益递减。
搜集汇总
数据集介绍
构建方式
Grounded Integration Measure(GIM)基准测试集由820个原始问题构成,其中615个为公开问题,205个为私有问题。每个问题均由领域专家精心创作,且大部分采用分解式评分方案,中位数为6个独立评判标准。为增强抗污染能力,数据集采用了平衡的公开与私有划分策略。通过收集超过20万次模型提示-响应对,结合连续响应双参数逻辑斯蒂克(2PL)项目反应理论(IRT)模型进行校准,从而生成稳健的能力估计值,有效修正了原始准确率中因误差或数据缺失导致的偏差。
特点
GIM的核心特点在于其难度源于多认知领域的整合,而非单纯的知识记忆或抽象推理。每个问题均要求协调多种认知操作,如约束满足、状态追踪、认知警觉和受众校准,且仅基于广泛可及的知识,确保推理扎根于现实任务。此外,数据集提供了综合排行榜,涵盖22个模型和47种测试配置(独特的模型×思维层次组合),并开展了迄今为止最广泛的计算时间与模型能力权衡研究,揭示了家族内配置(如思维预算与量化)与模型选择同等重要,而增加思维令牌的边际收益逐渐递减。
使用方法
研究者可通过HuggingFace页面下载公开的Parquet格式数据文件,并利用提供的评估框架和校准后的IRT参数进行模型评估。建议按预定义的公共与私有划分加载数据,以进行污染诊断。通过运行官方GitHub仓库中的评估脚本,用户可提交模型输出并获取标准化能力评分。对于私有问题,需遵循论文中的使用协议以确保基准的公正性。此外,可利用IRT参数对原始准确率进行校正,获得更可靠的能力估计,从而在排行榜上比较不同模型与配置的表现。
背景与挑战
背景概述
GIM(Grounded Integration Measure)数据集由Facebook Research团队于2025年创建,旨在解决大语言模型评估中基准测试饱和的困境。传统评估策略或依赖领域知识(如GPQA、HLE)而混淆记忆与能力,或剥离知识进行纯粹抽象推理(如ARC-AGI),使推理脱离实际语境。该数据集另辟蹊径,提出通过整合多重认知操作来提升难度,涵盖约束满足、状态跟踪、认知警觉及听众校准等维度,所有问题均基于广泛可及的知识构建,确保推理扎根于现实任务而无需专业壁垒。其820个原创问题以专家深度创作、基于评分标准的细致分解及公私拆分设计,为模型能力评估提供了抗污染与强鲁棒性的新范式,对推动语言模型评测从粗放式准确性向精细化认知整合度演进具有标杆意义。
当前挑战
GIM数据集的核心挑战在于破解现有基准测试中能力评估与任务复杂性之间的失衡。领域问题层面,传统评测难以区分模型是否真正整合了推理要素,而非依赖记忆或浅层模式匹配;该数据集通过要求模型同时协调多项认知操作,从根本上提升了评估的生态效度,促使开发者关注跨维度协同能力。构建过程中,设计者面临多重挑战:确保每个问题对知识的依赖度广泛而公平,避免偏向特定领域或模型预训练分布;创作足以反映认知整合但难度适中的原创问题,防止测试退化为简单知识检索;以及开发连续IRT模型以校准不同模型在噪声响应下的真实能力排序。这些问题共同构成了GIM对评估方法论与实践生成的双重考验。
常用场景
经典使用场景
GIM(Grounded Integration Measure)数据集的核心设计理念在于评估大语言模型对多认知域整合的能力,而非单纯考察知识储备或抽象推理。该数据集包含820道原创题目,每道题都需要模型同时协调约束满足、状态追踪、认识警觉和受众校准等多种认知操作,且所有知识均为广泛可及的常识,从而排除专业壁垒对评估的干扰。其典型使用场景包括:作为传统基准测试(如GPQA、ARC-AGI)的补充工具,用于揭示模型在复杂、真实任务中的综合表现;通过题目内置的评分量规(每道题平均6个独立性评价标准)精细评估模型的推理深度与稳定性;借助公开与私有题目的分割设计,有效检测数据污染对评估结果的影响。研究者可利用GIM对模型进行细粒度的能力剖析,尤其适合探索不同模型在认知整合任务上的瓶颈与优势,从而引导更贴近人类认知模式的语言模型发展。
解决学术问题
GIM数据集的提出旨在解决当前大语言模型评估领域的两大核心困境:一是传统基准测试(如GPQA)过度依赖专业领域知识,导致记忆能力与真实推理能力混淆;二是抽象推理基准(如ARC-AGI)脱离实际应用场景,使得评估结果难以反映模型在现实任务中的表现。GIM通过构建需要多认知域协作的原创问题,将评估焦点从单一维度转向整合能力,从而更精准地刻画模型的综合智能水平。该数据集还应对了基准测试中常见的数据污染和评分偏差问题,采用项目反应理论(IRT)模型对超过20万组提示-响应数据进行校准,提供鲁棒的能力估计值,即使原始准确率因误差或缺失数据而失真,仍能正确排序模型配置。这一方法为建立更科学、更透明的模型评估框架提供了范式参考,推动了评估标准从简单准确率比较向精细认知能力分析演进。
衍生相关工作
GIM数据集的发布催生了一系列相关研究工作,主要集中在三个方面。其一,基于其多认知域整合的评估框架,研究人员开发了面向特定领域的能力诊断工具,例如将GIM的约束满足和状态追踪模块迁移至法律合同分析或医疗诊断推理任务中,构建垂直领域的整合评估基准。其二,受GIM中IRT校准方法的启发,后续工作进一步探索了更高效的项目反应理论模型变体,用于处理大规模、多标准评估数据,并推广至其他基准测试如MMLU和BIG-Bench的鲁棒性分析。其三,GIM关于思考预算与模型能力之间递减边际效益的发现,直接推动了自适应推理时间分配算法的研究,例如通过动态调整模型的推理深度以平衡准确率与计算成本,相关成果已在低资源设备上的语言模型部署中得到应用。这些衍生工作不仅验证了GIM评估范式的有效性,也展现了其作为方法论基础在更广泛人工智能研究中的影响力。
以上内容由遇见数据集搜集并总结生成


