frames-benchmark
收藏Hugging Face2024-09-19 更新2024-12-12 收录
下载链接:
https://huggingface.co/datasets/google/frames-benchmark
下载链接
链接失效反馈官方服务:
资源简介:
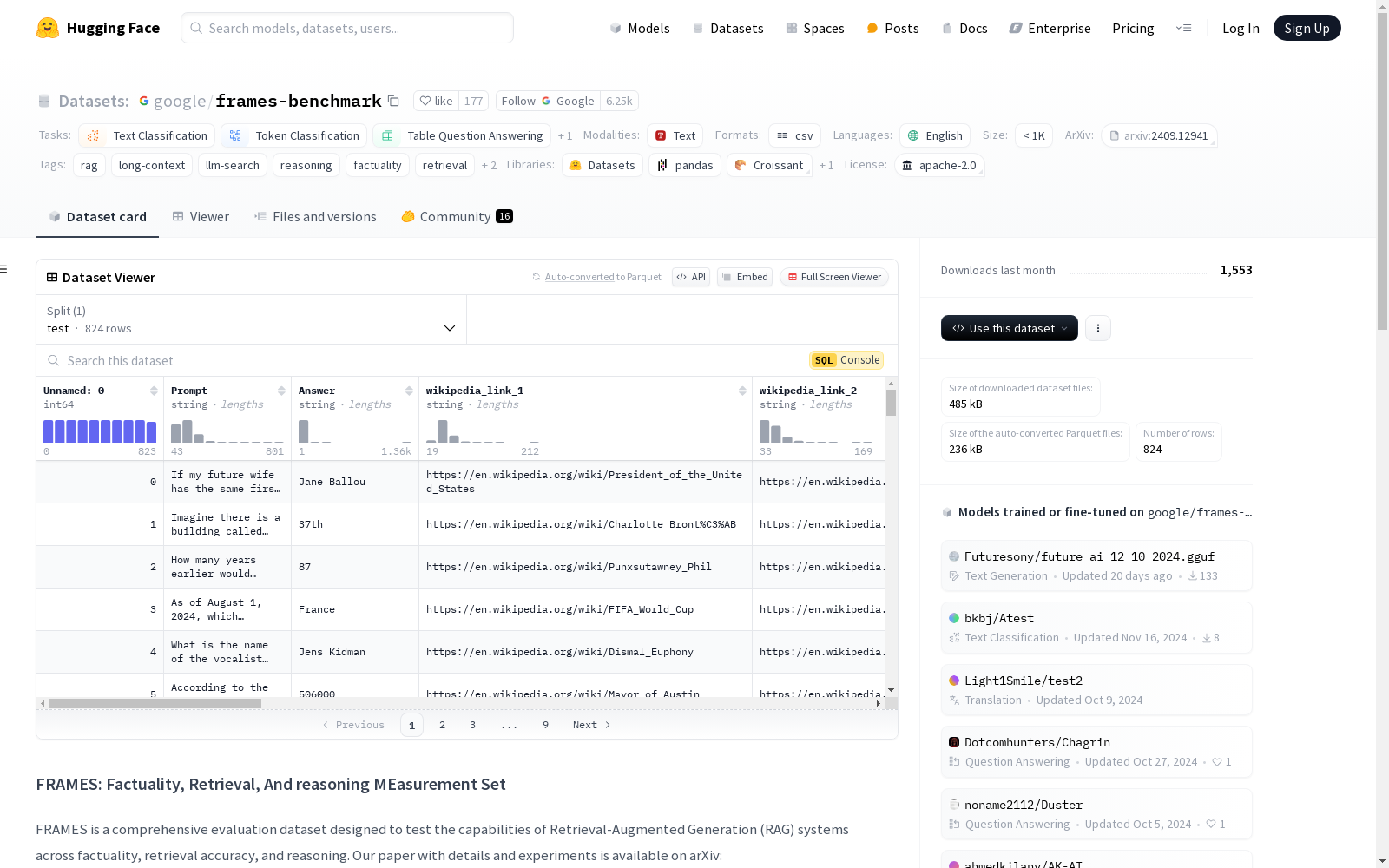
FRAMES数据集是一个综合评估数据集,旨在测试检索增强生成(RAG)系统在事实性、检索准确性和推理方面的能力。该数据集包含824个具有挑战性的多跳问题,这些问题需要从2到15篇维基百科文章中获取信息。问题涵盖了历史、体育、科学、动物、健康等多个主题,并且每个问题都标有推理类型,如数值、表格、多重约束、时间性和后处理。数据集还提供了每个问题的黄金答案和相关的维基百科文章。FRAMES数据集的主要特点包括测试端到端的RAG能力、需要整合来自多个来源的信息、包含复杂的推理和时间性消歧,并设计为对最先进的语言模型具有挑战性。该数据集可用于评估RAG系统性能、基准测试语言模型的事实性和推理能力,以及开发和测试多跳检索策略。
The FRAMES dataset is a comprehensive evaluation dataset designed to test the capabilities of retrieval-augmented generation (RAG) systems in terms of factuality, retrieval accuracy, and reasoning. This dataset includes 824 challenging multi-hop questions that require information retrieved from 2 to 15 Wikipedia articles. The questions cover multiple topics such as history, sports, science, animals, and health, and each question is annotated with reasoning types including numerical, tabular, multi-constraint, temporal, and post-processing. The dataset also provides the gold standard answers and the associated Wikipedia articles for every question. Key features of the FRAMES dataset are as follows: it evaluates end-to-end RAG capabilities, requires integrating information from multiple sources, contains complex reasoning and temporal disambiguation, and is designed to be challenging for state-of-the-art language models. This dataset can be used to evaluate RAG system performance, benchmark the factuality and reasoning abilities of language models, as well as develop and test multi-hop retrieval strategies.
提供机构:
Google
创建时间:
2024-09-19
搜集汇总
数据集介绍
构建方式
FRAMES数据集的构建基于多跳问答任务,涵盖了从2到15篇维基百科文章中提取信息的824个复杂问题。这些问题跨越了历史、体育、科学、动物、健康等多个领域,每个问题都标注了推理类型,如数值推理、表格推理、多重约束推理、时间推理和后处理推理。此外,每个问题都提供了标准答案和相关的维基百科文章,确保了数据集的全面性和挑战性。
特点
FRAMES数据集的特点在于其全面评估了检索增强生成(RAG)系统在事实性、检索准确性和推理能力方面的表现。数据集不仅要求模型整合多个来源的信息,还涉及复杂的推理和时间消歧任务,旨在挑战当前最先进的语言模型。通过多跳问题和多样化的推理类型,FRAMES为RAG系统提供了一个统一的评估框架。
使用方法
FRAMES数据集可用于评估RAG系统的性能,特别是在事实性和推理能力方面的表现。研究人员可以利用该数据集进行多跳检索策略的开发和测试,同时也可以将其作为基准来比较不同语言模型的表现。通过提供基线结果,FRAMES为研究者提供了一个明确的起点,帮助他们更好地理解和改进RAG系统的能力。
背景与挑战
背景概述
FRAMES数据集由Satyapriya Krishna等人于2024年创建,旨在全面评估检索增强生成(RAG)系统在事实性、检索准确性和推理能力方面的表现。该数据集包含824个复杂的多跳问题,这些问题需要从2到15篇维基百科文章中提取信息,涵盖历史、体育、科学、动物、健康等多个领域。每个问题都标注了推理类型,如数值推理、表格推理、多重约束推理、时间推理和后处理推理。FRAMES的推出为RAG系统的性能评估提供了统一的框架,推动了语言模型在复杂推理和信息整合方面的研究。
当前挑战
FRAMES数据集在解决多跳问答和复杂推理任务时面临诸多挑战。首先,多跳问题要求模型能够从多个来源整合信息,这对检索系统的准确性和语言模型的推理能力提出了极高的要求。其次,数据集中的问题涉及多种推理类型,模型需要具备跨领域的知识整合能力。此外,时间推理和多重约束推理进一步增加了问题的复杂性,要求模型能够处理时间序列和多重条件约束。在构建过程中,研究人员还需确保数据集的多样性和代表性,以覆盖广泛的领域和推理类型,这对数据收集和标注工作提出了巨大挑战。
常用场景
经典使用场景
FRAMES数据集在检索增强生成(RAG)系统的评估中扮演着关键角色。该数据集通过设计复杂的多跳问题,要求模型从多个维基百科文章中整合信息,从而测试模型在事实性、检索准确性和推理能力上的表现。研究人员可以利用FRAMES来评估和优化RAG系统在不同任务中的性能,尤其是在需要跨文档推理的场景中。
衍生相关工作
FRAMES数据集催生了一系列关于检索增强生成系统的研究。例如,基于该数据集的研究工作探索了多步检索和推理策略的优化,显著提升了模型在复杂问答任务中的表现。此外,该数据集还启发了对语言模型事实性验证的新方法,推动了领域内对模型可靠性和透明性的深入探讨。
数据集最近研究
最新研究方向
在自然语言处理领域,FRAMES数据集为检索增强生成(RAG)系统的评估提供了全新的视角。该数据集通过设计包含多跳推理、事实性验证和复杂检索的挑战性问题,推动了语言模型在信息整合和推理能力上的研究。当前的研究热点集中在如何通过多步检索和推理策略提升模型在复杂问题上的表现,尤其是在涉及时间序列和多约束条件的场景中。FRAMES的出现不仅为RAG系统的性能评估提供了标准化基准,还为开发更高效的多源信息整合方法提供了实验平台,进一步推动了语言模型在事实性和推理能力上的突破。
以上内容由遇见数据集搜集并总结生成


